사오정 API - 음악 재생 발화는 내게 맡겨주세요. [기술편]

어렸을 적 즐겨보던 만화 중 ‘날아라 슈퍼보드'라는 만화가 있었습니다. 그 만화에는 무슨 말을 해도 잘 알아듣지 못하는 ‘사오정'이라는 캐릭터가 등장하는데요. 사오정은 가는 귀를 먹어 귀의 주름을 걷고 이야기를 듣지 않으면 이야기를 엉뚱하게 알아들어 많은 해프닝을 만들어 내기도 했습니다.
이렇게 만화 속 사오정처럼 카카오 i도 가끔 명령을 완벽히 알아듣지 못하는 경우가 있죠. 저희는 카카오 i가 무슨 말을 해도 잘 알아들을 수 있도록 “사오정 프로젝트”를 진행했습니다. 만화 속 사오정은 말귀를 못 알아듣는 캐릭터로 등장하지만, 사오정 프로젝트에서의 사오정은 카카오 i 발화의 대부분을 차지하는 음악 재생 발화의 오류를 획기적으로 줄여주는 고마운 캐릭터임을 밝히며 글을 시작하도록 하겠습니다.
#사오정 프로젝트의 탄생 배경
카카오 i에서 가장 많은 발화 유형은 무엇일까요? 바로 음악 재생 발화입니다. 스피커를 통해 음악을 듣기 위한 사용자의 자연스러운 흐름일 것 같습니다. 음악 감상은 카카오 i 뿐만 아니라 스마트 스피커를 사용하는 대부분의 사용자가 이용하는 기능입니다. 2019년 3월 컨슈머인사이트 AI 스피커 리포트에 따르면 AI 서비스를 이용하는 사용자들은 음악 감상을 주 이용 기능으로 사용한다고 합니다.

이 글을 읽고 있는 분들도 듣고 싶은 음악이 있어 카카오 미니를 호출했지만 발화가 제대로 인식되지 않아 원하는 음악이 재생되지 않았던 경험이 있으실 텐데요. 한국어의 경우에는 발화의 자유도가 높은 이유도 있고, 외래어나 축약어를 사용하는 가수명 또는 노래명들이 존재하여 발화가 의도대로 인식되기 어려운 점이 있습니다. 사오정 프로젝트는 이런 어려움을 해결해보고자 시작되었는데요. 저희는 무슨 말을 해도 찰떡같이 알아듣는 카카오 i를 만들기 위해 다양한 기능 중에서도 특히 음악 재생 발화 인식 오류를 줄이는 기능을 개발했습니다.
# 음악 재생 발화 오류 분석
음악 재생 발화는 음악 재생과 관련된 발화로 대부분은 가수명과 노래명이 포함되어 구성됩니다. 예를 들어, ‘아이유의 celebrity 틀어줘’나 ‘방탄소년단의 Dynamite’가 있습니다. 먼저 음악 재생 발화 오류 유형을 분석하여 문제를 파악했습니다.

저희는 먼저 카카오 i의 로그를 분석을 통해 다양한 오류들을 분석했고, 이 중 7가지의 대표적인 재생 발화 유형을 정리했습니다.

저희는 기존 오타교정 자연어 기술을 이용하면, 위에 제시된 인지 오류를 제외한 다른 오류들은 해결이 가능하다고 여겼습니다.
# 사오정 프로젝트 소개
사오정 프로젝트에서 사오정은 음악 재생 발화의 특성을 이용하여 발화를 교정합니다. 대부분의 음악 재생 발화가 가수명과 노래명의 조합으로 이뤄진 것에 착안하여 음악으로 분류된 발화에 대해 가수명과 노래명이 제대로 인식되었는지 판단하고 이를 교정합니다.

