사진에서 사람을 읽다
시작하며
카카오를 비롯한 지도(map) 서비스를 제공하는 기업들은 전국 각지의 도로, 거리 등을 촬영합니다. 하지만 기업이 촬영한 화면을 그대로 서비스에 활용할 수는 없습니다. 촬영된 화면 안에 사람의 얼굴이나 자동차 번호판이 노출되는 것은 사생활 침해가 될 수 있고, 이런 이유로 카카오맵 서비스는 프라이버시 보호를 위해 사람의 얼굴과 차량의 번호판 식별이 어렵도록 흐릿하게 처리(Blurring)를 합니다. [그림 1]에도 사람의 얼굴과 차량의 번호판이 흐릿하게 처리된 모습을 확인할 수 있는데, 여기서 큰 문제가 발생합니다. 전국 곳곳에서 찍은 수많은 양의 사진을 사람이 일일이 확인하고, 흐릿하게 처리하는 것은 엄청난 비용과 시간이 소요되는 작업이라는 것입니다.
카카오엔터프라이즈는 이와 같은 문제를 해결하기 위해 AI 기술을 활용하여 사진 처리에 소요되는 비용과 시간을 줄이고자 노력했습니다. 본 글에서는 카카오맵 로드뷰 서비스에 적용된 기술 개발의 원리를 공유하고자 합니다.
카카오맵 로드뷰에 적용된 객체 검출 기술
카카오맵 로드뷰 서비스는 전국 각지의 실제 거리 모습을 확인할 수 있도록 도와줍니다. 여기서 국내 최초의 포털 지도 서비스인 로드뷰로 제공되는 화면은 DSLR 카메라를 활용하여 고해상도 파노라마 방식으로 거리를 촬영한 것입니다. 촬영은 특정 장소를 360도로 찍는 방식으로 진행되는데, 차가 다닐 수 있는 도로에서는 차량 위에 고정한 특수 촬영 장비를 사용하고 차가 다닐 수 없는 좁은 도로나 공원, 아파트 단지 등은 특수 제작된 세그웨이(Segway)나 파노캠을 사용합니다.

카카오맵 로드뷰 서비스에서는 객체 검출(Object Detection)기술이 이용됩니다. 이 기술은 영상에서 사람, 차량, 건물 등과 같이 특정한 클래스(Class)1에 속하는 객체를 자동으로 찾는 컴퓨터 비전(Computer Vision)과 영상처리(Image Processing)가 합쳐진 컴퓨터 기술을 의미합니다. 이는 스마트폰, 로봇, 출입통제 시스템 등에서 얼굴 검출을 하거나 자동 차량 주행에서 보행자 검출을 목적으로 널리 사용되고 있습니다. 카카오는 바로 이를 이용하여 영상 내에서 AI가 사람의 얼굴과 차량 번호판을 스스로 찾아낸 뒤, 일반인이 해당 개체(Object)를 식별할 수 없도록 흐릿하게 만듭니다. 객체 검출 기술의 도입으로, 기존의 수동 방법 대비 90% 이상의 작업량 감소 효과가 발생했습니다. 부연 설명을 하자면, 과거 한 장의 영상에 100개의 얼굴 또는 번호판이 있는 경우 이전에는 100개의 위치를 일일이 표시하고 확인 과정을 거쳐야 했습니다. 하지만 객체 검출 방법 도입 후 90여 개 이상의 객체가 자동 처리되고, 10개 이하의 객체만 사람이 수동으로 확인하면 되기 때문에 그만큼 작업량과 시간을 절약할 수 있습니다. 로드뷰로 인한 사생활 침해가 발생할 가능성을 차단하고자, 영상은 자동 처리된 이후에도 사람에 의해 최종적으로 검수된 이후에야 서비스됩니다.
