NAACL 2022 참관기
시작하며
안녕하세요. 카카오엔터프라이즈 자연어서비스팀의 Rung(이주성)입니다. 이번 포스팅에서는 제가 올해 직접 발표하고 참관한 NAACL 학회 현장을 소개해드리고자 합니다.
NAACL은 North American Chapter of the Association for Computational Linguistics의 약자로, 북미 전산 언어 협회입니다. 이는 자연어처리 분야에서 ACL(컴퓨터 언어학회), EMNLP(자연어 처리의 경험적 방법론을 다루는 학회)와 함께 인지도가 가장 높은 학회 중 하나로, NAACL 2022은 시애틀에서 7월 10부터 15일까지 6일 간 진행되었습니다.
지난 2년 간 코로나로 인해 많은 학회가 비대면으로 개최되던 것과 달리 올해부터 점점 오프라인과 온라인을 적절히 섞은 하이브리드 형태로 진행되는 추세인데요, 이를 반영하듯 NAACL 2022도 하이브리드로 열렸습니다.
온라인과 오프라인을 넘나들면서 최근 NAACL의 발표자들은 본인의 발표를 녹화한 영상과 슬라이드 자료를 사전에 제출하게끔 되어있는데요. (저와 같이 오프라인 구두 발표자의 경우 필수 제출은 아니었습니다.) 사전 제출 자료를 통해 관심 있는 연구를 학회 참석 전에 확인할 수 있다는 점이 좋았습니다.
이번 학회에 온라인으로 참석한 분들도 열띤 참여를 보이셨지만, 현장의 분위기는 더욱 뜨거웠습니다! 오프라인으로 참석한 많은 분들과 연구 관련 이야기를 나눌 수 있었고 다양한 기업의 부스도 설치되어 있어 다채롭게 살펴볼 수 있었습니다.


그 뜨거웠던 열기를 다 담진 못하겠지만, 이번 포스팅을 통해 본 학회에서 인상 깊었던 내용을 한번 정리해보고자 합니다. 아래는 2022 NAACL의 프로그램 개요인데요, 튜토리얼과 소모임 그룹 워크샵으로 시작해 메인이벤트인 학회 논문 발표를 거쳐 마지막 이틀간 전체 워크샵을 진행합니다. 제가 참여한 일정을 따라가며 소개해드리겠습니다. :)
| 7월 10일 | 튜토리얼 및 학회 소모임 그룹 워크샵 (Affinity Group Workshop) |
| 7월 11일 - 13일 | 메인 학회 (학회 논문 발표, 시스템 시연, Q&A 등) |
| 7월 14일 - 15일 | 워크샵 및 소셜라이징 |
튜토리얼
우선 학회 첫날은 튜토리얼이 진행됩니다. 튜토리얼은 유수 기업 혹은 대학에서 특정 주제에 대해 강의하는 형식입니다. 오전, 오후 세션으로 나눠서 세 챕터가 동시에 진행되는데요, 이때 튜토리얼은 유튜브나 GitHub로도 관련 내용이 올라오기 때문에 학회 참석자가 아니어도 누구나 시청할 수 있습니다.
올해 NAACL 2022에서는 다음과 같은 튜토리얼이 공개되었습니다.
- Text Generation with Text Editing Models (텍스트 편집 모델을 사용한 텍스트 생성)
- Self supervised Representation Learning for Speech Processing (음성 처리를 위한 자기 지도 표현 학습)
- New Frontiers of Information Extraction (정보 추출의 새로운 지평)
- Human Centered Evaluation of Explanations (인간 중심의 설명 평가)
- Multimodal Machine Learning (멀티모달 머신 러닝)
- Contrastive Data and Learning for Natural Language Processing (자연어 처리를 위한 대조 데이터 및 학습)
개인적으로 관심 있게 본 튜토리얼은 “Text Generation with Text Editing Models (텍스트 편집 모델을 사용한 텍스트 생성)” 였는데요. 해당 논문 발표자는 구글과 McGil 대학 연구자들로 구성되어 있었습니다. 튜토리얼의 핵심 주장은 ‘NLG(Natural Language Generation, 자연어 생성) 과정에서 문장을 처음부터 생성하는 것은 비효율적이다’입니다. 물론 모든 task에서 처음부터 생성하는 것이 비효율적이라고 말하는 것은 아닙니다. 해당 튜토리얼에서 비효율적이라 언급하는 NLG task로는 summarization(요약), sentence fusion(문장 융합), grammar correction(문법 교정) 등이 있었습니다.
