신경망 번역 모델의 진화 과정
이 글은 2017년 카카오 AI 브런치에 게재된 포스팅을 가져온 것으로, 본문에서 설명하고 있는 모델 성능, 번역 결과 등은 모두 2017년 당시 자료를 바탕으로 합니다. 2017년까지의 신경망 기반 기계번역(Neural Machine Translation, NMT)의 히스토리를 정리했고, 현재는 대세가 된 NMT 모델 Transformer에 대한 전망 또한 담겨 있습니다. 이를 통해 기계번역의 발전 흐름을 이해하고 향후 발전 방향성에 대해서도 생각해볼 수 있는 시간을 가질 수 있을 것이라 생각합니다.
시작하며
End-to-End 방식의 신경망 기반 기계번역(Neural Machine Translation, 이하 NMT)이 통계 기반 기계 번역(Statistical Machine Translation, 이하 SMT)을 실제 서비스에서 대체하기 시작한 것은 불과 1년 전 일입니다. 인공지능(Artificial Intelligence, 이하 AI)은 AI Winter 시기를 지나, GPU 성능의 성장과 함께 꽃을 피웠습니다. 다양한 문제에 적합한 뉴럴 네트워크들이 쏟아져 나왔고, 단순한 뉴럴 네트워크들이 다양한 방식으로 연결되어 더 크고 복잡한 네트워크를 만들어내고 있습니다.
네트워크가 더 크고 복잡해지는 이유는 각 단위 뉴럴 네트워크들이 어려운 문제를 해결하는데 상보적으로 작용하기 때문입니다. 이는 마치 생명체의 세포들이 모여서 기관을 이루고, 기관들이 모여 온전한 하나의 개체로 완성되는 것과 유사합니다. NMT도 복합 구조를 가지는 가장 전형적인 뉴럴 네트워크 중 하나로, 시각 객체 인식 소프트웨어 연구를 위한 대규모 시각적 데이터베이스 수집 프로젝트인 이미지넷(ImageNet)의 영상 인식 기술처럼 매우 급격히 진화했고 지금도 진화 중입니다.
이번 글에서는 NMT 모델의 진화 과정을 통해 각 모델의 핵심 구조와 아이디어들이 어떻게 발전해왔는지 살펴보겠습니다.
NMT 모델의 진화 과정
지금까지 이루어진 NMT 연구 결과를 하나의 도표로 표현하기는 상당히 어렵습니다. 하지만 주요 기반 뉴럴 네트워크 및 모델 간의 상관관계를 그린 [그림 1]을 참고하여 NMT 모델의 진화과정을 시간 순으로 살펴보겠습니다.
