KorQuAD 2.0 참가기
시작하며
안녕하세요. 카카오엔터프라이즈 AI Assistant 팀 Phil(이민철), John(조승우), Eileen(안애림)입니다. AI Assistant 팀은 흔히 ‘AI 비서’라고 불리는 AI 어시스턴트 구현을 위해 필요한 기술을 연구하고, 서비스로 연결시키는 조직입니다. 자연어 처리(NLP, Natural Language Processing) 기술을 기반으로, 실제 우리 일상을 더욱 편리하게 도와주는 AI 어시스턴트를 개발하고 있습니다.
사람처럼 자연스럽고 똑똑한 AI 어시스턴트를 구현하기 위해서는 대화 처리 기술도 중요하지만, 사용자가 요구하는 질문에 대한 최적의 답을 찾아주는 기계 독해(MRC, Machine Reading Comprehension) 기술이 필수인데요. 여기서 MRC 기술은 쉽게 말해 인공지능(AI)이 스스로 주어진 질문을 분석하고 최적의 답을 찾아내는 기술입니다. 예를 들어 사용자가 “내일모레 제주 날씨가 어때?”라고 질문을 하면 사용자의 의도를 분석하고, 방대한 문서 검색을 통해 적절한 답을 제공해주는 역할을 합니다. 최근에는 365일 24시간 고객에게 쉽고 빠른 상담 서비스를 제공하기 위해, 이러한 기술을 활용한 AI 챗봇 상담 서비스가 다양한 산업에 활용되고 있는데요. 저희 또한 AI 고객센터인 카카오 i 커넥트센터를 통해 상담원을 도와 고객의 만족도를 높이는 챗봇 상담 서비스를 제공하고 있습니다.
오늘 포스팅에서는 지난 3월, 저희 팀이 MRC 기술을 활용해 한국어 기계 독해 평가 KorQuAD 2.0 대회에 참가했던 과정부터 1위를 달성하게 된 소감까지 간략하게 이야기해 드리려고 합니다.
KorQuAD 2.0 소개
KorQuAD(Korean Question Answering Dataset)는 한국어 MRC 질의응답을 연구하는 연구자들이 다량의 학습 데이터를 확보할 수 있도록 LG CNS에서 운영하는 표준 데이터셋입니다. 한국어 위키백과를 대상으로 구축한 대규모 Extractive MRC 데이터를 바탕으로 문제가 출제되며, 제출한 모델이 해당 질문에 어느 정도 수준의 정확도를 나타내는지 코다랩 기반의 리더보드 형태(연구성과 공유의 장)로 제공하고 있는 것이 특징입니다. 표준 데이터셋이 있기 때문에 연구자들은 쉽게 데이터를 확보할 수 있고, 논문 저술이나 학술 활동이 활발하게 이루어지고 있음을 알 수 있습니다.

기술 고도화를 위해 참가한 KorQuAD 2.0은 기존 데이터셋인 1.0에서 업그레이드된 버전인데요. KorQuAD 1.0이 비교적 간단한 텍스트로 이루어진 문단에서 출제되는 형태였다면, KorQuad 2.0은 표나 HTML을 기반으로 하는 텍스트가 출제되어 난이도가 높아졌습니다.
평가는 실제 정답과 예측치가 정확하게 일치하는 비율인 EM(Exact Match), 어절 단위에서 실제 정답과 예측치의 겹치는 부분을 고려한 점수로 HTML tag 제거 후 순수 텍스트끼리 비교하는 F1으로 이루어집니다. 또한 이번 KorQuAD 2.0에서는 1.0과 달리 데이터 전처리, 모델 추론을 포함한 질문 하나당 평균 소요시간까지 측정합니다.
챌린지 1위를 달성하기까지
카카오엔터프라이즈의 LittleBird-Large 모델은 정확도 90.22(F1 스코어 기준)로 1위, LittleBird-Base 모델은 88.57(F1 스코어 기준)로 6위를 차지했습니다. 저희 모델은 특히 타 모델 대비 질문 1개당 평균 소요 시간이 획기적으로 낮고, 정확도 측면에서도 가장 높은 점수를 기록했습니다.
