카카오 i 번역 서비스에 적용된 학습 원리와 성능 개선기
시작하며
카카오엔터프라이즈의 5개 AI 엔진 중 하나인, 번역 엔진은 그 기술과 카카오가 축적한 노하우로 일반 대중에게 카카오 i 번역 서비스를 제공하고 있습니다. 2018년 오픈 당시, 처음 6개 언어로 시작한 번역 서비스는 현재 총 19개 (한국어, 영어, 일본어, 중국어, 베트남어, 인도네시아어, 프랑스어, 독일어, 스페인어, 포르투갈어, 러시아어, 이탈리아어, 네덜란드어, 터키어, 태국어, 말레이시아어, 아랍어, 힌디어, 벵골어)에 이르는 언어 간 번역을 지원합니다.
본 글에서는 카카오 i 번역 서비스의 근간을 이루는 기술 개발의 원리를 공유하고자 합니다.
19개 언어간 번역 학습 원리
학습해야 하는 모델 관점에서 본다면, 지원 언어의 개수를 늘리고 모든 언어 쌍 간의 번역 기능을 제공하는 것은 결코 간단한 문제가 아닙니다. 예를 들어 "한국어-영어"라는 하나의 언어 쌍만 다룰 경우, 2개의 학습 모델이 필요하지만, 여기에 중국어를 추가할 경우 총 3*2개(한영, 한중, 영한, 영중, 중영, 중한)의 모델이 필요합니다. 즉 n개의 언어라고 가정하면 총 n*(n-1)개의 학습 모델이 필요하게 되며, 19개 언어를 지원하기 위해서는 총 342개의 모델을 학습해야 한다는 계산이 나오며, 이 수치는 상당히 크다고 볼 수 있습니다. 그렇다면 100개 이상의 언어 번역을 지원하는 구글 번역기는 도대체 총 몇 개의 모델을 학습했을까요? 저도 무척 궁금합니다.
이제 "카카오는 어떻게 342개나 되는 모델을 학습한 것인가?"라는 의문이 생긴 분들이 계실 텐데, 사실 저희도 342개 모델을 모두 학습시킨 것은 아닙니다. 40여 개의 모델만으로 모든 19개 언어 쌍 간의 번역을 지원하도록 작업하였는데 여기에 사용한 몇 가지 해결책을 공개하도록 하겠습니다.
구글의 Zero-Shot Translation 방식 적용
첫 번째, 여러 언어를 하나의 모델로 함께 학습시키는 방법인 "Zero-Shot Translation"에서 그 해답을 찾았습니다. 이 방식은 구글에서 2016년 발표한 논문[1]에 상세히 기재되어 있는데, 요약하자면 기존 모델과 동일하게 사용하되 어떤 언어로 번역할지 방향을 지시하는 메타 토큰을 하나 더 추가하는 방법입니다. 논문에서는 Many to One, One to Many, Many to Many의 세 가지 방식으로 모델을 학습시키고 그 성능을 비교하였는데, 그 중 Many to One 방식을 사용 시 성능이 약간 향상된 결과가 나타났습니다. 다양한 언어 사이에 존재하는 여러 공통된 번역 규칙이 서로 보완적으로 작용하여 데이터세트를 늘리는 것과 유사한 효과가 나타난 것입니다. 따라서 Many to One 방식은 주로 학습 데이터가 부족한 언어일 때 효과적이라는 결론에 도달할 수 있습니다.