[그림 3]은 카카오 i에서 사오정을 통해 음악 재생 발화가 처리되는 과정입니다. 입력된 발화는 먼저 봇 분류기를 통해 음악 봇으로 분류됩니다. 발화에 가수명과 노래명이 태깅되어 있는지를 보고, 오인식으로 인해 가수명 혹은 노래명이 태깅되어 있지 않은 경우에는 가수명 또는 노래명을 추정합니다. 다음으로 후보 검색 모델에서 가수명과 노래명의 오인식 유무를 판단하고, 오인식인 경우에는 교정할 후보를 찾습니다. 마지막 단계로 교정 판별 모델에서 입력과 교정 결과 간의 유사도 자질을 계산하여 가장 적절한 교정 후보를 선택합니다.
# 가수명/노래명 추정 기능
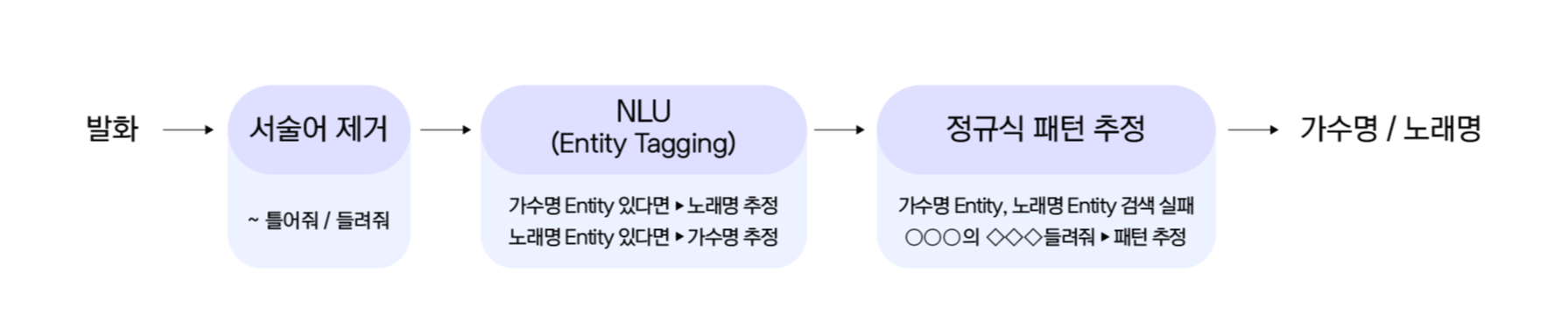
오인식 발화에서 잘못된 가수명이나 노래명을 알아내는 것은 쉽지 않습니다. 그래서 가수명과 노래명을 추정하는 기능이 필요합니다. 첫 번째로 발화에 “들려줘/틀어줘"와 같이 제거해도 되는 서술어 부분을 제거합니다. 다음으로 NLU(Natural Language Understanding, 자연어 이해)의 엔티티 태깅 기능을 이용하여 가수명이나 노래명으로 태깅되는 부분이 있는지 알아봅니다. 가수명이 태깅이 된다면, 가수명을 제외한 부분을 노래명으로 추정하고, 노래명만 태깅되어 있다면 나머지 부분을 가수명으로 추정합니다. 마지막으로 가수명이나 노래명의 단서가 없어서 추정하기 어려운 케이스가 있을 수 있습니다. 이에 대해서는 “{가수명}의 {노래명} 틀어줘"나 “{가수명}이(가) 부른 {노래명} (노래)? 틀어줘"와 같은 정규식 패턴을 이용하여 추정합니다.