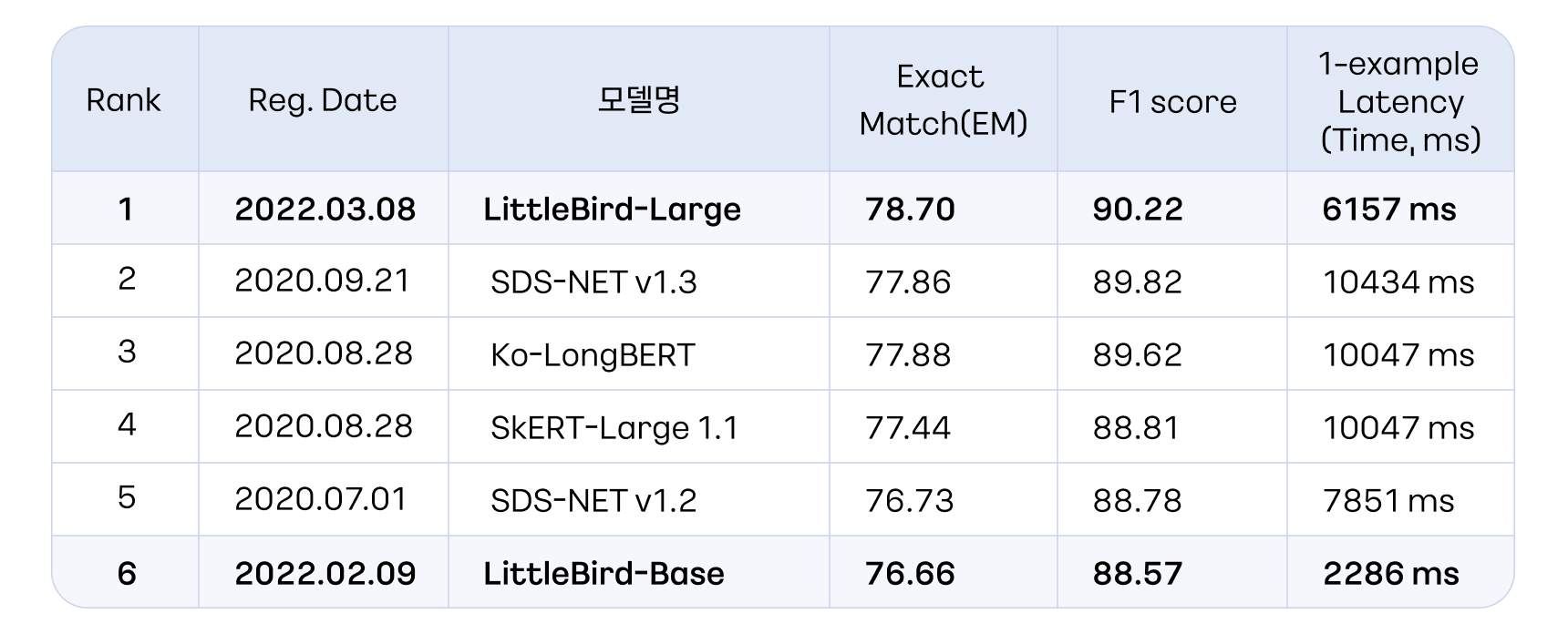

그럼, 위에서 볼 수 있듯, 처리 시간이 짧으면서도 정확도가 높은 괄목할 만한 성과를 낸 LittleBird 모델이 탄생하기까지 어떤 시도들이 있었는지 간략하게 소개하고자 합니다.
첫 번째 모델: ELECTRA MODEL
공식적인 모델을 제출하기에 앞서 기존 KorQuAD1에서 잘 통하던 모델인 ‘ELECTRA’[1] 모델을 기반으로 KorQuAD2를 파인튜닝하였습니다. 이 과정에서 학습 데이터로는 KorQuAD2만 사용하였으며, HTML 문서 중 불필요한 Head와 Tail 부분은 모두 제거하고, 문단/표/리스트를 해석하는데 필수적인 태그를 추가하였습니다.

또한 정답률을 높이기 위해 Balanced Sampling 작업을 추가했습니다. MRC 작업에서 긴 문서를 처리할 때 모델이 인식할 수 있는 크기로 잘라 여러 청크로 나누는 방식을 ‘슬라이딩 윈도우(Sliding Window)’라고 합니다. 슬라이딩 윈도우를 통해 나눈 각 청크 사이에 정답이 존재하여 누락되는 것을 방지하기 위해 약간씩 중첩되게 청크를 나누고 있는데요. 위 기법을 사용했을 시 정답은 한 청크에만 존재하므로 정답이 존재하지 않는 청크가 훨씬 많아지는 것을 알 수 있습니다. 그리고 자연스럽게 모델은 ‘정답 없음’에 편향되는 문제가 발생하게 됩니다. 이를 방지하기 위해 정답이 없는 청크와 있는 청크를 동일한 비율로 샘플링하여 학습에 사용하는 Balanced Sampling 작업을 시도했고, EM과 F1 모두 소폭 상승한 것을 알 수 있었습니다.