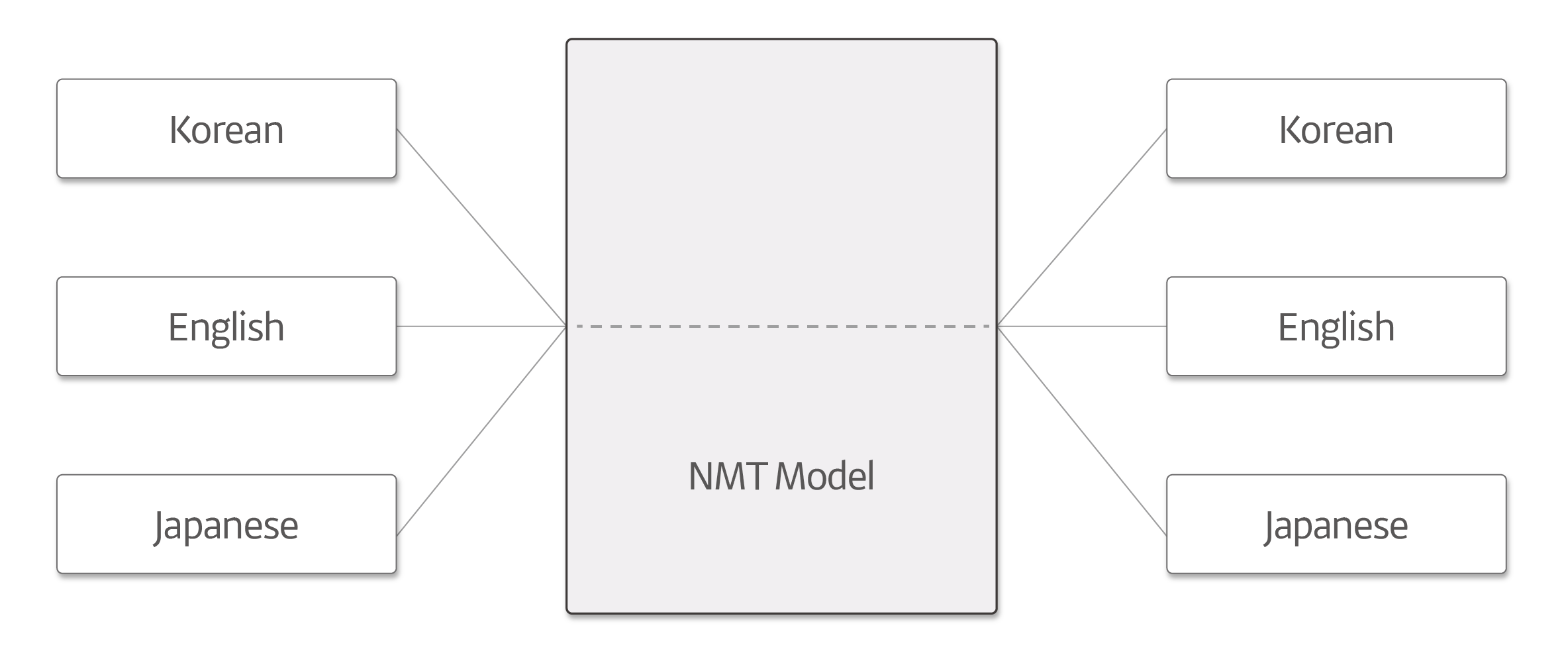
반면 One to Many 또는 Many to Many 방식을 사용 시 학습 성능이 향상되었다고 보기는 어려웠습니다. 이것은 예측 확률과 관련이 있습니다. 즉 학습을 위해서는 기본적으로 문장을 토큰 단위로 나누는 작업이 이루어지는데 이렇게 잘린 최소 정보 단위(토큰)의 집합을 보통 "Vocabulary"라고 부릅니다. Vocabulary를 어떻게 구성하는지도 물론 중요하지만, 여기서는 그 집합의 크기에 유의해야 합니다. 그 이유는 Zero-Shot Translation을 위해 하나의 모델이 다뤄야 하는 언어의 수가 많아지면 Vocabulary Size도 증가할 수밖에 없기 때문입니다. 학습 모델 관점에서 Vocabulary Size가 증가한다는 것은 더 많은 종류의 토큰을 인식해야 함을 의미하며, 최종적인 확률 모델에서 n개의 토큰 중 하나를 예측해야 할 때 맞히기가 더욱 어려워지게 됩니다. 따라서 동시에 학습할 대상 언어를 늘리는 것이 항상 좋은 것은 아니며, 이런 이유로 One to Many 와 Many to Many 방식의 경우 학습 성능이 향상되지 않은 것으로 추측됩니다.