딥러닝이 바꿔놓은 객체 검출 패러다임
객체 검출의 수준을 대폭 개선시킨 것은 바로 콘볼루션 신경망(Convolutional Neural Network, 이하 CNN)을 기반으로 한 딥러닝(Deep Learning)기술로, AI에 딥러닝 적용이 본격적으로 시작된 시점은 2012년 ImageNet Large Scale Visual Recognition Challenge(ILSVRC) 대회 이후부터 입니다. 딥러닝은 기존의 학습 방법보다 2배 이상의 성능을 보여주며, 객체 검출 방식의 패러다임을 완전히 바꾸어 놓았습니다. 딥러닝 이전의 객체 검출 방법에서는 여러 클래스(Multi-Class)의 객체를 검출하고자 할 때, 각 클래스에 사용되는 특징(Feature)을 다르게 사용해야 좋은 결과를 얻을 수 있었습니다. 때문에 각 클래스 별로 검출기를 설계하고 학습했는데, 예를 들어 N 개 클래스의 객체를 검출하기 위해서는 N 개의 검출기를 필요로 했고, 이에 비례하는 비용과 수고를 필요로 했습니다. 하지만 딥러닝은 이러한 수고를 덜어주었습니다. 딥러닝 기술을 사용하여 영상 내에서 찾고자 하는 특징을 자동적으로 학습시키고, 하나의 검출기 모델로 여러 클래스를 구분하고 검출하는 것이 가능해졌기 때문입니다.
CNN의 단점을 보완한 R-CNN
반면, 딥러닝의 단점도 존재합니다. 딥러닝은 연산 시간의 측면에서 오랜 시간 잘 다듬어져 왔을뿐더러 상대적으로 훨씬 가벼운 기존의 객체 검출 방법에 비해 많은 연산 양을 필요로 합니다. 이로 인해 하나의 영상으로부터 여러 단계의 크기로 늘리거나 줄인 영상들을 생성하는 영상처리 기법으로, 객체의 크기 변화에 강인한 검출을 위해서 흔히 사용되는 피라미드 표현(Pyramid Representation)이나 사각형 영역(윈도우)을 영상 전체로 훑어가면서, 찾고자하는 객체가 그 안에 존재하는지를 확인하여 검출하는 기법인 슬라이딩 윈도우즈 기법(Sliding Windows)등의 전통적인 객체 검출 기법들은 딥러닝을 활용한 객체 검출 기법에 적용하기 어렵습니다. 이러한 한계를 극복하기 위해 효율성 높은 기존의 방법을 차용하여 객체가 있을만한 후보 영역을 먼저 찾아내고, 그 영역에 딥러닝 기법을 적용하는 방법들이 제안되었습니다. 그 대표적인 예가 Region with Convolutional Neural Network(R-CNN)[1]입니다. 이는 영상에 선택적 탐색(Selective Search)[2]이라는 방법을 적용하여 객체가 있을 법한 후보 영역인 Region Proposal(RP)을 찾고, 각 RP에 CNN을 적용하여 객체를 분류한 뒤 객체의 위치를 보정하는 방법입니다. R-CNN은 긴 연산 시간이 소요되는 CNN이 각 RP마다 적용되어야 하기에 검출을 위해 소요되는 시간이 전체적으로 길다는 단점이 있습니다. 특히 반복되고 병렬 연산이 가능한 CNN의 연산 속도는 그래픽스 처리 장치(Graphics Processor Unit, GPU) 덕에 개선되었지만, RP를 계산하는 부분은 여전히 계산 속도가 느려 병목 현상(Bottleneck)이 발생합니다.
Fast R-CNN & Faster R-CNN
R-CNN의 시간문제를 개선한 방법이 바로 Fast R-CNN[3]입니다. 이 방법은 Region of Interest Pooling(ROI Pooling)이라는 계층(Layer)을 도입하여, CNN에서 얻어진 특징 지도(Feature Map)의 일부 영역으로부터 정규화된 특징을 추출합니다. Fast R-CNN은 각 RP에 CNN을 반복적으로 적용하는 대신, 입력 영상에 CNN을 한 번만 적용하고 ROI Pooling으로 객체를 판별하기 위한 특징을 추출합니다. 이런 방식으로 Fast R-CNN은 CNN에 비해 특징을 추출하기 위한 시간을 대폭 줄일 수 있었습니다.