두 번째 모델: Splinter
ELECTRA 모델에 이어 QA 태스크에서 좋은 성과를 보이고 있는 모델인 Splinter[2]를 적용했습니다. 단, 기존 Splinter에서는 정답의 시작 지점과 끝 지점을 독립적으로 예측하고 있었는데요. 이는 정답의 끝 지점 위치가 시작 지점 위치와 긴밀한 관련이 있음을 간과하는 한계가 있었습니다. 따라서 시작 지점과 끝 지점을 각각 고려하여 합치는 방법을 개량하여, 먼저 시작 지점을 예측한 뒤 그 시작 지점에 맞는 끝 지점을 다시 예측하는 결합 예측(Joint Prediction) 기법을 사용했습니다. 기존 ELECTRA와 Balanced Sampling 모델에서 PLM을 Splinter로 교체하였고, 결과적으로 EM과 F1 양쪽 모두 크게 개선되었습니다.
그러나 한 청크 내에 못 들어가는 긴 정답이 존재하는 경우는 맞힐 수 없었고, 이를 극복하기 위해 긴 문서를 처리할 수 있는 PLM이 필요했습니다.

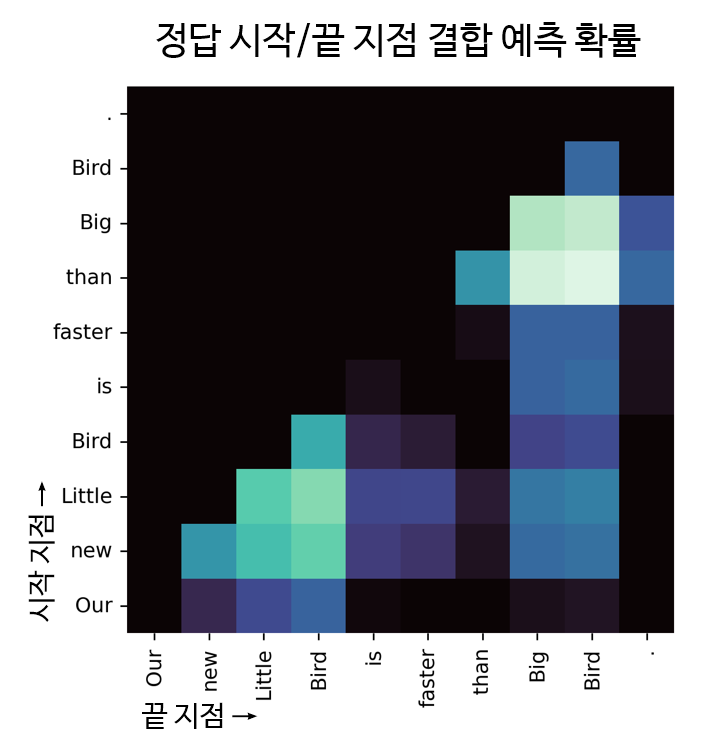
세 번째 모델: LittleBird
세 번째 시도로는 카카오엔터프라이즈가 자체 개발한 LittleBird 모델로, BigBird[3], LUNA[4], ALiBi[5] 모델의 장점을 조합하여 정확도가 높고 효율적으로 긴 문서를 처리할 수 있게 개량한 Transformer 모델을 활용했습니다. 대량의 한국말 말뭉치를 정제해 512 및 1536 토큰 길이의 문서들을 생성했고, 이를 섞어서 PreTraining을 진행했습니다. 학습 과정 중에서는 임의의 위치에 [PAD] 토큰을 여러 개 삽입하는 Length Extension 기법을 적용하여 긴 문서에 대해서도 쉽게 적용할 수 있도록 만들었습니다.
