



시작하며
얼굴 인식 기술(face recognition)은 지난 수십 년간 컴퓨터 비전(computer vision)의 주요 연구 분야 중 하나로 자리매김하고 있습니다. [그림 1]처럼 시스템에 입력된 두 이미지 속 인물 간의 동일인 여부를 검증(verification)하거나, 이미지 속 인물이 내부 데이터베이스(DB)에 미리 저장된 인물 중 누구와 가장 유사한지를 식별(identification)하는 데 이 기술이 널리 활용되고 있습니다.

다만 얼굴 인식 모델의 훈련 또는 추론 단계에서 사진 속 얼굴 위치가 제각기 다르거나 그 촬영 각도가 다르면 얼굴 인식 정확도가 낮아질 수 있습니다. 따라서 사진에서 얼굴 영역을 찾아 동일한 형태의 정면 얼굴을 추출하는 전처리 과정이 선행되어야 합니다. 일반적인 전처리 과정은 다음과 같습니다. 1) 시스템에 입력된 이미지에서 얼굴 영역을 찾아(face detection, 얼굴 검출), 2) 눈과 코 등 얼굴의 특징을 나타내는 점을 찾습니다(face alignment, 얼굴 정렬1). 3) 이 특징점을 이용해 얼굴 영역을 동일한 형태와 크기로 변경합니다(normalization, 정규화2).