Summarization은 말 그대로 문단이 주어지면, 이를 짧은 문장으로 요약하는 것입니다. Sentence fusion은 두 문장이 주어지면, 이를 접속사 등을 이용하여 자연스럽게 연결하는 것입니다. 마지막으로 Grammar correction은 주어진 문장에서 문법적으로 틀린 부분을 고쳐주는 것입니다. 아래의 예시를 보면, 각 task 별로 입력 문장(Source text)과 출력 문장(Target text)이 상당 부분 중복되는 것을 확인할 수 있습니다.

이 외에도 많은 NLG task에서 입력 문장과 출력 문장이 상당 부분 겹치는 사실을 확인할 수 있기에 출력 문장을 처음부터 생성하면 리소스를 낭비할 수 있다고 주장합니다. 따라서 해당 튜토리얼에서는 text editing 기법으로 입력 문장을 일부 수정하여 출력 문장을 생성하는 연구를 소개하고 있습니다.
튜토리얼의 대표적인 연구로는 LaserTagger, GECToR, EdiT5 등이 제시되었습니다. 이러한 연구는 먼저 각 단어(토큰)들을 KEEP(유지), DELETE(삭제), INSERT(삽입) 등의 action으로 분류합니다. 이후 각 토큰이 1차 분류된 action대로 수행된다면 유지되고, 그렇지 않으면 삭제되거나 다른 토큰으로 대체되어 최종 출력 문장을 형성합니다.

메인 학회
학회의 메인 이벤트는 2, 3, 4일째에 이뤄지는데요. 이 기간에는 학회에 통과된 논문들이 발표됩니다.
2020년 EMNLP를 시작으로 ACL 학회(ACL, EMNLP, NAACL)에 ‘Findings’라는 개념이 등장했습니다. 보통 학회에 논문을 제출하면 동료 리뷰를 거쳐 논문이 통과되거나 반려됩니다. 그러나 최근 NLP 연구가 많은 관심을 받아 제출물이 급격하게 늘어나면서 좋은 논문임에도 불구하고 통과되지 못하는 경우가 많아졌습니다. 이렇게 아슬아슬하게 반려된 논문은 Findings로 분류됩니다. 즉, 메인 컨퍼런스에 통과된 논문은 아니지만, 유의미한 연구를 발견하고 공유하자는 취지에서 Findings 그룹을 소개하는 것입니다. NAACL은 올해부터 이 Findings에 속한 논문도 함께 통과시켰습니다.
NAACL 학회에서의 논문 발표는 두 가지 방법으로 이뤄집니다. 첫 번째는 구두(oral) 발표이며, 두 번째는 포스터 발표입니다. 구두 발표는 15분 동안 발표 후 질의응답을 진행하는 방법이며, 포스터 발표는 발표장에서 지나다니는 참석자들과 약 90분의 시간 동안 자유롭게 토론하는 방식입니다. (앞서 말한 Findings 논문은 모두 포스터 발표로 지정되어 있습니다.) 구두 발표는 온라인으로 참석하는 하이브리드 참석자의 발표까지 모두 진행한 후 질의 응답 시간이 이어지기 때문에 온오프의 격차가 크게 느껴지지 않았습니다. 하지만 포스터 발표의 경우, 오프라인 발표자는 학회 현장에 있는 반면 온라인 발표자는 ‘게더 타운’이라는 플랫폼을 통해 참여하기 때문에 온오프라인 발표자와 함께 토론할 때 분리되어 있는 느낌이 들었습니다. 이에 저 또한 자연스럽게 오프라인 포스터 발표에 더 적극적으로 참석하여 발표자와 커뮤니케이션하게 되었는데, 이 점이 조금 아쉬웠습니다.