그러나 문서 길이가 길어질수록 Joint Prediction을 적용하기 어려웠습니다. 문서 길이를 l이라고 할 때, 시작 지점과 끝 지점을 각각 예측하는 경우 시작 지점 예측에 O(l), 끝 지점 예측에 O(l)만이 소요됩니다. 그러나 시작 지점의 위치를 고려해 끝 지점을 예측하는 Joint Prediction의 경우, 가능한 (시작 지점, 끝 지점)의 조합은 모두 l*l가지이므로, 연산량은 O(l*l)이 됩니다. 즉, 문서가 길수록 Joint Prediction에 필요한 연산량과 메모리 사용량은 제곱에 비례해 증가하기 때문에 긴 입력에 대해서는 사용하기 어려웠습니다.

이를 해결하기 위해 블록의 사이즈를 잘라 제곱에 비례하는 연산량을 단순화시키는 Blocked Sliding Window를 사용하여 연산량을 축소하였습니다. LittleBird는 입력 길이를 자유롭게 늘릴 수 있어 512를 기준으로 1024, 2048, 4096, 8192까지 증가시키면서 실험을 진행하였습니다.
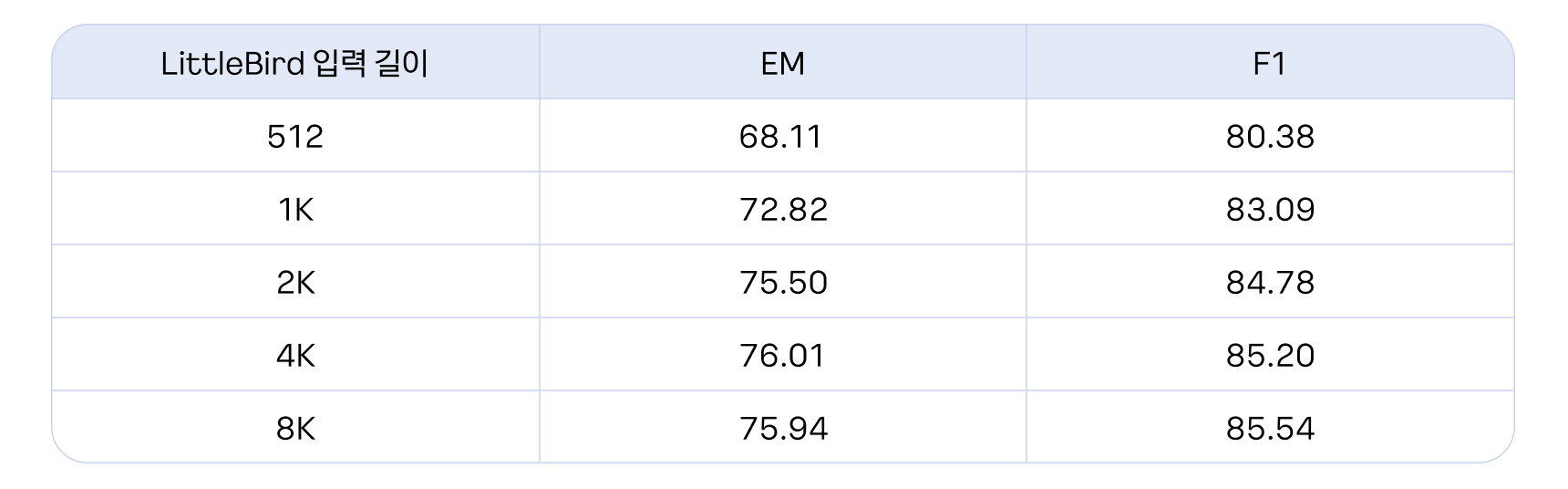
결과적으로 동일 모델로도, 입력 길이를 길게 했을 때 정확도가 큰 폭으로 오르는 것을 알 수 있었습니다. 특히 KorQuAD 2.0의 경우 정답이 1,000글자를 넘어가는 경우도 있기 때문에 긴 입력을 넣는 것이 전체 맥락을 파악하는 데 있어 매우 중요했습니다.