여기서 더 나아가, 선택적 탐색 등을 이용하여 RP를 추출하였던 기존 방법을 딥러닝 방법으로 대체하는 방안으로서 속도를 획기적으로 개선한 Faster R-CNN[4]도 있습니다. 카카오맵 로드뷰에서 최근까지 사용되었던 방법은 해당 방법을 기반으로 하고 있습니다. 이 방법은 Regional Proposal Network(RPN)를 제안하고 CNN 이후 단계에 연결하여 이전의 방법들에서 사용했던 선택적 탐색을 대신하도록 하였습니다. RPN은 CNN에서 얻은 특징 지도로부터 객체가 있을 것으로 보이는 영역을 제안하며, 해당 영역은 Faster R-CNN과 동일하게 ROI Pooling을 통해 정규화된 특징을 추출하고, 그 특징으로 객체를 판별하며 위치와 크기를 보정합니다.
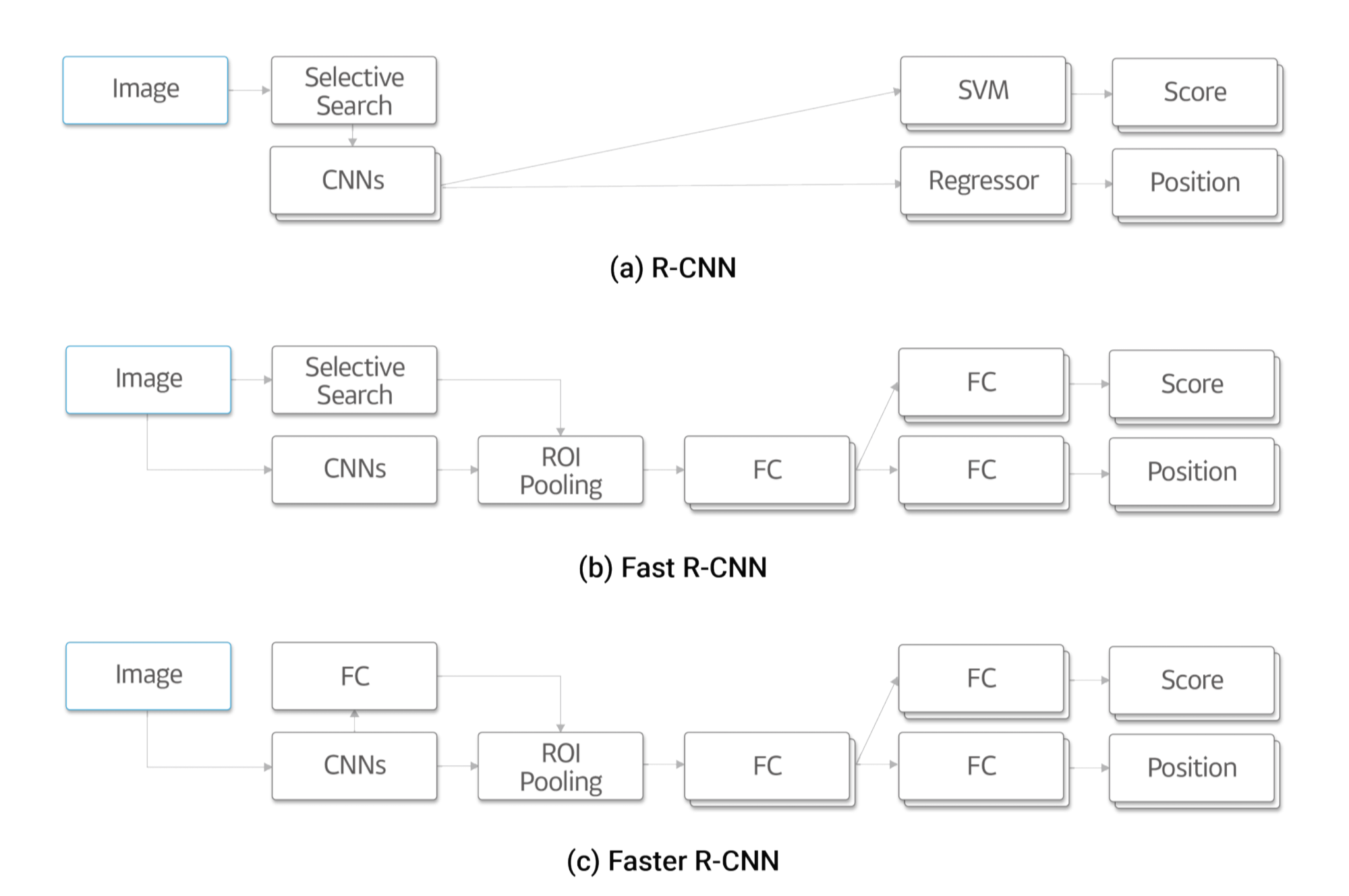
[그림 2]에서 (a)의 CNNs 블록에서 볼 수 있듯, 겹쳐진 블록들은 반복되어 수행되어야 하는 연산을 나타냅니다. (a)가 수많은 RP에 대해 각각 CNN 연산을 수행해야 하는 반면, (b)와 (c)는 한 번의 CNNs 연산만을 사용합니다. 또한 (a)와 (b)가 연산량이 많은 선택적 탐색을 사용하는 반면, (c)는 FC(Fully Connected Layer)를 사용함으로써 연산량을 크게 줄였습니다.