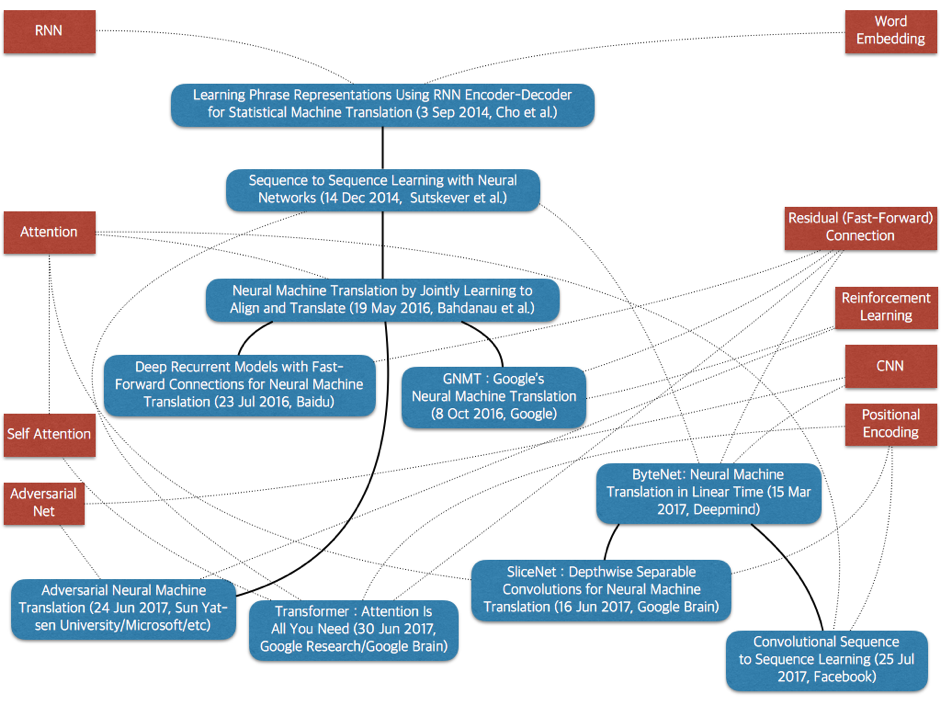
[그림 1]에서 붉은색 사각형은 주요 기반 모듈이고, 푸른색 사각형은 NMT 모델입니다. 각 모델은 기존 모델을 토대로 만들어지기도 하고 어느 정도 독립적으로 생성되기도 하는데요. 그림에서 굵은 실선은 강한 영향 관계 또는 기존 모델을 토대로 했다는 의미이며, 얇은 점선은 약한 영향 관계 또는 내부 모듈로 사용된 경우를 표현합니다.
NMT 모델의 시작
첫 번째 NMT 모델은 2014년 12월에 발표된 Sequence to Sequence Learning with Neural Networks[1] 논문에서 처음 등장했습니다. 이 모델에서 Encoder와 Decoder는 각각 Recurrent Neural Network(RNN)로 구현되며 단위 정보는 Word Embedding을 통해 Continuous Value로 변환되어 사용됩니다. 하지만 이는 인코더-디코더(Encoder-Decoder) 모델을 토대로 확장된 것이기 때문에 Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation[2] 논문이 NMT의 시발점이라고 볼 수도 있습니다. Encoder-Decoder 모델은 단위 정보(Word 또는 Token)의 시퀀스(Sequence)를 입력값으로 받아 고정 길이의 Vector Representation을 생성한 후, 이를 이용하여 또 다른 단위 정보의 Sequence를 생성하는 모델입니다. 이 모델은 Sequence를 주로 다루기 때문에 최근에는 Encoder-Decoder 대신 Sequence-Sequence(Seq2seq)라는 용어를 많이 쓰고 있습니다.
Seq2seq 모델을 NMT에서만 사용하는 것은 아닙니다. 문서 요약, QA(Question Answering), Dialog 등 Sequence 형태로 표현될 수 있는 정보를 다루는 어떤 분야든 사용이 가능합니다. 따라서 NMT의 구조를 파악하는 것은 자연어를 다루는 많은 문제들, 특히 문맥(Context) 정보를 파악해야 하는 과제를 풀어나가는 가장 좋은 출발점이라고 할 수 있습니다.