네 번째 모델: LittleBird + 추가 데이터 투입
성능을 높이기 위해 KorQuAD 2.0 데이터셋 외에, 공개된 MRC 데이터와 자체 구축한 MRC 데이터, 마지막으로 증강 데이터를 자동 생성해 투입했습니다. 이때 모든 데이터셋을 학습에 투입하는 경우, KorQuAD 2.0에 대한 정확도를 잃지 않도록 학습에 투입되는 KorQuAD 2.0 데이터가 항상 50% 이상을 유지하도록 샘플링하였습니다. 특히 증강 데이터셋의 경우 사람이 아니라 기계가 만드는 데이터로, 노이즈가 많습니다. 따라서 증강 데이터셋은 전체 데이터셋 비율 중 25%만 차지하도록 샘플링하였고, 나머지 75%는 사람이 직접 구축한 데이터셋으로 구성하였습니다. 최종적으로 점수를 높이기 어려운 고득점 구간에서 1점이나 향상되는 결과를 얻었습니다.
다섯 번째 모델: LittleBird + 추가 데이터 투입 + MATE
KorQuAD 2.0은 텍스트뿐만 아니라 HTML로 구성된 표까지 문제로 출제됩니다. 이를 위해 표에 대한 질의응답을 효율적으로 처리할 수 있는 MATE(MATE: Multi-view Attention for Table Transformer Efficiency)[6] 모델을 활용했습니다. 특히 표에서 가장 효율적으로 정답을 찾을 수 있도록 Attention Head를 두 종류로 나눠 한쪽에서는 동일 행의 Attention만, 다른 쪽에서는 동일 열의 Attention만 수행하도록 샘플링했습니다. KorQuAD 2.0에서도 복잡한 표를 이해하는 게 필수적이므로 MATE의 핵심 아이디어를 HTML 문서에 적용할 수 있도록 개량하여 한국어위키백과와 나무위키를 HTML로 덤프한 말뭉치를 이용해 학습하였습니다.
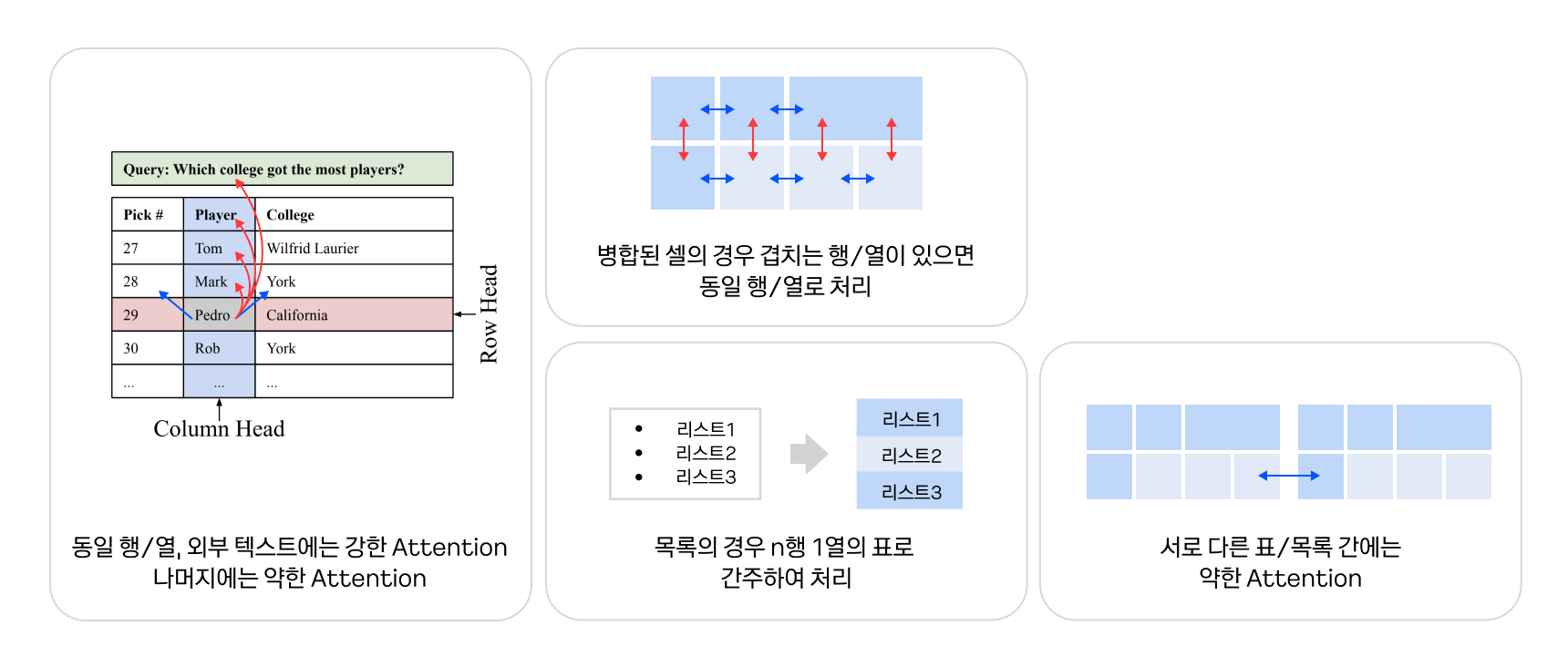
이를 적용한 결과, Large 모델이 아닌 일반 Base 모델임에도 불구하고 기존 1위 모델과 근소한 성과를 거두었고, 최종 성적 제출을 위해 Large 모델 학습을 시작했습니다.