또한 [그림 2]에서 R-CNN, Fast R-CNN, Faster R-CNN의 구조 간 차이를 볼 수 있습니다. 먼저 R-CNN([그림 2] a)은 선택적 탐색을 통해 얻어진 각 영역에 대해 CNN 연산을 합니다. 그리고 CNN에서 얻어진 특징을 이용하여 기계학습의 분류(Classification) 문제에 많이 사용되는 알고리즘인 Support Vector Machine(SVM)과 Regression이라는 기법으로 박스의 위치와 크기를 예측하는 방법인 Regressor로 객체 여부를 판단하고 위치를 보정합니다. 하지만 연산량이 많은 CNN 연산이 반복되는 단점이 있습니다. 이를 극복하기 위해 Fast R-CNN([그림 2] b)은 영상 전체에서 CNN 연산을 한번 하고, 선택적 탐색으로 얻어진 영역에 대해 ROI Pooling 기법을 이용하여 특징을 추출합니다. 여기서 추출된 특징은 FC를 거쳐 객체 여부와 위치를 얻게 됩니다. 그러나 선택적 탐색 방법 자체는 속도가 느리다는 단점이 있습니다. 이 때문에 Faster R-CNN([그림 2] c)과 CNN으로부터 얻은 특징 값을 이용하여 RP를 얻을 수 있는 RPN를 설계함으로써 속도를 크게 높였습니다. Faster R-CNN이 가진 또 하나의 장점은 여러 다른 기능들(RP, 분류기, Regressor)을 각각 학습하는 대신, 처음부터 끝까지 한꺼번에 학습시키는 End-to-End 학습이 가능하다는 점입니다. 하지만 Faster R-CNN은 일반적으로 우수한 성능을 보이지만 큰 객체와 작은 객체를 같이 학습할 경우 작은 객체의 검출 성능이 상대적으로 떨어진다는 단점이 있습니다.
Faster R-CNN을 개선한 카카오 RF-RCNN
크기가 크고 특징이 많은 자동차, 사람 등의 객체는 번호판과 같이 작은 객체에 비하여 객체 여부(Objectness)가 더 뚜렷하며, 일반적으로 RPN은 큰 객체에서 더 잘 동작합니다. 그러므로 번호판의 위치에 RP가 잘 주어질 가능성보다는 자동차 전체에 주어질 가능성이 더 크다고 할 수 있습니다. 자동차 전체 영상에서 번호판을 판단하는 것은 잘 추정된 얼굴이나 자동차의 RP에서 얼굴과 자동차를 판단하는 것보다 어려운 문제이므로, 번호판을 판단하는 성능은 상대적으로 떨어지게 됩니다. 이러한 단점을 개선하기 위해서 카카오는 정제 네트워크(Refining Network)[5]를 사용하고 있습니다. 이는 Faster R-CNN의 검출 결과로 나오는 객체 위치정보를 이용하여 다시 한번 객체를 검증하고, 위치를 보정하는 역할을 합니다. 더 자세히 말하자면, Faster R-CNN 부분으로부터 얻은 객체의 영역 정보에 해당하는 정규화된 특징을 특징 지도로부터 추출하고, 이 특징을 통해 객체를 판단하여 위치를 재보정하면서 성능을 높입니다.