Seq2seq의 Attention Network 도입
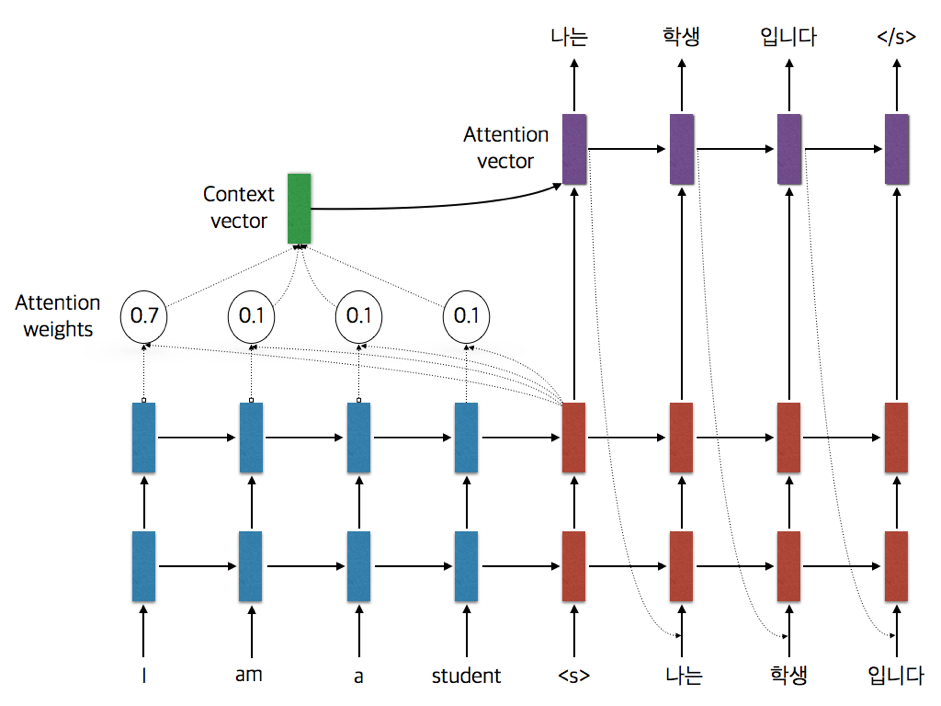
가장 단순한 형태의 Seq2seq 모델은 충분히 만족스러운 성능을 발휘하지 못했고, 뉴럴 네트워크의 가능성을 확인한 데 의의가 있었습니다. 기존의 가장 좋은 통계 기반 기계 번역과 경쟁할 만한 성과를 처음 보여준 모델은 Neural Machine Translation by Jointly Learning to Align and Translate[3] 논문에서 찾을 수 있습니다. 이 모델은 Attention Network을 활용하는 조금 더 복잡한 Decoder를 사용합니다. Attentional Decoder는 디코딩 시 매 Time-Step 별로 새로 생성될 토큰을 결정할 때 Source Sequence에서 가장 가까운 관계의 토큰을 결정하고, 이 정보를 활용하는 구조입니다. 마치 두 가지 언어를 구사할 수 있는 사람이 번역할 때 단어 별로 원문과 번역문을 대조해가며 번역하는 것과 유사합니다.
Attention을 도입함으로써 Encoder의 결과를 고정 길이 벡터에 담아야 하는 문제도 해소되었습니다. 긴 문장의 경우 짧은 문장에 비해 더 많은 정보가 함축될 수밖에 없는데, 길이에 상관없이 고정 길이 벡터를 사용하는 것은 불합리하기 때문입니다. 이 모델에서는 Encoder의 매 Time-Step에 생성되는 벡터가 Attention에 사용되므로 Sequence 길이에 비례하여 더 많은 정보가 활용됩니다. 위 논문에서는 장문 번역의 성능이 높아진 결과를 Attention 도입의 효과로 서술하고 있습니다.
Encoder와 Decoder의 각 RNN은 동일 구조가 반복적으로 쌓인 구조(Multi-RNN)입니다. 이 구조의 경우 단일 Layer에 비해 더 복잡하고 다양한 특징(Feature)을 추출할 수 있습니다. RNN의 각 셀은 Long Short-Term Memory(LSTM) 또는 Gated Recurrent Unit(GRU)을 사용합니다. 논문에서는 추가적인 아이디어로 Bidirectional RNN Encoder를 제안하고 있는데, 이는 양방향의 이력(History) 정보를 모두 활용하여 놓치는 정보를 최소화하려는 시도입니다. 아래 [그림 2]는 이 모델의 구조를 보여주는데요. 이 그림에서는 복잡도를 줄이기 위하여 Unidirectional RNN을 가정하였습니다.