제출용 모델: Base + Self-Distillation
제출에 앞서 Base 모델에는 Self-Distillation 기법을 적용했습니다. 이 기법은 일반적인 방법으로 모델을 학습시킨 후, 최초 학습된 모델이 두 번째 학습 예정인 모델을 가르치는 형태입니다. 두 번째 생성된 모델은 최초 생성 모델보다 대체로 정확도가 더 높아집니다. 그리고 Base 모델만으로도 충분히 좋은 성능을 내는 것을 확인했으므로, Base 모델과 동일한 세팅에 모델 크기만 키워서 LittleBird Large PLM 학습을 실시했습니다. 결과적으로 Large 모델을 통해 2022년 3월 8일 기준 KorQuAD 2.0에서 1위를 달성할 수 있었습니다.
처리 시간 축소를 위한 최적화
이번 챌린지에서는 정확도뿐만 아니라 처리 시간도 함께 측정되었기 때문에, 성능이 높아야 할 뿐만 아니라 속도도 빨라야 하는 2가지 요구사항을 충족해야 했습니다. 문서와 질문이 모델에 입력된 순간부터 정답이 산출되는 순간까지 전체를 측정하기에, 단순 연산 시간뿐만 아니라 전처리/후처리도 모두 고려해야 했습니다. 또한 모델이 구동되는 시스템의 하드웨어 사양을 정확하게 알 수 없으므로 최대한 범용적인 상황에 맞는 최적화를 진행했습니다.

모듈별 소요 시간을 봤을 때, 전처리/후처리 과정이 전체 시간 중 3분의 1 정도를 차지하는 것을 알 수 있습니다. 시간을 줄이기 위해서는 실제 단순 연산 시간 외 과정을 줄이는 개선 방향이 필요하다고 판단했습니다.
일반적으로 MRC 모델의 전처리 단계에서는 입력된 문서와 질문은 숫자 형태의 토큰으로 변환하고, 문서가 긴 경우 앞서 나왔던 슬라이딩 윈도우 기법을 사용해 여러 청크로 분할합니다. 또한, KorQuAD 2.0에서는 HTML에 대한 추가 처리도 필요했는데요. 최적화를 위해 문서에서 불필요한 태그를 최대한 제거하여 최종 입력 길이가 짧아지도록 처리했습니다. 실제 전처리 최적화를 통해 이전 대비 절반 이상의 시간을 단축할 수 있었습니다.
후처리 과정에서는 각 청크마다 산출된 시작 지점과 끝 지점 logit으로부터 실제 정답의 영역을 찾고, 해당 영역으로부터 정답 텍스트를 복원하여 반환합니다. KorQuAD 2.0에서는 전체 문단이나 표, 목록을 선택해야 하는 경우가 있으므로, 최종 정답의 태그 쌍이 맞는지 확인하여 불일치하는 경우 후처리로 수정하여 정확도를 향상시킬 수 있었습니다. 이러한 후처리 작업을 통해 처리 시간을 64%가량 단축하는 결과를 얻었습니다.