얼굴 인식 모델은 수만 명에 달하는 인물로부터 획득한 수백만 장의 정규화된 얼굴 이미지로부터 인물을 잘 구분하는 함축된 얼굴 표현(facial representation)인 특징 벡터(feature vector)를 학습합니다. 그 결과, 최종 얼굴 인식 모델은 입력된 이미지의 특징 벡터 간 유사도(similarity)를 비교하는 방식으로 검증 또는 식별을 수행할 수 있게 됩니다.
카카오엔터프라이즈 AI Lab(이하 AI Lab) 또한 이 얼굴 인식과 관련해 다양한 연구를 진행하고 있습니다. 최근에는 AI Lab(김용현, 노명철, 신종주)이 카카오(박원표)와 공동으로 쓴 논문인 ‘GroupFace : Learning Latent Groups and Constructing Group-based Representations for Face Recognition(이하 GroupFace)’[1]이 컴퓨터 비전 및 패턴 인식 컨퍼런스(CVPR) 2020에 게재 승인되는 성과를 거두기도 했죠. 이번 글에서는 딥러닝 기반 얼굴 인식 선행 연구를 간단하게 살펴보고자 합니다.
☛ Tech Ground 데모 페이지 바로 가기 : 얼굴 검출 데모
얼굴 인식 모델의 손실 함수 연구 트렌드
딥러닝 모델의 훈련(가중치 업데이트) 과정은 다음과 같습니다([그림 3]). 먼저 순전파(forward propagation)3 과정에서 데이터를 입력받은 모델은 무작위로 초기화된 가중치를 이용해 예측값을 출력합니다. 그다음, 예측값과 정답 사이의 차이를 정의하는 손실 함수를 이용해 입력에 대한 손실(loss)을 계산합니다. 다음으로, 출력층에서 입력층으로 거슬러 올라가는 역전파(backward propagation)4 과정에서 최적화 알고리즘은 기울기(gradient) 값을 이용해 앞서 구한 손실을 최소화하는 방향으로 모델의 가중치 값을 수정합니다. 딥러닝 모델은 이 과정을 여러 번 반복해서 데이터를 점진적으로 학습하게 됩니다.
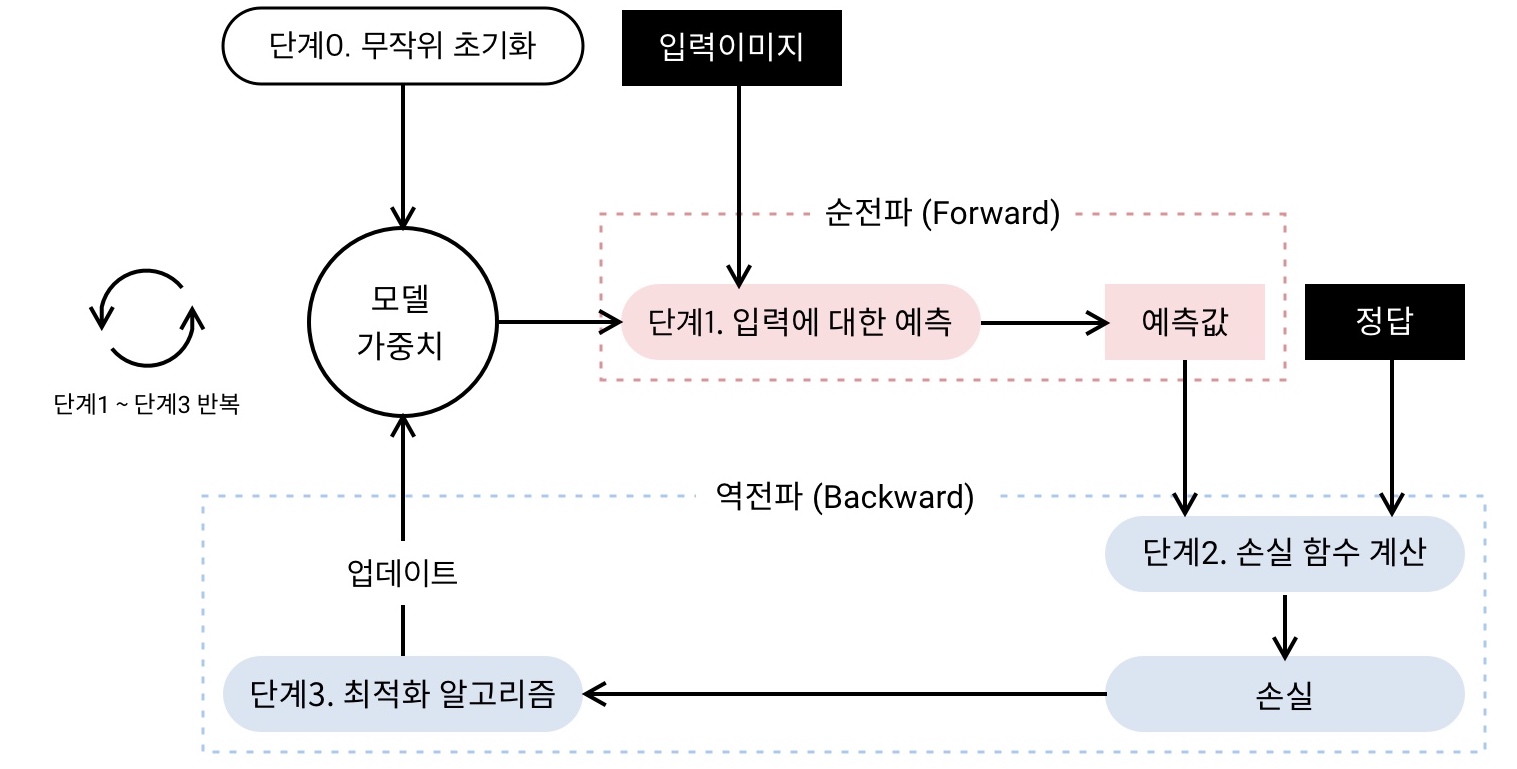
얼굴 인식을 학습하기 위한 손실 함수는 소프트맥스 손실 함수(softmax loss function), 거리 기반 손실 함수(distance-based loss function), 앵귤러 마진 기반 손실 함수(angular margin based loss function) 등 크게 세 종류[2]로 나눠볼 수 있습니다. 이제부터 이 손실 함수를 하나씩 알아보겠습니다.
1. 소프트맥스 손실 함수
일반 객체 분류 모델인 AlexNet과 ResNet, 그리고 초창기 얼굴 인식 모델인 DeepFace, DeepID의 마지막 출력층은 전(前) 단계에서 추출된 특징 벡터를 N개의 범주로 분류하기 위해 배치된 완전연결층(fully-connected layer)과 소프트맥스(softmax) 함수5 로 구성돼 있습니다. 이후 교차 엔트로피(cross entropy)가 소프트맥스 확률 분포와 정답 분포 사이 오차를 계산합니다. 소프트맥스 확률값을 이용한다는 점에서 이 손실 함수를 소프트맥스 손실 함수라고도 부릅니다.
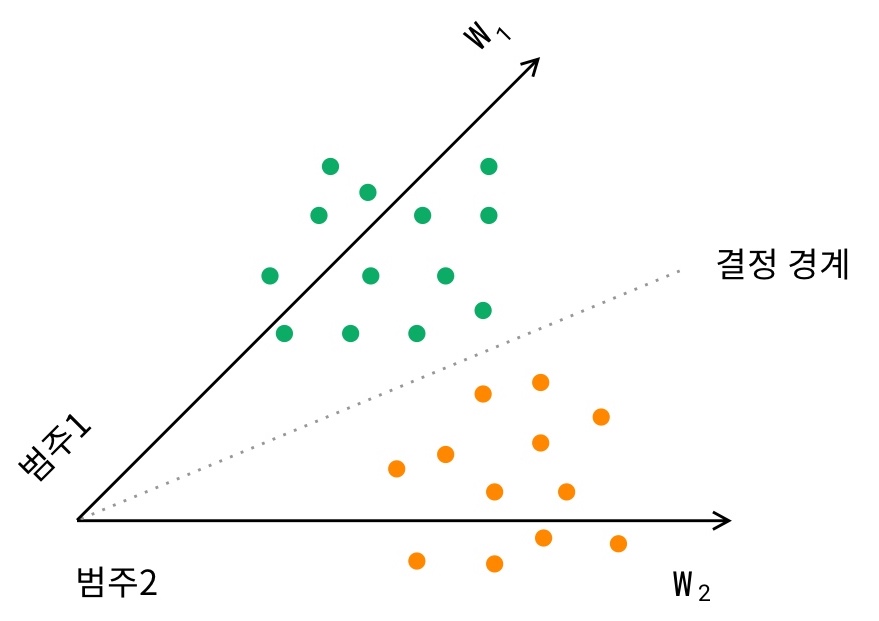
소프트맥스 손실 값을 최소화하는 학습을 통해 모델은 특징 공간(feature space)에 동일인의 두 특징 벡터(intra-class)를 더 가깝게, 비동일인의 두 특징 벡터(inter-class)는 더 멀게 표현할 수 있게 됩니다. 하지만 단순히 소프트맥스 함수만을 사용한 손실 함수로는 수만 명에 달하는 인물의 특징 공간을 효율적으로 학습하기가 어렵습니다. 전체적인 최적화를 고려하지 못하고 국부적인 최적 지점(local minimum)으로 쉽게 수렴할 수 있기 때문입니다. 이로 인해 추론 단계에서 마주하는 학습하지 않은 새로운 얼굴 이미지의 인식 성능은 낮을 수 있습니다.
2. 거리 기반 손실 함수
거리 기반의 손실 함수 또한 앞서 설명한 소프트맥스 손실 함수처럼 특징 공간에 동일인의 두 특징 벡터를 더 가깝게, 비동일인의 두 특징 벡터는 더 멀게 표현하는 학습에 활용됩니다. 차이점은 특징 벡터 간의 거리를 학습에 직접 활용하는 부분입니다. 대표적인 거리 기반 손실 함수인 대비(contrastive) 손실 함수와 트리플렛(triplet) 손실 함수를 통해 그 작동 원리에 대해 좀 더 자세히 소개해드리겠습니다.