# 후보 검색 모델
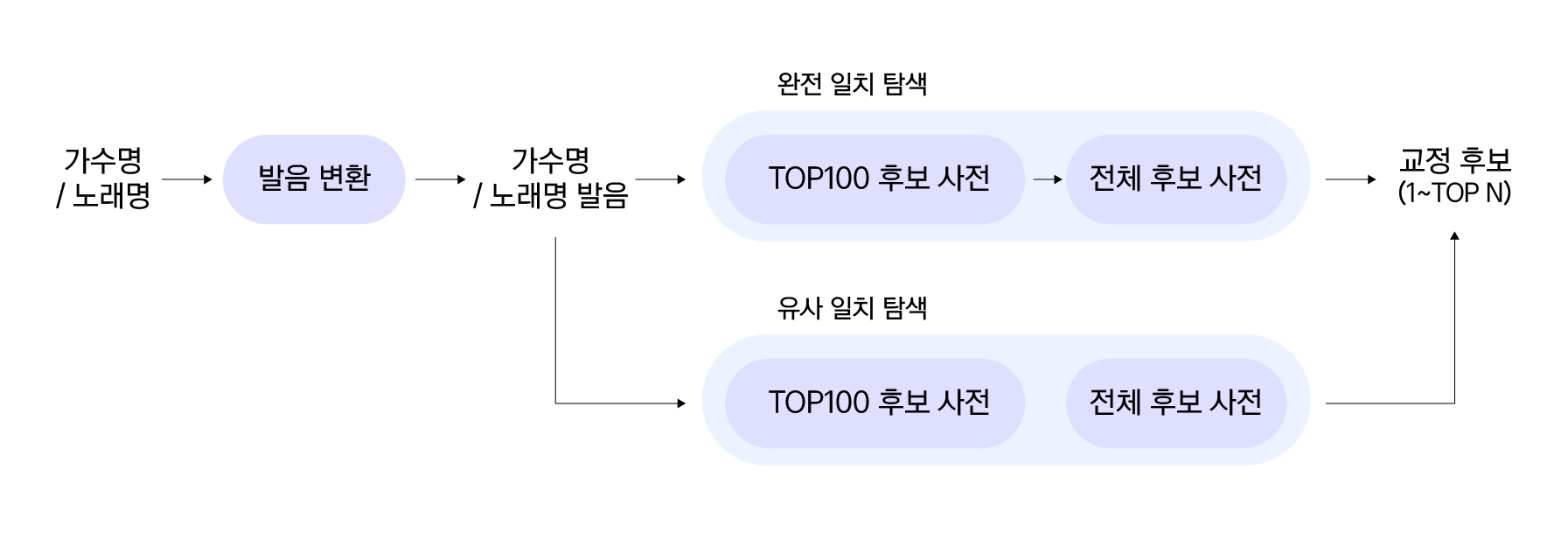
후보 검색 모델은 가수명과 노래명에 대해 교정 후보를 찾습니다. 음악 DB(멜론)로부터 데이터를 가공하여 정답 후보 사전을 만들고, 다양한 유사도 계산 방법을 결합한 ‘음악 유사도(가칭)'를 이용하여 오인식된 입력에 대해 적절한 후보를 검색합니다. 정답 후보 사전은 신곡에 대한 빠른 대응이 필요한 음악 도메인의 특성을 고려하여 TOP100 사전을 별도로 구축하고, 전체 DB에서 구성한 전체 후보 사전을 함께 사용합니다. ‘음악 유사도’는 편집 거리(Damerau Levenshtein Edit distance) 유사도[1], Jaro-Winkler 유사도[2], Overlap 유사도[3]를 균등하게 결합한 것입니다. 각 유사도는 서로를 보완하며 가장 적절한 후보를 찾는 데 사용됩니다.
[그림 5]는 후보 검색 모델의 전체 과정입니다. 가수명과 노래명을 발음열(Phoneme 형태로 나열)로 변환하여 완전 일치 탐색과 유사 일치 탐색을 합니다. 각 탐색은 TOP100 후보 사전과 전체 후보 사전을 순차적으로 탐색합니다. 입력과 동일한 결과가 후보 사전에 있는지 완전 일치 탐색을 하고, 오인식과 유사한 후보를 탐색하기 위해 유사 후보 탐색을 합니다. 이때 ‘음악 유사도'를 통해 유사도를 계산하고 최대 N개의 후보를 출력합니다.