앞서 말씀드렸다시피 저는 현장에서 구두 발표를 하게 되었는데요. 제가 참여한 발표와 함께 흥미롭게 들었던 두 가지 세션을 소개해드리겠습니다. :)
직접 발표한 CoMPM: 사전 학습 모델로 외부 지식을 대체할 수 있다면?
📄 논문 바로가기
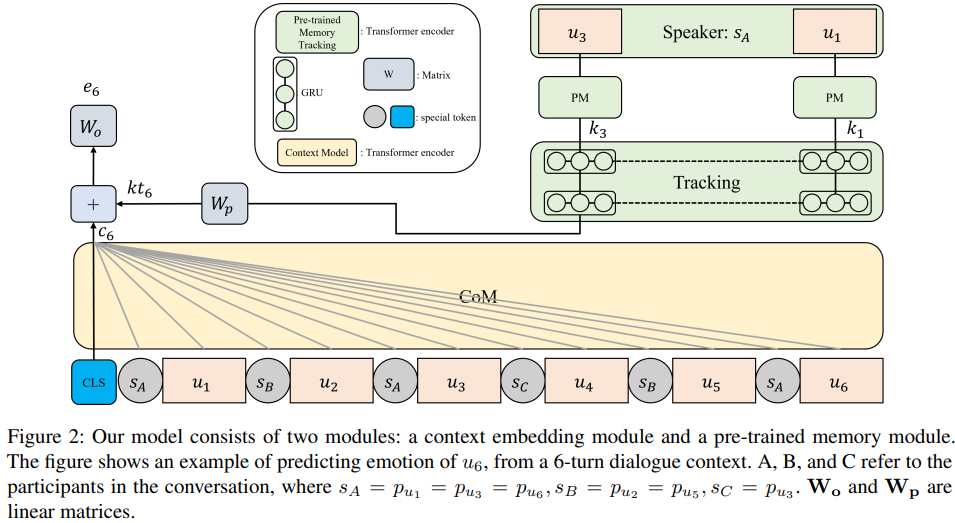
제가 발표한 CoMPM : Context Modeling with Speaker’s Pre trained Memory Tracking for Emotion Recognition in Conversation(NAACL 2022)은 대화 속 개별 발화의 감정을 인식하는 연구입니다. 이는 대화 시스템의 일부 모듈로 작동하며, 대표적으로 서로 상호작용하는 대화, 콜센터 등에 활용할 수 있습니다. 이전의 많은 연구는 외부 지식 데이터를 활용해서 모델의 성능을 높여 왔으나, 외부 지식은 영어권에서만 사용할 수 있기 때문에 한국어와 같은 타 언어는 활용하기 힘든 문제가 있었는데요. 이러한 점에서 착안하여 해당 연구는 앞서 말한 외부 지식의 의존성을 없애려는 목적을 갖고 있습니다.
연구를 간단히 소개해보면, 저희가 제시한 프레임워크는 컨텍스트 모델링을 담당하는 부분인 CoM과 외부지식 모델링을 담당하는 부분인 PM으로 구성됩니다. 이전의 연구들과 다르게, PM은 사전 학습된 모델을 사용하기 때문에 외부 지식 데이터가 필요하지 않습니다. 즉 사전 학습된 모델이 외부 지식으로 학습된 모델을 대체할 수 있다는 것이 핵심입니다.