대비 손실 함수는 두 얼굴 이미지의 쌍을 구성해 두 특징 벡터 간의 거리를 계산합니다. 여기서 손실 값은 동일인의 두 벡터 간 거리가 멀면 커지고, 반대로 비동일인의 두 벡터간 거리가 가까우면 커집니다. 이에 모델은 이 손실 값을 최소화하는 학습을 통해 동일인에 해당하는 두 벡터를 가깝게, 비동일인의 두 벡터를 더 멀게 표현할 수 있게 됩니다.
하지만 이런 손실 계산 방식에는 한계가 있습니다. 동일인에 해당하는 두 벡터 거리와 비동일인의 두 벡터 거리가 개별적으로 학습되기 때문입니다. 즉, 동일인 간의 벡터 거리가 비동일인 사이 벡터 거리보다 상대적으로 가까워져야 함을 고려하지 못하는 거죠.
트리플렛 손실 함수는 범주가 같은 벡터 간의 거리와 범주가 다른 벡터 간의 거리의 상대적 관계를 고려하는 방식으로 이 문제를 해결합니다. 먼저, 기준이 되는 이미지 a, 동일인 이미지 p, 그리고 비동일인 이미지 n으로 구성된 트리플렛(a, p, n)을 구성합니다. 트리플렛 손실 함수는 a와 p의 벡터 간 거리를 줄이는 동시에, a와 n의 벡터 간 거리를 넓힙니다. 즉, 두 거리의 차(|a-n| - |a-p|)가 개발자가 임의로 정한 마진값보다 크도록 합니다. 그 결과, 트리플렛 손실 함수로 학습된 인식 모델은 대비 손실 함수와 비교했을 때 더 높은 추론 성능을 보이는 경향이 있습니다.
다만 지난 2017년을 기점으로 얼굴 인식 관련 딥러닝 모델에서는 거리 기반 손실 함수를 잘 사용하지 않는 추세입니다. 트리플렛을 구성하는 방식에 따라 성능이 크게 달라지기 때문입니다. 특히 범주 수가 많을수록 효과적인 트리플렛을 구성하기도 쉽지 않습니다. 많은 방법이 고안되었음에도, 얼굴 인식처럼 분류해야 할 범주가 많은 상황에서는 효과적인 트리플렛을 구성하는 데는 여전히 어려움이 있습니다.
아울러 컴퓨팅 비용도 상대적으로 더 많이 소모됩니다. 일반적으로 이 손실 함수는 범주의 수가 수십~수백개 수준일 때 효과적으로 동작하나, 수천 개 이상의 범주가 존재할 때는 잘 동작하지 않습니다. 기존 대비 2~4배 이상 배치 크기(batch size)6를 키움으로써 성능 저하를 일부 극복할 수 있지만, 수만 명에 달하는 인물을 다루어야 하는 얼굴 인식 모델에서는 그 역시 쉽지 않은 일입니다.
3. 앵귤러 마진 기반 손실 함수
SphereFace에서 CosFace와 ArcFace로 이어지는 근래의 얼굴 인식 연구는 앵귤러 마진을 추가한 소프트맥스 기반 손실 함수를 이용해 서로 다른 인물 간 거리를 충분히 넓히는 방향으로 진행되고 있습니다.