# 교정 판별 모델
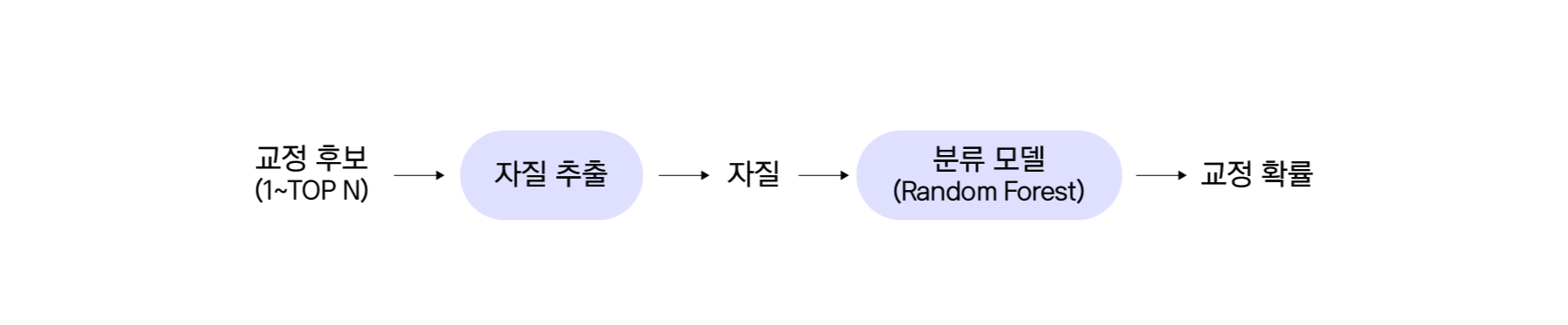
교정 판별 모델은 후보 검색 모델 결과 중에서 신뢰도가 높은 결과를 선택합니다. 후보 검색 모델의 결과에 대해 여러 가지 자질 정보를 계산하여 판별 모델의 자질로 사용합니다. 자질(Features)은 후보 검색 모델에서 사용한 유사도 자질들을 이용합니다. 판별 모델은 Random Forest 모델을 사용(Depth=40, tree=20)합니다. Random Forest 모델은 여러 가지 개별 모델을 결합하여 성능을 향상한 앙상블 모델(Ensemble Model) 중 하나로 의사 결정 나무(Decision Tree)를 개별 모형으로 사용합니다. 최종적으로 교정 판별 모델에서 출력한 결과값이 임계치 이상인 경우 교정 최종 후보로 사용합니다. 그렇지 않을 경우에는 교정하지 않습니다.
# 사오정 적용 이후
음악 도메인에 사오정이 적용되면서 유의미한 지표 변화가 있었습니다. 사오정이 주로 처리하는 ‘가수명 + 노래명'의 경우 실패율이 30% 이상 감소했습니다. 전체 발화의 절반 이상을 차지하는 음악 재생 발화의 실패율이 크게 감소되다보니, 사용자들은 더욱 똑똑해진 헤이카카오를 통해 더 많은 음악 재생 발화했습니다. 결과적으로 카카오 i의 전체 사용률도 향상되었습니다. 또한, 신곡에 대한 충분한 리소스(동의어 등)가 확보되기 전에는 TOP100 후보 사전을 통해 사용자 발화를 처리하여 만족도를 높였습니다.
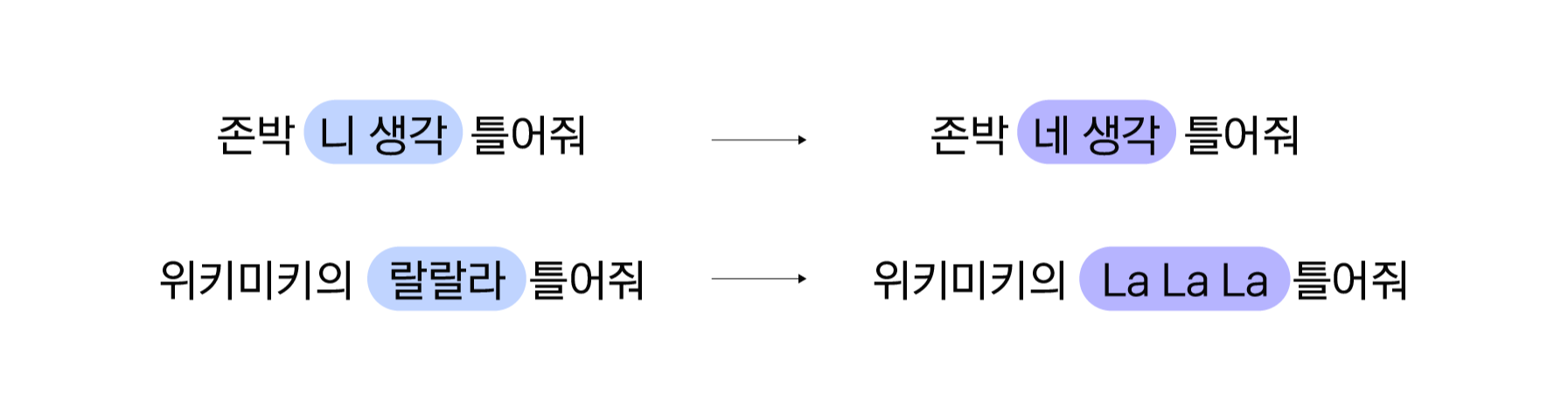
사오정 적용으로 해결된 오류 유형들입니다. 비슷한 발음이나 영어를 한글로 인식하여 발생한 오류에 대해 효과적으로 처리합니다. 예를 들어 '존박 니 생각 틀어줘'를 '존박 네 생각 틀어줘'로 교정하는 경우나 '위키미키의 랄랄라 틀어줘'를 '위키미키의 La La La 틀어줘'로 교정하는 경우입니다.