하지만 Many to Many 방식에도 한 가지 장점이 있었는데, 입력된 문장에 여러 언어가 섞여 있을 경우에도 번역이 가능하다는 것입니다. 예를 들어 중국어와 영어가 섞여 있는 문장을 한국어로 번역할 수 있는데, 이는 기존의 단일 언어 쌍으로만 학습해서는 얻을 수 없는 결과입니다. 더 독특한 점은, 학습 데이터가 전혀 없던 언어 쌍 간의 번역이 어느 정도 이루어진다는 사실입니다. 예를 들어 영어/한국어, 영어/일본어에 해당하는 학습 데이터만을 사용하여 to 3 방식으로 번역 모델을 학습시키는 경우, 일본어/한국어 학습 데이터가 없음에도 불구하고 해당 언어 간 번역이 가능합니다. 논문 저자는 이를 진정한 의미의 "Transfer Learning"이라고 표현하고 있는데, 이를 통해 저희는 신경망 기계 번역인 NMT(Neural Machine Translation) 모델의 잠재력을 한 번 더 확인할 수 있었습니다.
결론적으로 저희 카카오 AI 기술팀에서는 Many to Many 방식을 사용하여 학습해야 하는 모델 수를 줄였습니다. 다만 작업의 편의성을 위해 다양한 언어 쌍을 적용하지는 않았고, 같은 언어 쌍에 해당하는 두 모델 (예를 들어, 힌디어 → 영어 / 영어 →힌디어)을 별도의 모델을 통하지 않고 한꺼번에 학습시키는 방법을 사용하였습니다. 즉 "2 to 2 방식"이라고 할 수 있는데, 이 방법의 장점은 별도의 메타 토큰(번역 방향 지시 토큰)이 필요하지 않다는 것입니다. 그 이유는 모델이 소스 언어에 따라 타깃 언어가 무엇인지 스스로 학습해내기 때문입니다.
특히 영어의 경우 거의 모든 언어에서 몇 가지 공통된 어휘들이 나타나기 때문에 영어를 포함하는 번역 쌍에 대해서는 2 to 2 방식의 장점이 증대될 수 있을 것으로 기대했습니다. 실제로 실험을 해본 결과 추가적인 성능 향상을 확인할 수는 없었지만, 성능이 낮아지지도 않았습니다. 2 to 2 방식을 사용하여 저희는 처음 의도한 바와 같이 학습해야 할 전체 모델 수를 반으로 줄일 수 있었습니다.
특정 언어와 제 3 언어의 연결
학습해야 할 모델 수를 줄이기 위한 두 번째 방법은 특정 언어를 매개로 하여 제3 언어들을 연결하는 것입니다. 예를 들어, 힌디어/베트남어 사이의 번역은 어떻게 지원할 수 있을까요? 안타깝지만 힌디어/베트남어의 직접적인 병렬 말뭉치(Parallel Corpus), 즉 원문과 대역문을 모아놓은 언어 자료를 구하기가 매우 힘듭니다. 거의 없다고 보는 편이 나은 상황입니다. 그렇지만 영어/베트남, 영어/힌디어는 상대적으로 데이터가 풍부하여 모델을 만들 수 있습니다. 즉 영어를 매개로 하여 두 번 번역할 수밖에 없는데, 힌디어에서 영어로, 다시 영어에서 베트남어로 가는 방식입니다. 물론 이 경우 시간이 두 배로 걸리고 한 번 번역할 때 생긴 오류가 중첩되어 부적절한 결과가 나올 확률이 높아지는 문제도 있습니다.
따라서 저희는 이번 개편에서도 한국어 또는 영어가 포함되지 않는 언어 쌍에 대한 번역은 영어를 매개로 하여 간접적으로 번역하는 방식을 채택하였습니다. 한국어가 포함된 번역의 경우 간접적인 방식으로 처리해서는 만족할 만한 성능을 확보하기 힘들었기 때문에, 한국어 기준 번역에서는 모든 언어 쌍 간의 모델을 직접 학습시켰습니다. 이 방식을 거치면 최종적으로 필요한 모델의 수는 40여 개로 줄어들게 됩니다. 고려해야 하는 모델의 수는 이렇게 줄였는데, 그렇다면 영어 기준이거나 한국어 기준의 학습 데이터인 40여 종류의 병렬 말뭉치는 어떻게 확보했을까요? 이에 대한 해결책도 공유해 드리겠습니다.