CoM은 대화 속 모든 발화를 입력받아 현재 발화에 해당하는 컨텍스트 표현을 출력합니다. PM은 화자의 이전 발화들을 가져와 각 발화로부터 특징을 추출합니다. 추출된 특징은 GRU 모델링을 통하여 하나로 합쳐지는데, 이를 ‘사전 학습된 메모리’라 표현합니다. 마지막으로 컨텍스트 표현과 사전 학습된 메모리를 더하여 현재 감정을 예측합니다.
간단한 버전의 데모는 Tech Ground 내 감정분석 페이지에서 사용해볼 수 있습니다.
인상적인 연구 ① : 매력적인 대화를 위한 페르소나 결합 시스템
📄 논문 바로가기
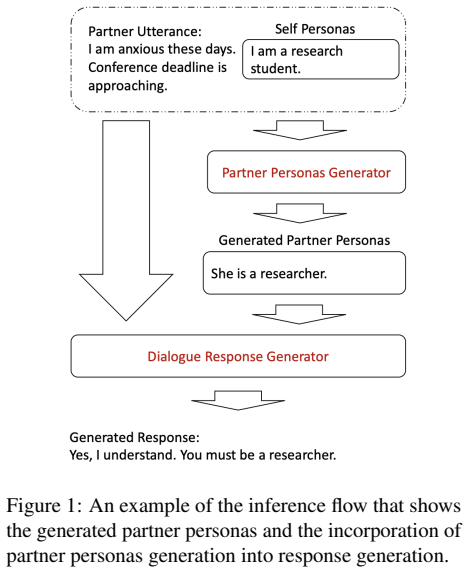
인상 깊게 들었던 발표 중 하나는 Partner Personas Generation for Dialogue Response Generation(NAACL 2022)으로 페르소나 결합 대화 시스템에 대한 내용이었습니다. 논문은 페르소나가 주어진 두 명의 화자가 대화하는 데이터셋으로부터 대화 생성 모델을 학습하는 task를 다룹니다.
페르소나를 결합하여 대화를 생성할 때, 보통 자신(발화자)의 페르소나만을 반영하는 경우가 대부분이지만 해당 연구에서는 대화 상대방의 페르소나를 함께 고려하면 더욱 매력적인 대화를 생성할 수 있다는 것을 보여줍니다. 물론 이전에도 상대방의 페르소나가 대화 시스템에 유의미한 시그널을 주는 연구는 존재합니다. 그러나 이 연구가 가진, 상대방의 페르소나가 주어지지 않을 때 task에서 직접 상대방의 페르소나를 생성해서 반영하는 프레임워크를 제안한다는 차별점이 인상 깊었습니다.
인상적인 연구 ② : Prompt 기반 학습이 가진 취약점에 대한 탐구
📄 논문 바로가기
다른 하나는 Exploring the Universal Vulnerability of Prompt based Learning Paradigm(Findings of NAACL 2022)입니다. 이 논문은 prompt 기반 학습 패러다임 가운데 취약점을 다루고 있으며 앞서 말한 Findings 그룹에 속해 포스터 발표로 진행되었습니다.
prompt 기반 학습은 일반적으로 PLM(Pre-trained Language Model)의 입력 시퀀스 내 다운스트림 태스크에 특정 문자열을 삽입해 모델을 학습시키는 것을 말합니다. 여기서 ‘prompt’란 학습 과정에서 모델의 성능을 향상하기 위해 입력하는 특정 문자열입니다.
최근 언어 모델 GPT-3가 등장한 이후 점점 prompt 기반의 연구 방법이 많아지고 있는데, NAACL에서 prompt를 검색해보면 꽤 많은 논문 검색 결과를 확인할 수 있습니다. 하지만 이 논문은 이러한 prompt 기반의 학습 과정에 취약점이 있다고 주장합니다. ‘attacker’라 불리는 문자열이 입력되면 모델의 오분류를 이끌어 낼 수 있기 때문입니다. PLM 생성 과정에 관여할 수 있을 때와 없을 때에 따라 두 가지 시나리오가 존재하는데요. 시나리오에 따라 attacker을 선정하는 법이 다르지만, 둘 다 취약한 지점이 있음을 제시합니다.