충분히 큰 한정된 공간이 있다고 가정해 보겠습니다. 학습 시 다른 범주를 1의 간격으로 분포하게 만들어도 분류는 완벽하게 이뤄집니다. 여기에 더 나아가, 다른 범주를 10의 간격으로 두고 데이터 분포를 훈련한다면 어떻게 될까요? 학습 난이도는 높을지라도 공간을 효율적으로 사용할 수 있어, 모델의 일반화(generalization)7 성능이 높다고 기대해볼 수 있겠습니다. 여기서는 이러한 간격을 특징 벡터 간의 각도에 적용하였다는 점에서 앵귤러 마진이라는 이름이 붙었습니다.
한계점
이처럼 손실 함수가 새롭게 제안되고 있음에도 불구하고, 얼굴 인식 모델에게 서로 다른 인물의 얼굴을 구분하는 최적의 특징 공간을 생성하는 방법을 가르치기는 여전히 쉽지 않습니다. AI Lab은 기존 대부분의 손실 함수에 대한 얼굴 인식 연구로는 수만 명의 얼굴을 구분하는 충분한 효과를 기대하기가 어렵다고 판단했습니다. AlexNet, VGGNet, ResNet처럼 수십에서 수천 개의 범주를 분류하는 데 최적화된 범용 모델을 그대로 사용해서는 수만 명의 얼굴을 효과적으로 처리하는 데 적합하지 않다고 본 거죠.
선행 연구가 최대 수만 개의 범주를 효과적으로 분류하려는 목적에서 새로운 손실 함수를 도입했듯이, AI Lab은 이를 위한 특별한 인식 모델 구조를 고민했습니다.
AI Lab은 인간의 얼굴에 각자 고유의 특징이 있으면서도, 동시에 공통적인 특징을 가지고 있다는 점을 면밀히 관찰했습니다. 실제로 얼굴의 공통적인 특징을 모아 보는 그룹화 개념은 현실에서도 누군가를 특정하는 데 유용한 기법으로 활용되고 있습니다. 예를 들어, 검은 머리와 붉은 수염을 가진 남자와 같이 주된 특징을 조합한 몽타주 표현처럼 말이죠.
최종적으로 AI Lab은 얼굴의 유사성을 그룹화해 표현하는 특징 벡터(group-aware representation)를 추출하는 새로운 모델 구조인 GroupFace를 제안했습니다. GroupFace는 다양한 얼굴 인식 모델에 적용 가능합니다. 얼굴 인식 분야 대표적인 9개 공개 데이터셋을 상대로 테스트를 진행해본 결과, GroupFace는 모든 데이터셋에 대해 얼굴 인식 성능을 높였습니다. 특히 IJB 벤치마크에서는 그 정확도를 최대 10%P 가까이 끌어올렸습니다.
AI Lab이 새로 고안한 방법론인 GroupFace의 아이디어와 아키텍처, 성능 평가에 관한 자세한 내용은 해당 논문을 확인해 주시기 바랍니다.