사실 영어 기준 데이터는 공개된 데이터를 수집하는 방식으로도 제법 많이 확보할 수 있습니다. 하지만 한국어는 상황이 다릅니다. 한국어 기준의 데이터로는 한국어/영어의 병렬 말뭉치도 부족할뿐더러 그 외의 언어들은 더욱 구하기 어렵습니다. 그렇기에 여기에서도 영어를 최대한 활용하였습니다. 전 세계적으로 영어가 가장 널리 쓰이고 있기에 영어 기준의 언어 쌍에 대한 학습 데이터를 가장 많이 확보할 수 있으며, 결국 영어가 포함되는 언어 쌍 간의 번역 성능이 좋을 수밖에 없기 때문입니다.
우선 저희는 영어 기준의 데이터를 통해 영어 기준 번역 모델을 모두 학습시켰습니다. 그런 다음 카카오에서 자체적으로 보유하고 있는 한국어/영어의 병렬 말뭉치 속 영어 문장들을 위의 영어 기준 번역 모델에 적용하였는데, 이를 통해 한국어와 제 3 언어 간의 병렬 말뭉치를 확보할 수 있었습니다. 이 후 일차적으로 확보한 병렬 말뭉치에서 여러 정제 작업을 진행하고 부적절한 문장 쌍을 최대한 제거한 후 최종 학습 데이터에 포함시키는 과정을 거쳐 순수 병렬 말뭉치 규모의 한계를 많이 극복할 수 있었습니다.
각 언어 별로 많은 이슈들이 있었지만 대체로 위와 같은 방식을 통해 학습 데이터를 구축하고 모델을 학습하여 19개의 언어 쌍 간 번역을 가능하게 만들었습니다. 추가된 언어의 번역 성능 또한 대부분의 언어와 비교해도 우위에 있다고 평가되었습니다.
번역 성능 개선 및 기능 추가
번역 서비스의 가장 중요한 목표는 무엇보다 번역 품질의 향상이라고 할 수 있습니다. 특히 가장 활용도가 높은 영한/한영의 번역 성능을 더욱 끌어올리기 위하여 데이터 및 모델 관점에서 몇 가지 작업을 진행하였습니다.
고유명사 번역
한국어에서 영어로 번역할 때, 한국어 고유명사(특히 인명이 포함되는 경우)가 제대로 번역되지 않는 경우가 존재합니다. 이는 영어에서 한국어로 번역되는 사례가 월등히 많아 한국어 고유명사가 학습 데이터 내에 부족하기 때문에, 학습이 제대로 안 될 수밖에 없으며, 이는 곧 성능 문제로 귀결됩니다. 그 중에서도 유연석, 김하늘 등 이름이 보통 명사와 겹치는 경우는 번역하기가 더욱 까다롭습니다. 이번 개편을 준비하면서 카카오 AI 기술팀에서는 데이터 증대 기법으로 레이블이 존재하는 데이터에 변화를 줘 원본 데이터와 같은 레이블을 가지는 새로운 데이터를 만드는 방법인 "Data Augmentation"기법을 통해 한국어 고유명사가 적절하게 번역될 수 있도록 다양한 실험을 진행하였습니다. 대문자 또는 소문자로만 이루어진 영어 원문을 번역하는 경우나 구두점이 생략된 경우 등의 번역에서도 Data Augmentation 기법을 사용하였는데, 개선된 결과는 이번 개편 서비스에 반영되었습니다.
문맥(Context)까지 번역
위의 방식은 데이터 보강을 통해 특정 오류 영역을 개선한 것이라면, 이것과 별개로 제한된 데이터에서의 근본적인 성능 개선을 위하여 더 넓은 문맥(Context)을 활용할 수 있도록 하는 실험도 진행하였습니다.
일반적으로 모델의 학습은 문장 단위로 이루어지는데, 더욱 적절하게 번역하기 위해서는 앞뒤 문장이나 문단과 같이 보다 넓은 문맥을 봐야 하는 경우가 있습니다. 예를 들어 "I live in the big city. There are many things that are better than living in the country." 라는 두 문장을 함께 번역을 한다고 가정해봅시다. 문맥상 두 번째 문장의 Country는 "나라"가 아닌 "시골"로 번역되어야 적절할 것입니다. 이 문장에서는 City와 반대되는 개념으로 Country가 쓰였기 때문입니다. 그런데 문장 단위로 번역하다 보면 첫 번째 문장을 따로 해석하게 되는데, 이 경우 Country는 "나라"로 번역될 확률이 굉장히 높습니다. Country가 "시골"보다는 "나라"라는 의미로 더 흔하게 사용되기 때문입니다.