# 사오정은 발전 중
‘형돈이와 대준이의 왕밤빵'이란 곡을 아시나요? 실제로 이런 노래명은 없지만 한 번쯤 들었을 수 있습니다. 노래의 정식 명칭은 ‘한 번도 안 틀리고 누구도 부르기 어려운 노래’지만 대부분은 ‘왕밤빵'이라는 후렴구를 노래명으로 사용합니다. 사오정에서는 노래 제목처럼 사용되는 후렴구를 처리하는 기능을 추가했습니다. 로그를 분석하여 유의미한 후렴구를 추출하고 노래 제목 대신 후렴구로 요청되는 곡들이 잘 재생될 수 있도록 했습니다.

이 외에도 가수명이 포함된 발화에 이어 앨범명이 포함된 발화도 처리하고 있습니다. 기존에 음악 DB에서 가수에 대한 정보만 추출하던 것을 확장하여 앨범에 대한 정보를 추출하여 사용합니다. 노래 중에는 가수명보다 앨범명을 먼저 떠올리는 경우가 있습니다. 예를 들어 ‘Into the Unknown’이라는 노래는 가수인 ‘Idina Menzel’보다 영화 제목인 ‘겨울왕국’이 먼저 생각납니다. 사오정에서는 ‘겨울왕국 OST의 Into the Unknown 틀어줘'와 같은 발화를 처리할 수 있습니다.
사오정은 본 글을 작성하는 시간에도 계속 발전 중입니다. 앞으로 계속 개선되는 사오정을 기대해주시길 바라며, 글을 마치겠습니다.
이 글이 유익하셨다면, 사오정 프로젝트를 기획자 측면에서 쓴 쉽고 글도 재미있으실 것 같습니다. 아래 링크를 통해 읽어봐주세요. 감사합니다.
📍이 글과 함께 보면 좋아요!
✓ 사오정 API - 음악 재생 발화는 내게 맡겨주세요. [기획편]
참고 문헌
[1] Brill, Eric; Moore, Robert C., An Improved Error Model for Noisy Channel Spelling Correction, Proceedings of the 38th Annual Meeting on Association for Computational Linguistics, pp.286–293, 2000.
[2] Jaro, M. A., Advances in record linkage methodology as applied to the 1985 census of Tampa Florida, Journal of the American Statistical Association, 84(406), 414–420, 1989.
[3] Vijaymeena, M. K.; Kavitha, K, A Survey on Similarity Measures in Text Mining, Machine Learning and Applications: An International Journal. 3(1), pp. 19–28, 2016.

고병일 (Kobi.k)
kakao i가 자연어를 1000% 이해할 수 있도록 노력하고 있습니다. (어?)

이다니엘 (Daniel.e)
데이터 관찰을 좋아하는 자연어처리 개발자로, kakao i가 자연어를 이해하는 데 필요한 기술을 만들고 있습니다.