참고 문헌
[1] GroupFace : Learning Latent Groups and Constructing Group-based Representations for Face Recognition (2020) by Yonghyun Kim, Wonpyo Park, Myung-Cheol Roh, Jongju Shin in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
[2] Deep Face Recognition: A Survey (2018) by Mei Wang, Weihong Deng in arXiv

이수경(samantha) | 작성, 편집
지난 2016년 3월 알파고와 이세돌 9단이 펼치는 세기의 대결을 취재한 것을 계기로 인공지능 세계에 큰 매력을 느꼈습니다. 카카오엔터프라이즈에서 인공지능을 제대로 알고 싶어하는 사람들을 위해 전문가와 함께 읽기 쉬운 콘텐츠를 쓰고 있습니다. 인공지능을 만드는 사람들의 이야기와 인공지능이 바꿀 미래 사회에 대한 글은 누구보다 쉽고, 재미있게 쓰는 사람이 되고자 합니다.

김용현(aiden) | 작성, 감수
대학원에서 물체 검출 및 얼굴 인식을 연구하고, 현재 카카오엔터프라이즈에서는 얼굴 인식 연구를 담당하고 있습니다.

박원표(tony) | 감수
데이터 사이언스에 관심이 생겨 덜컥 인공지능 관련 석사 과정에 진학했습니다. 카카오에서는 인공지능을 이용한 이미지 처리 연구와 개발을 맡고 있습니다. 이번 생에는 사람만큼 똑똑한 인공지능의 탄생을 꼭 보고 싶습니다.

노명철(joshua) | 감수
카카오엔터프라이즈에서 훌륭한 동료들과 함께 얼굴 인식 관련 기술을 연구∙개발하고 있습니다. 기계의 성능 수치보다는, 사람의 행복 지수를 높이는 인공지능 기술을 만들고 싶습니다.

신종주(isaac) | 감수
대학원에서 얼굴 특징점 검출을 전공한 뒤, 현재는 카카오엔터프라이즈에서 얼굴 영상과 관련된 연구 개발 조직을 맡고 있습니다. 연구 중인 얼굴 인식이 앞으로 제 두 아들이 살아갈 세상에 도움이 되었으면 좋겠습니다.

- 얼굴 위에서 특징점(keypoints)의 형태를 잡아간다는 점에서 착안해 '정렬(alignment)'이라는 표현을 쓴다. 얼굴 특징점 검출(face landmark detection)이라고도 부른다. [본문으로]
- 일부 연구에서는 정규화 단계에서 사진 속 조명을 제거하거나 인물 표정을 같은 식으로 변경하기도 하고, 측면 얼굴을 정면 얼굴로 생성하기도 한다. 하지만 기본적으로 2D 영상의 정규화라고 한다면 오려낸 얼굴을 똑같은 형태로 맞추는 일이다. [본문으로]
- 입력층-은닉층-출력층을 거쳐서 예측값을 내는 방법 [본문으로]
- 출력층-은닉층-입력층으로 거슬러 올라가며 가중치를 업데이트하는 방법 [본문으로]
- 다범주 분류기에서는 출력값을 제대로 해석하고자 다른 출력 노드와의 상대적인 크기를 비교한다. 이를 위해 각 출력 노드를 0~1 사이로 제한해 이를 합한 값을 1로 만든다. [본문으로]
- 한차례의 훈련, 즉 가중치를 한 번 업데이트하는 데 사용하는 훈련 집합의 크기 [본문으로]
- 학습 데이터와 조금이라도 다른 성격의 데이터가 입력되어도 모델이 제대로 동작하는 상태 [본문으로]




댓글