주 연산 최적화
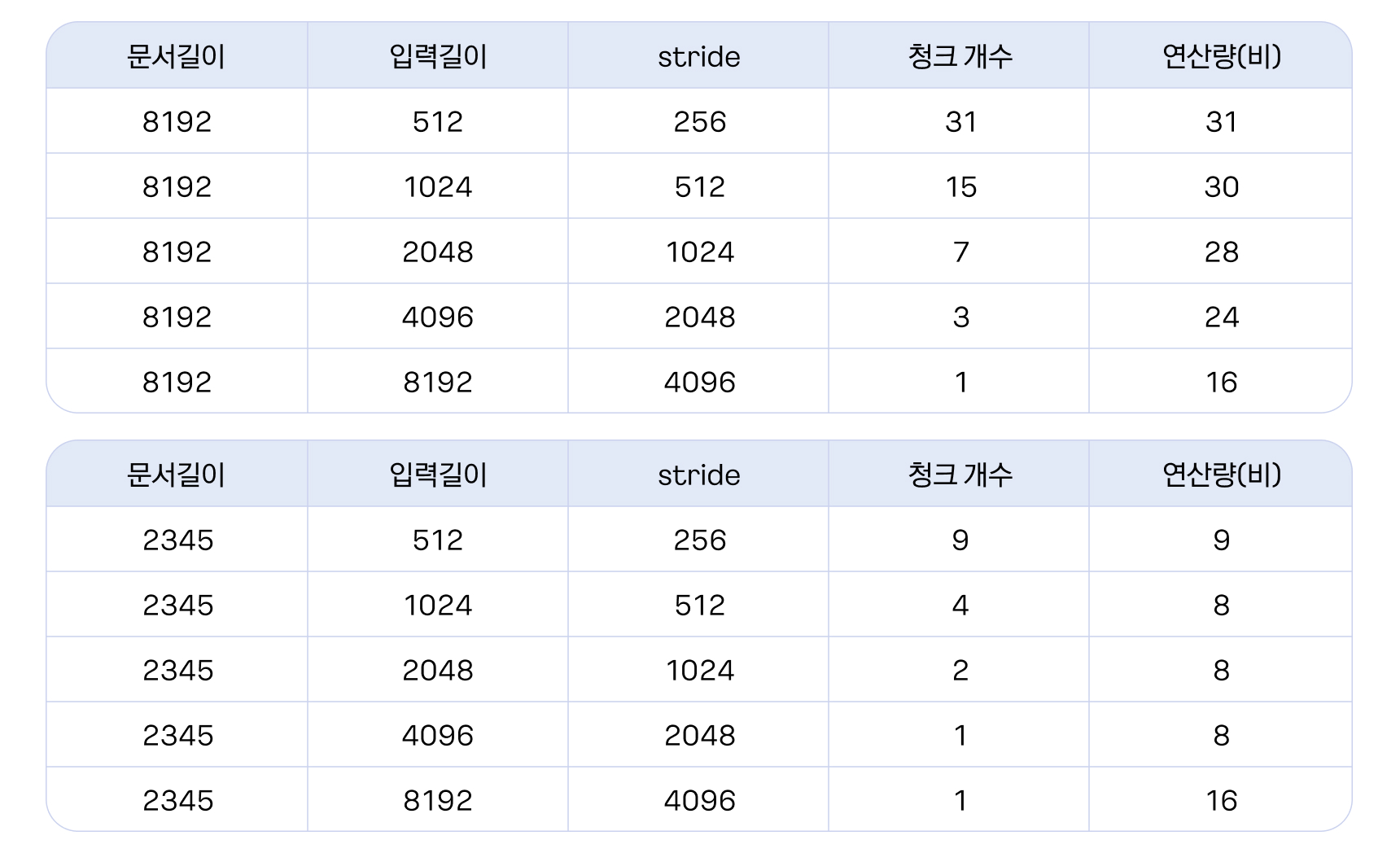
모델 입력 길이가 짧을 경우 문서 하나가 여러 청크로 생성되면서 비효율적인 연산이 발생합니다. 반대로 모델 입력 길이를 늘리면 문서가 덜 쪼개지지만, 그보다 짧은 길이의 문서에 [PAD]이 붙어 연산이 낭비되는 문제 역시 발생합니다. 이때 무작정 모델의 길이를 늘릴 수 없기 때문에, 모델 길이를 늘이되 짧은 청크가 발생하면 짧은 것끼리 모아서 처리하는 Bucketing 방법을 사용하여 최적화를 진행했습니다.