이런 문제를 해결하기 위하여 저희는 학습의 입출력을 개선하여 실험을 감행하였습니다. 기존 모델의 학습 데이터가 "원문 : 번역문" 쌍의 집합이었다면, 새로운 모델은 추가로 "원문 + 컨텍스트문 : 번역문"을 포함하고 있습니다. 덕분에 문맥 정보가 필요한 연속된 문장의 경우보다 적절한 번역 결과를 얻을 수 있었습니다. 물론 충분한 데이터가 확보되지 않았기 때문에 여전히 불가피하게 오류가 발생하고 있지만, 대다수의 경우 이전보다 나은 결과를 보여주는 것을 확인하였습니다.
문체 변환 기능
한국어는 문체, 특히 예사말/높임말의 구분이 뚜렷합니다. 그렇기에 대체로 문장 단위로 이루어지는 기계번역 서비스에 아티클 단위의 입력이 들어오면 한국어로 번역된 문장 간 문체의 통일성 부족으로 불편함이 느껴질 수 있습니다. 이를 해결하기 위해 번역된 결과의 문체를 예사말/높임말로 변환할 수 있는 기능을 추가하였습니다.


처음에는 영한 번역에 대하여 문체를 변환하는 모델을 별도로 구축하여 기능이 잘 작동하는지 확인했었습니다. 그런데 문체 변환 기능은 모든 한국어 방향으로의 번역에 필요하기 때문에 실제 서비스에 적용하기 위해서는 18개의 추가적인 학습 모델이 필요하였습니다. 더욱 효율적인 작업을 위하여 저희는 한국어로 번역된 결과를 다시 특정 문체로 변환할 수 있는 새로운 모델을 구축하게 되었습니다. 즉 한국어에서 한국어로 문체를 변환하는 추가적인 모델을 만들고, 모든 언어 간 번역 결과에 이를 활용할 수 있도록 한 것입니다.
이때 학습 데이터를 대량으로 구축하기 위해 위에서 별도로 구축한 영한 번역의 문체 변환 모델을 이용하였습니다. 영어 원문을 영한 번역 모델에 넣으면 문체가 정해지지 않은 한국어 문장이 결과로 나오고, 동일한 영어 원문을 문체 변환 모델에 넣으면 예사말과 높임말로 번역된 결과가 나옵니다. 만들어진 "문체 미지정 한국어 문장 → 문체 지정(예사말/높임말) 한국어 문장"의 학습 데이터를 이용하여 예사말 모델과 높임말 모델을 학습시키면서, 한국어를 입력했을 때 각각의 모델을 통해 예사말 또는 높임말로 변환할 수 있었습니다. 결국 2개의 모델 만으로 19개 언어 쌍 번역을 모두 지원하게 된 것입니다.
문체 변환은 "한국어"에서 "높임말 한국어"로 변환하는 것이기 때문에, 어떻게 보면 일반적인 두 언어 사이의 번역과 유사하다고 할 수 있습니다. 기계번역 모델이 언어 번역 규칙을 학습하여 입력 단어열을 적절한 출력 단어열로 변환해주는 것처럼, 문체 변환 모델 역시 문체 변환 규칙을 학습하여 입력 단어열에 대응하는 적절한 단어열을 출력하는 것이므로 이 두 모델의 논리 구조는 동일합니다. 따라서 저희는 기계번역 모델과 동일한 모델을 사용하여 문체 변환 모델을 학습시키게 되었습니다.
하이라이팅 기능
최신 기계번역 모델(NMT)의 주요 특징으로 "Attention[2]"이라는 기법이 있는데, 이 기법은 뉴럴 네트워크(Neural Network)에서 번역문의 특정 단어를 예측할 때 원문에 대응하는 단어 가중치 정보를 학습하여 활용하는 방식입니다. 이 기법을 통해 NMT 번역 성능을 개선하였고, 최종 번역 결과를 만드는 과정에서 중간 부산물로 생성되는 정보를 활용하면 의미 있는 시각효과도 얻을 수 있습니다.