Fast-Forward Connection
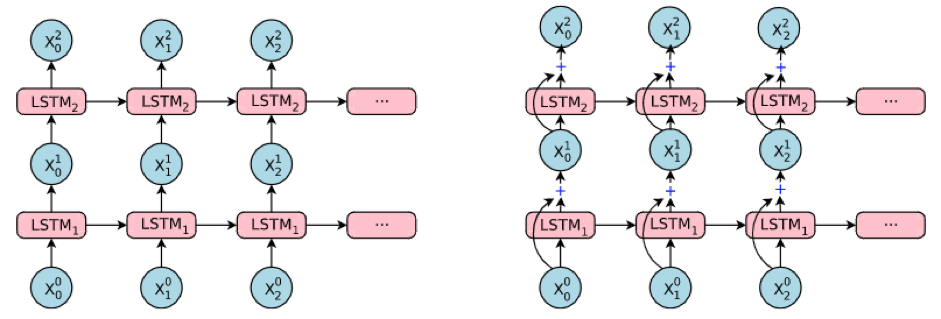
NMT 연구는 Neural Machine Translation by Jointly Learning to Align and Translate 논문 이전에도 여러 기업에서 활발히 이루어졌지만, 이 논문을 계기로 기업들이 한층 더 적극적으로 바뀌었습니다. 특히 구글(Google)과 바이두(Baidu)의 물밑 경쟁은 눈여겨 볼만했는데요. 먼저 바이두에서 추가적인 아이디어를 통해 번역 성능을 높인 논문인 Deep Recurrent Models with Fast-Forward Connections for Neural Machine Translation[4]을 발표했습니다. 이 논문의 핵심 내용은 Fast-Forward Connection(구글은 Residual Connection으로 명명)의 도입입니다. 이 Fast-Forward Connection은 Layer를 깊게 구성할 때 발생하는 문제를 해소했습니다. Encoder나 Decoder에서는 Layer를 깊게 구성할수록 더 풍부한 특징을 추출하여 성능을 높일 수 있는데요. 너무 깊을 경우 기울기 값이 소실되는 문제(Gradient Vanishing)로 학습이 불가능한 경우가 있었습니다. 기존 Encoder나 Decoder에서는 Multi-RNN을 사용할 때 Layer가 3~4개 이상인 경우 학습이 원활하지 않았습니다. 하지만 Fast-Forward Connection은 8개 Layer 이상도 학습이 가능하도록 만들었고, 그 결과 드디어 NMT의 번역 성능이 SMT를 능가하게 되었습니다. 특히 Fast-Forward Connection은 복잡한 뉴럴 네트워크가 아닌, n번째 Layer의 입력이 n+1 번째 Layer의 입력에 함께 들어가도록 추가 Connection을 하나 더하는 방식입니다. 이는 Convolutional Neural Network(CNN)에서 먼저 사용되어 효과가 입증된 것을 RNN에도 유사하게 적용한 것이죠. 아래 [그림 3]에서 단순 RNN과 Fast-Forward(Residual) Connection이 있는 RNN의 차이를 확인할 수 있습니다.
Google’s Neural Machine Translation
사실 구글이 NMT 핵심 연구 분야에서 앞서가고 있었음에도 불구하고, 바이두가 한발 먼저 최고 성능의 번역 모델을 발표한 상황이 되었습니다. 이에 대응하기 위해 구글은 빠르게 실제 서비스를 론칭하는 전략을 택했습니다. 논문으로 실험 결과를 발표하는 것과 실제 서비스화 하는 것에는 큰 차이가 있습니다. 학습 시간의 문제는 물론 응답 속도 및 처리량을 고려하기 위해 많은 추가 작업이 필요하기 때문입니다.