결과 및 향후계획
위 과정을 통해 개발된 모델인 LittleBird-Large는 2022년 3월 8일 기준, 정확도뿐만 아니라 처리 속도(정확도가 비슷한 모델)에서 모두 1위를 달리고 있습니다. 이번 소식은 기계 독해 기술이 적용된 서비스 질의 향상과 직결되는 성과로, 더 나은 사용자 경험을 제공할 수 있을 것으로 기대합니다. 그러나 기존의 Long Transformer Model들보다는 빠르지만, 여전히 무거워 실제 서비스에 적용하기 위해서는 추가적인 최적화 작업이 필요합니다. 또한 Long Transformer Model들의 경우 Sliding Window Attention 기법을 많이 사용하는데, 현재 최적화된 라이브러리가 부재로, 비효율적인 연산을 수행할 수밖에 없는 상황입니다. 또한 Long Transformer Model에 대한 양자화 연구 역시 미진한 상태로, LittleBird 모델의 최적화, 양자화, 경량화 가능성에 대한 연구가 추가로 필요한 상황입니다.
마치며
솔직하게 말하자면, 리더보드에서 좋은 성적을 거두는 건 쉽지 않을 것이라 생각하여 리더보드를 항상 돌 같이 여기며 연구 개발을 진행해 왔었는데요. 이번에 직접 리더보드에 모델을 제출해보면서 다양한 것들을 배울 수 있었습니다. 제일 큰 것은 제가 개발하는 모델에 대해 객관적인 입장에서 바라볼 수 있는 기회가 되었다는 것입니다. 내부에서 연구 개발할 때는 ‘이 정도면 충분히 정확한 것 아닐까?’, ‘이 정도면 꽤 빠른 것 아닐까?’ 생각하며 주어진 데이터와 환경 안에서만 모델을 평가하기 십상인데, 리더보드에 참여함으로써 외부의 객관적인 척도에서 모델에 대해 고민하게 되거든요. 모델 평가에 사용하는 테스트 데이터로 어떤 게 나올지 저희 쪽에서는 전혀 알 수 없으므로, 예기치 못한 사례들에 대해서도 모델이 잘 처리할 수 있는지 모델의 일반화 성능 및 강건성에 대해서도 고민하게 되고요. 여러 가지를 다 고려하고 마음의 준비가 되면 모델을 제출하는데, 제출 후 결과가 나오기까지는 1~2주 정도의 시간이 걸립니다. 이 기다리는 시간이 얼마나 길게 느껴지던지, 결과가 너무 궁금해서 꿈에도 나올 지경이었습니다.
한 번 좋은 성과를 거두고 나니 이제 관련된 다른 리더보드들에 대해서도 도전해보고 싶은 용기가 생겼습니다. MRC라는 과제 내에서만 해도 굉장히 다양한 리더보드가 운영되고 있고, 각기 조금씩 다른 측면에서 모델이 해결해야 할 도전과제를 제시하고 있거든요. 이 리더보드들을 길잡이 삼아 저희 모델을 발전시켜 나가면 더 유용하면서도 튼튼한 모델을 만들어 낼 수 있겠죠? 다른 리더보드에서도 좋은 성적을 내는 그날까지 앞으로도 열심히 연구해보려 합니다. 앞으로도 카카오엔터프라이즈의 자연어 처리 연구에 많은 관심과 응원 부탁드립니다. 감사합니다.
참고 문헌
[1] Electra: Pre-training text encoders as discriminators rather than generators (2020)
[2] Few-shot question answering by pretraining span selection (2021)
[3] Big bird: Transformers for longer sequences (2020)
[4] Luna: Linear unified nested attention (2021)
[5] Train short, test long: Attention with linear biases enables input length extrapolation (2021)
[6] MATE: Multi-view Attention for Table Transformer Efficiency (2021)


Phil(이민철)
아직 인문학도의 향기가 남아있는 자연어처리 개발자입니다. 제 손으로 잘 키운 자연어처리 기술로 세상을 편하게 만들고 싶어요!

John(조승우)
카카오엔터프라이즈에서 카카오 i 대화 엔진의 개체명 인식기, QA 시스템의 정답 유형 분류기를 딥러닝 모델로 서비스하였고, 지금은 맞춤법 검사기를 맡아서 딥러닝 모델로 개발하고 있습니다. 제가 만든 모델이 학습도 잘 되고 성능도 팍팍 잘 나왔으면 좋겠네요. 앞으로 지금보다 더 열심히 공부하고 노력하겠습니다.

Eileen(안애림)
한국어를 자동으로 이해하고 분석하는 자연어처리에 관한 전반적인 언어지식을 연구, 개발하는 언어공학자입니다.