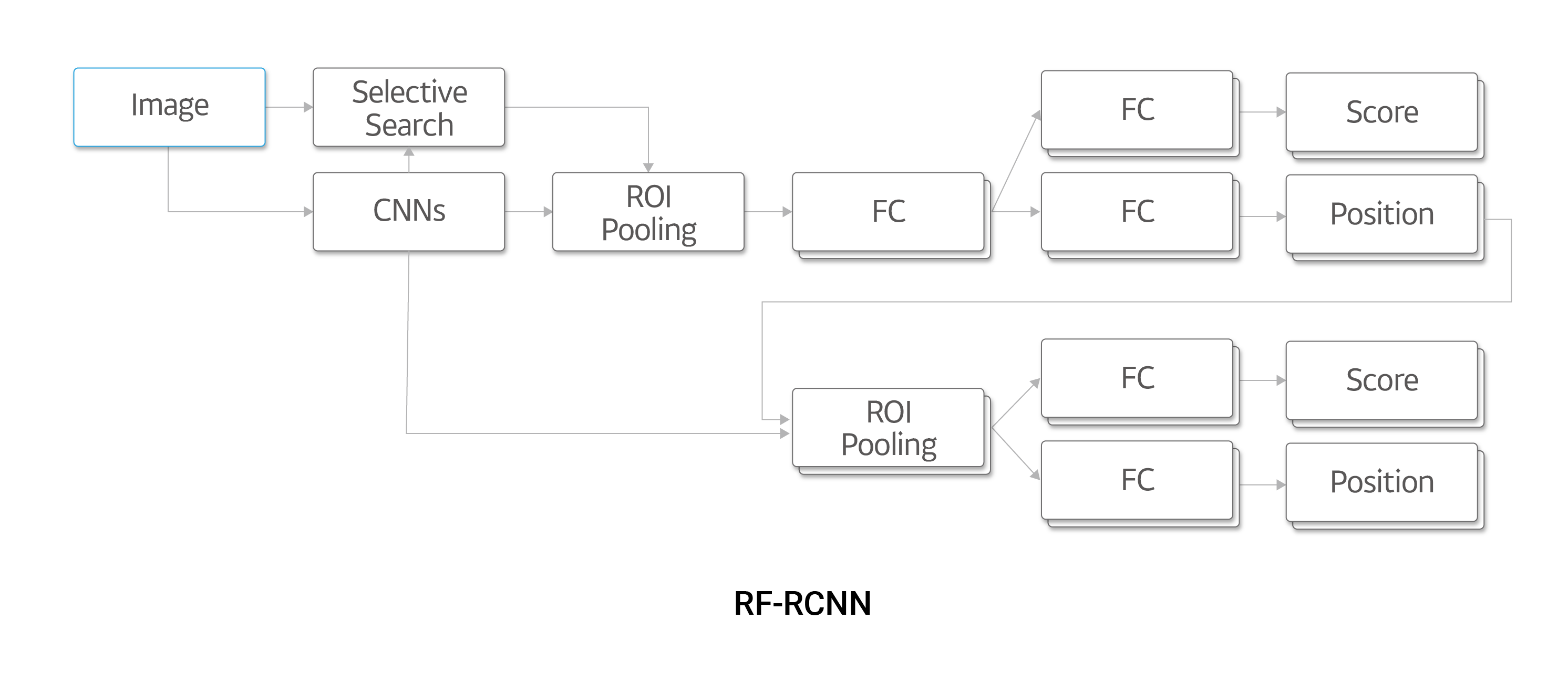
[그림 3]은 저희가 제안한 Refining Faster RCNN(RF-RCNN)의 네트워크 구조를 보여줍니다. Faster R-CNN([그림 2] c)과 비교하면, Faster R-CNN의 CNN 이후의 네트워크와 비슷한 구조가 다시 한번 반복되는 구조를 보여주고 있습니다. 그리고 Faster R-CNN 부분에서 얻어진 위치로부터 다시 한번 ROI Pooling과 FC 연산이 이루어집니다. 이때 Faster R-CNN에서 얻은 위치 정보는 한번 보정된 값이므로, 보다 정확한 위치에 대해서 객체 여부를 판단할 수 있습니다.