구글은 당시 유효하다고 판단했던 여러 가지 기반 뉴럴 네트워크를 NMT 모델에 적용하였고, 특히 빠른 학습 속도를 위하여 하드웨어에 최적화된 Model Parallelism을 구현하였습니다. 빠른 응답속도를 위해 양자화(Quantization)를 도입하였고, 번역 품질을 극대화하기 위해 길이 정규화(Length Normalization)와 Coverage Penalty 등 몇 가지 예측 알고리즘(Prediction Algorithm) 또한 도입하였습니다. 이 전략은 크게 성공했고, 필자도 구글이 발표한 Google's Neural Machine Translation System[5]이라는 논문을 처음 접했을 때 공학적인 측면에서 감탄하지 않을 수 없었습니다. 이 논문은 Bridging the Gap between Human and Machine Translation이라는 부제를 가지고 있는데요. 그만큼 성능에 자신이 있었기 때문일 것입니다.
하지만 어느 정도 시간이 지난 후 필자는 Google's Neural Machine Translation(GNMT) 모델의 구조가 당시 하드웨어 스펙에 맞추다 보니 다소 부자연스러운 점이 있으며, 많은 알고리즘을 조합한 구조이기 때문에 장기적인 개선 작업이 쉽지 않을 것이라고 판단했습니다. 아니나 다를까 구글은 RNN 기반이 아닌, 새로운 구조의 모델을 조만간 발표하게 됩니다. 이 모델에 대해서는 잠시 후에 다루겠습니다. 사실 그 사이 네이버가 구글보다 먼저 NMT를 번역 서비스에 적용하는 발 빠른 행보를 보였습니다. 그렇지만 모델이 공개되지 않아 그 구조를 파악할 수 없었고, 글자 수 200자 제한을 상당히 오랜 기간 유지한 것이 아쉬운 부분이었습니다.
딥마인드의 ByteNet
네이버와 구글 외에도 여러 업체에서 NMT 기반 번역 서비스를 시작하게 되면서 번역은 비전(Vision) 분야와 함께 딥러닝의 주요 화두가 되었고, 2017년 초부터 또 다른 연구 성과들이 경쟁적으로 공개되었습니다. 그중 가장 주목할 만한 것이 CNN 기반의 모델인 ByteNet입니다.
딥마인드에서 개발한 이 모델은 Neural Machine Translation in Linear Time[6]이라는 논문에서 처음 소개되었으며, 논문의 제목에서도 알 수 있듯이 학습 시간을 선형 시간(Linear Time)에 가능하게 하는 것이 목적입니다. 지금까지의 NMT 모델은 RNN 기반의 Attentional Seq2seq를 거의 정석처럼 사용했는데, Attention Net 때문에 학습 시간이 Quadratic Time(Source Sequence Size * Target Sequence Size)이 소요되었습니다. 반면 ByteNet에서는 Attention Net을 사용하지 않으므로 Linear Time(C * Source Sequence Size + C * Target Sequence Size)에 학습이 가능합니다(여기서 C는 Constant Value). ByteNet은 [그림 4]와 같이 CNN을 사용하여 Encoder 위에 Decoder가 스택처럼 쌓이는 네트워크 구조를 만들고 Dynamic Unfolding이라는 기법을 통해 가변 길이 Sequence를 생성해 냅니다.