다만 Attention 정보의 정확도에는 분명 한계가 있습니다. 특히 언어에 따라 정확하게 1:1 관계가 성립하지 않는 경우나 의역이 이루어지는 경우에 부적합한 결과가 나올 수 있습니다. 또한 직접 모델을 학습한 경우에만 Attention 정보가 생성되기 때문에, 해당 기능은 한국어 또는 영어가 포함된 언어 사이에서만 제공됩니다. 예를 들어 태국어에서 중국으로 번역하는 경우에는 지원되지 않습니다.
그럼에도 하이라이팅 기능은 문법 구조나 어휘가 비교적 유사한 언어 사이에서는 효과적으로 활용할 수 있을 것입니다. 특히 단어 간 매칭 정보를 하이라이팅 하기 때문에 사람들이 새로운 외국어를 학습할 때 큰 도움을 줄 것으로 기대합니다. 하이라이팅 기능은 기본적으로 활성화되어 있으며, 마우스 포인터를 특정 단어 위에 위치시키면 매칭되는 단어의 색깔이 강조되어 나타납니다.
마치며
30년 동안 공부해도 여전히 입이 잘 떨어지지 않는 영어를 기계가 일주일 만에 학습해서 번역을 척척해내는 것을 보면 기술의 발전이 정말 대단하다는 것을 많이 느낍니다. 특히 이번 개선을 진행하며 태어나서 한 번도 접해본 적이 없는 언어들의 번역기를 10개 이상 만드는 경험을 하였는데, 특정 언어를 전혀 모르지만 이런 번역기를 만들 수 있다는 사실이 그저 놀랍기만 합니다. 이 과정에서 물론 여러 난관이 있었는데, 그 중 태국어와 관련된 내용을 짧게나마 여러분과 공유하고 싶습니다.
언어와 문화
질문을 하나 드려 보겠습니다. 아래는 태국어에 대한 위키피디아의 태국어 공식 위키 페이지에 있는 첫 문단인데, 대략 몇 문장 정도로 이루어져 있을까요?
ภาษาไทย หรือ ภาษาไทยกลาง เป็นภาษาราชการและภาษาประจำชาติของประเทศไทย ภาษาไทยเป็นภาษาในกลุ่มภาษาไทซึ่งเป็นกลุ่มย่อยของตระกูลภาษาขร้า-ไท สันนิษฐานว่า ภาษาในตระกูลนี้มีถิ่นกำเนิดจากทางตอนใต้ของประเทศจีน และนักภาษาศาสตร์บางส่วนเสนอว่า ภาษาไทยน่าจะมีความเชื่อมโยงกับตระกูลภาษาออสโตร-เอเชียติก ตระกูลภาษาออสโตรนีเซียน และตระกูลภาษาจีน-ทิเบต
아시는 분들도 계시겠지만, 태국어는 문장의 종결이 명확하지 않습니다. 띄어쓰기가 없을 뿐만 아니라 문장의 끝을 의미하는 구두점도 없습니다. 물론 구문 분석을 통해 우리가 생각하는 문장단위로 나눌 수는 있겠습니다만, 기본적으로 태국어는 문장단위를 명시적으로 표시하지 않습니다.
언뜻 보면 이상해 보이는데, 우리가 접속사나 추임새를 적절히 넣어가면서 계속 말을 이어나가는 상황을 떠올리시면 됩니다. 태국 사람들은 말을 할 때처럼 글로 표현할 때에도 의미상 연결되는 내용이라면 접속사를 활용해서 계속 이어나가며 문단을 구성하고, 맥락이 바뀌면 그제서야 문단을 나눕니다. 즉, 태국어에서는 "문단"이 문장보다 중요한 것입니다.