워크샵
워크샵은 학회 5, 6일차의 마지막 일정입니다. 좀 더 자유롭고 편안한 분위기로 오갈 수 있는 워크샵은 총 26개가 이틀에 걸쳐 동시다발적으로 진행되었습니다. 워크샵 기간이 학회 후반이라 참여자들의 초반에 비해 관심도가 많이 떨어지는 것을 체감할 수 있었습니다. (첫날에 비해 학회장에 유동인구가 많이 줄었더라구요.) 그럼에도 불구하고 특정 워크샵은 인기가 상당히 많았습니다. 워크샵 장소에 가보면 보통 자리가 듬성듬성 차있던 것과 달리, “SUKI: Structured and Unstructured Knowledge Integration” 워크샵은 아래 사진에서 보시는 것처럼 자리가 부족해서 간이 의자를 가져오기도 했고, 심지어 저를 포함하여 서서 듣는 사람도 상당히 많았습니다. 하지만 인기와 상관없이 제가 관심 있는 주제의 워크샵을 골라 참여할 수 있는 좋은 시간이었습니다.

마치며
이번 NAACL 2022는 온라인으로 참석해도 모든 논문의 발표를 원활히 들을 수 있는 환경을 마련해놓았습니다. 코로나가 끝나지 않아 학회에 참석한 모든 분들을 직접 만나 뵙지 못한 건 아쉽지만, 하이브리드 형태의 학회를 성황리에 마칠 수 있다는 좋은 예시를 보여준 것 같습니다.
온라인 발표를 보고 난 후 궁금한 점을 메일로 질문해도 대부분의 연구자가 친절히 답변합니다. 물론 저도 제 발표를 듣고 비대면으로 질문 주신 분들께 감사한 마음으로 답변드렸는데요.:) 그렇지만 현장에서만 오롯이 느낄 수 있는 에너지가 분명 있다고 느꼈습니다. 반드시 학술적인 질문이 아니더라도 많은 연구자와의 가벼운 대화나 대면 토론을 통해 자극을 받기도 했고요.
중간 소셜 미팅 시간 때 우연히 마주친 한국인들에게 말을 걸어 함께 식사하며 얘기를 나누면서 다른 소셜 미팅에도 초대되었습니다. 만난 분들의 소속 중 기억나는 곳은 메타, 아마존, MS, IBM, 네이버, 삼성 SDS, AllenAI 등이 있었고 이외에도 수많은 국내 및 해외 대학원생들이 해당 소셜 미팅에 참여해 다양한 대화를 나눌 수 있었습니다. 또, 작년에 참여한 SIMMC 2.0 챌린지의 주최자인 메타 연구자 분과도 우연히 만나 반가웠던 기억이 새록새록 나네요. 각자 회사를 다니고 연구하며 느낀 점에 대해 이야기하며 좋은 자극과 에너지를 얻은 소중한 경험이었습니다.
이 글을 보고 계실 독자 분들께도 온전히 전달드릴 순 없었겠지만 현장 사진들과 제 글로 조금이나마 에너지를 얻었으면 좋겠습니다. 지금까지 NAACL 2022 참관기를 들려드린 렁이었습니다!

Rung (이주성)
연구에 막연한 환상을 품고 대학원에 진학, 이미지의 신호를 처리하는 AI 세계에 첫 발을 내딛었습니다. 그러다, 새로운 분야를 개척하고 싶어하는 제 지적 호기심이 저를 언어처리 분야로 이끌었습니다. 이에 현재는 카카오엔터프라이즈 자연어서비스팀에서 사람처럼 대화를 나누는 인공지능 모델을 만들고 있습니다. 사람들에게 신선함을 주는 AI, 그리고 더 많은 분야에서의 AI를 만들며 성장해나가고자 합니다.