Faster R-CNN과 RF-RCNN의 객체 검출 성능 비교
로드뷰 객체 검출기의 성능을 평가하기 위해 실제로 카카오맵 로드뷰에 사용되는 900장의 초고해상도 영상을 사용했습니다. [표 1]은 Faster R-CNN과 제안한 RF-RCNN의 결과를 보여줍니다. 수치는 Equal Error Rate(EER)로, 수치가 작을수록 오류가 적음을 나타냅니다. [표 1]에서 보는 바와 같이, 번호판 검출의 오류가 크게 줄어들었음을 알 수 있습니다. 이에 비해 사람 검출 오류는 1%가량 증가하였으나, 전체적인 오류 감소에 비해 미미하다고 할 수 있습니다.
| 구분 | 전체 | 번호판 | 사람 |
| Faster R-CNN | 0.39 | 0.57 | 0.21 |
| RF-RCNN | 0.25 | 0.30 | 0.22 |
[표 1] Faster R-CNN과 RF-RCNN의 검출 오류 비교 실험2
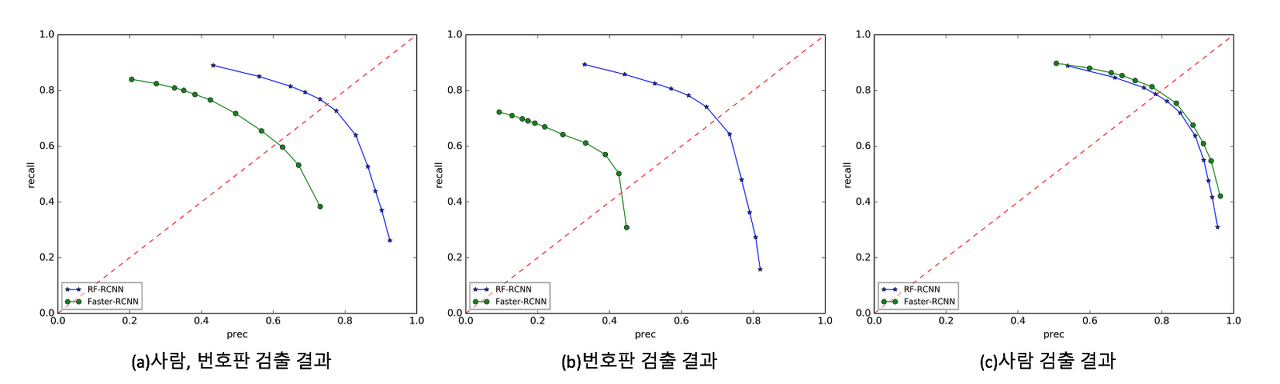
[그림 4]는 Faster R-CNN과 RF-RCNN의 성능을 Receiver Operating Characteristic Curve(ROC) 곡선으로 나타낸 것으로, 곡선이 우측 상단으로 붙을수록 좋은 성능이라는 것을 의미합니다. [그림 4]에서 x-축은 검출한 객체 중에서 제대로 검출된 객체의 비율인 Precision을, y-축은 검출해야할 객체 중에서 검출에 성공한 객체의 비율인 Recall을 나타내며, 녹색 곡선은 Faster R-CNN을, 파란색 곡선은 RF-RCNN을 각각 나타냅니다. 그림에서 볼 수 있듯이, RF-RCNN이 사람 검출([그림 4] c)에서는 비슷하거나 미세하게 떨어지지만, 번호판 검출([그림 4] b)에 있어서는 매우 우수한 성능을 보여주고 있습니다. 결과적으로 전체적인 성능, 즉 사람과 번호판 검출의 성능은 [그림 4]의 (a)와 같이 상승하는 것을 볼 수 있습니다.