이렇게 각 언어에는 해당 국가나 민족의 특성 및 문화가 반영됩니다. 따라서 문화의 유사도에 따라 언어들 간의 번역이 수월할 수도 있고 어려울 수도 있습니다. 현재 기계번역의 성능은 매우 높습니다만, 문화가 다른 언어 사이의 번역에서는 여전히 한계를 드러냅니다. 사람이 새로운 언어를 배우는 것과도 유사한데, 우리나라 사람이 한국어와 가장 유사한 언어인 일본어를 비교적 쉽게 배우며 영국인이 서유럽 언어들은 쉽게 배우는 반면, 우리나라 사람이 영어를 배우거나 서유럽인이 아시아의 언어를 배우는 것은 상대적으로 어려운 것과 같습니다. 일례로 흔히 우리나라 사람이 영어를 배우면서 어려움을 겪는 상황 중 하나는 "예/아니오(Yes/No)"로 대답해야 하는 경우입니다. 우리나라의 경우 질문에 대하여 논리적으로 맞으면 '예', 틀리면 '아니오'를 쓰는 반면, 영어의 경우 의미가 여전히 긍정이면 "Yes"로 부정이면 "No"를 사용하기 때문입니다. 영어에 익숙해지기 전까지는 많이들 실수하곤 합니다.
기계번역에서도 이런 문제가 학습에 영향을 미칩니다. 일반적으로 문장단위로 학습 데이터가 구성되고, 그중 대부분의 질문은 긍정형이기 때문에 확률모델을 따르는 인공 신경망은 "Yes"는 "예"로 "No"는 "아니오"로 학습하게 됩니다. 하지만 정확하게 번역하기 위해서는 이전 문장의 질문을 참고하여 그에 맞게 번역을 해야 합니다. 모델이 이런 경우를 제대로 학습하기 위해서는 상당히 많은 규모의 부정 의문문 및 이에 대응하는 답변이 학습 데이터에 포함되어야 하며, 단순한 문장단위의 학습을 넘어서는 실험이 이루어져야 합니다. 그리고 이 두 가지 모두 쉽게 해결하기 어려운 문제입니다.
기계 번역의 현 주소
이쯤에서 기계번역 성능의 현 주소를 아래와 같이 정리해보겠습니다.
- 문법 구조나 어휘가 유사한 언어들 사이의 번역 성능은 매우 우수하며, 사람을 상당 부분 대체할 수 있음(서유럽 언어들 간 번역, 한국어/일본어 번역 등)
- 유사도가 낮은 언어 간 번역에서는 기계번역을 제한적으로만 활용할 수 있음
결국 기대 수준의 문제이기도 합니다. 대화를 통한 깊은 소통이나 문학적인 내용의 번역 등을 기대한다면 기계번역에는 분명 한계가 있습니다. 그렇지만 보조 수단으로 활용하기에는 지금 수준으로도 충분히 만족할 만한 - 특히 유사도가 높은 언어 사이에서 - 성능을 제공합니다.
기계번역 서비스에서 단기간 내에 전문 번역가 수준의 번역이 이루어지지는 않을 것입니다. 이는 약인공지능의 제한된 기능을 뛰어넘어 더 발달된 인공지능인 AGI(Artificial General Intelligence)의 영역이기 때문입니다. 미래 어느 순간에 기계번역에서 발생하는 여러 문제가 완전히 해결된다면, 그것은 곧 AGI 시대의 도래로 볼 수 있을 것입니다.
카카오엔터프라이즈에서는 최근 요구사항이 많고 성능 개선의 여지가 큰 특허, 법률 등의 특정 분야에 대한 전문 번역 개발을 통해 더 나은 번역 서비스를 제공하고자 합니다. 다양한 도메인 영역의 번역 기술(domain adaptation)이 개발되고 서비스화 되어 가는 과정도 추후 공유 드릴 수 있는 날이 곧 올 거라 생각합니다.
참고 문헌
[1] Johnson, M. et al. (2017). Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation.Transactions of the Association for Computational Linguistics, 5, 339–351.
[2] Bahdanau, D., Cho, K. H., & Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of 3rd International Conference on Learning Representations, ICLR 2015 (pp. 1-15).

새로운 길에 도전하는 최고의 Krew들과 함께 해요!

배재경
도전 과제를 찾고 이를 해결해 나가는 것이 재밌고 신나는 개발자입니다. 아이디어를 아낌없이 공유해 주시는 많은 훌륭한 분들이 있어서 세상이 더 빨리 나아지는 것 같습니다. 저도 그 길에 작은 보탬이 되고 싶습니다.