[그림 5]는 Faster R-CNN과 RF-RCNN 검출 결과를 비교하여 보여줍니다. 차량이 있는 영상(위쪽)에서 Faster R-CNN의 번호판 검출 결과(왼쪽)는 오검출(False Positive)이 여러 개 보이는 반면, RF-RCNN(오른쪽)에서는 그런 오류가 나타나지 않고 있습니다. 또한 사람이 있는 영상(아래쪽)에서 Faster R-CNN(왼쪽)은 미검출(False Negative)이 두 명 있는 반면, RF-RCNN(오른쪽)에서는 미검출이 한 명 있는 결과를 보여줍니다. RF-RCNN(오른쪽) 사진의 왼쪽 상단에 있는 마네킹은 오검출의 사례입니다.

[그림 6]은 결과 영상의 예를 보여줍니다. 푸른색 사각형은 검출된 사람의 윗부분(얼굴 영역에 해당하는 부분)을 나타내고, 주황색 사각형은 검출된 자동차 번호판을 나타냅니다. 사람들과 자동차가 많은 영상에서도 상당히 높은 수준의 검출 결과를 보여줍니다.

검출 성능 평가는 사전에 수동으로 만들어 놓은 정답의 위치와 검출 결과를 비교하여 자동 평가를 수행합니다. 이때, 해상도가 낮거나 작아서 식별이 불가능한 번호판과 얼굴은 정답에 포함시키지 않았습니다. 검출기가 검출한 결과에는 이렇게 제외한 객체도 검출되는 경우가 종종 발생하는데 이는 자동 평가 시에 오검출로 평가됩니다. 하지만 실제 환경에서는 이렇게 검출된 객체도 틀렸다고 할 수는 없기 때문에 오검출의 개수가 줄어들었다는 점에서 체감 성능은 더 좋다고 할 수 있습니다. 실제 수동으로 검증하여 평가하였을 경우 96%가량의 검출률을 보여주는 것으로 집계되었습니다.
마치며
본 글에서는 사생활 침해 방지를 위해 카카오맵 로드뷰 서비스에 활용된 딥러닝을 이용한 검출기의 개발 과정을 공유하였습니다. 이 과정에서 객체 검출 기술의 기본으로 가장 널리 사용되는 Faster R-CNN을 기반으로 하고, 작은 객체의 검출 성능을 향상할 수 있는 Refining Faster RCNN을 제안했습니다. 이를 카카오맵 로드뷰의 흐림 처리 서비스에 적용하면서 기존 대비 96% 이상의 효율 개선 효과를 볼 수 있었습니다.
이처럼 AI 기술은 실제 서비스로 구현되는 과정에서 편리함과 더 나은 가치를 제공합니다. 카카오엔터프라이즈는 앞으로 더 많은 분야에서 AI가 어떤 역할을 할 수 있을지 항상 고민하고 기술 개발에 힘쓰고 있습니다. AI를 통해 우리 삶이 한 층 업그레이드되길 바라며, 글을 마칩니다.
참고 문헌
[1] Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580-587).
[2] Uijlings, J. R., Van De Sande, K. E., Gevers, T., & Smeulders, A. W. (2013). Selective search for object recognition. International journal of computer vision, 104(2), 154-171.
[3] Girshick, R. (2015). Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (pp. 1440-1448).
[4] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (pp. 91-99).
[5] M.-C. Roh, J.-Y. Lee. (2017). Refining Faster-RCNN for Accurate Object Detection. In Proceedings of 15th IAPR International Conference on Machine Vision Applications (pp. 514-517).

노명철
오랫동안 관련 분야에 몸 담아 온 사람으로, 최근 기술의 엄청난 급변을 보는 것이 흥미롭기도 하고 두렵기도 하네요. 이런 변화 사이에서 (치킨집 창업으로 떠밀리지 않기 위해) 열심히 연구하고 있습니다. 좋은 환경에서 훌륭한 동료들과 연구 할 수 있는 것에 감사하고 있고, 아이와 아내에게 자랑스러운 사람이 되고자 합니다.

이주영
놀기 좋아하고 궁금한거 많은 아주 평범한 이웃집 개발자 같은 개발 + 연구하는 사람입니다. 능력 좋고 성격 좋은 분들과 오랜 시간을 함께 하며 많이 배우고 또 앞으로 배울 것 같습니다. deitel & deitel's 책 저자들 처럼 아이가 커서 성인이 되었을 때도 개발 + 연구하는 사람이 되는게 목표입니다.