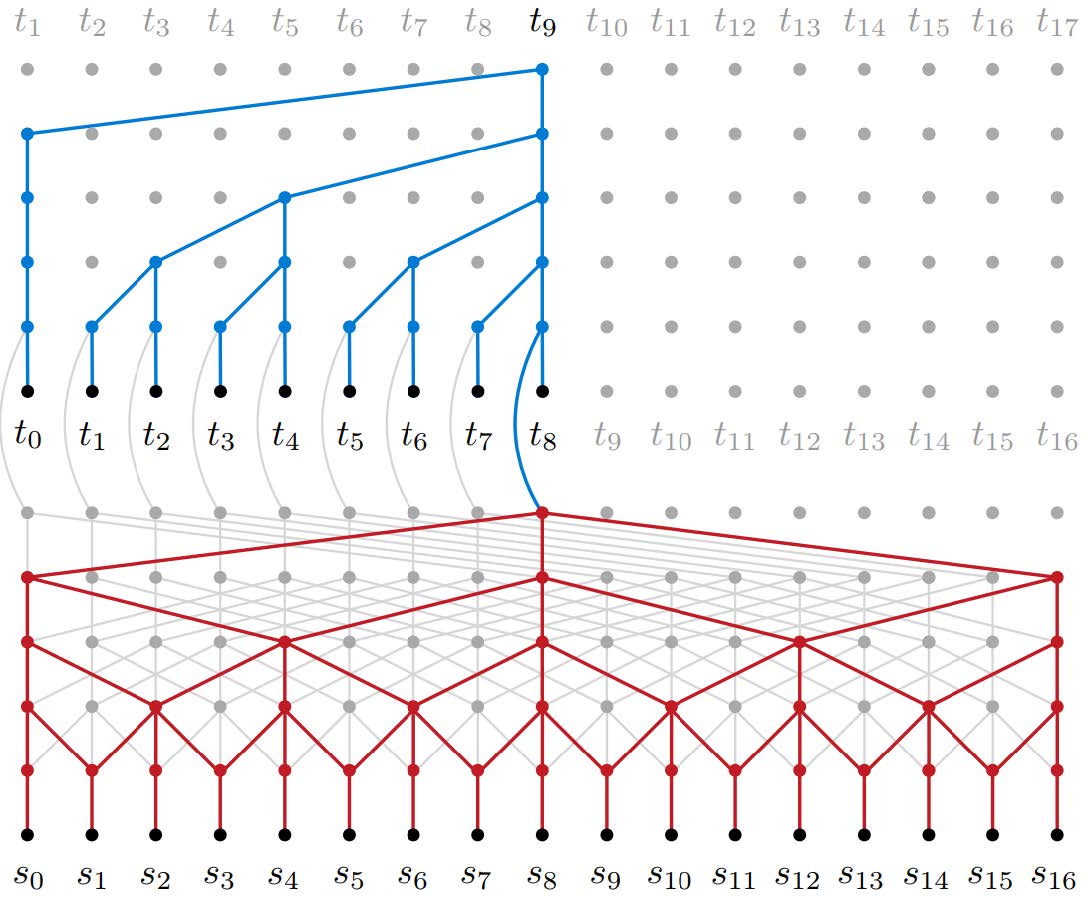
이 모델은 RNN에서 필수적인 Time-Step과 Step 간 정보의 기억(Memorization)이 필요 없게 되는데, 구조적인 특성상 병렬화의 여지가 훨씬 크고, 멀리 떨어진 단위 정보 사이의 관계 특성(Feature)을 더 잘 찾아낼 수 있습니다. 이 모델은 성능에 있어서 기존 RNN 모델과 비교할 수준은 아니었지만, Character-to-Character 번역(단위 정보로 Word나 Token이 아니라 Character를 사용)에서는 최고의 성능을 보여주었습니다.
페이스북과 구글 브레인의 CNN 기반 모델
ByteNet처럼 CNN 기반의 NMT 모델도 짧은 기간 동안 연구가 활발히 이루어져 RNN 기반 모델의 성능을 능가하는 모델이 나오기 시작했습니다. 그중 가장 두드러진 두 가지 모델은 페이스북에서 공개한 Convolutional Sequence to Sequence Learning[7]과 구글 브레인에서 공개한 SliceNet[8] 모델입니다. 두 모델 모두 Convolution Net을 사용하고 Positional Encoding과 Attention Net을 적용하였습니다. SliceNet이 약간 먼저 발표되긴 했지만 Convolution Net의 구조와 Attention Net의 적용 형태가 약간 다를 뿐 서로 상당히 유사합니다. 결국 Attention Net이 RNN에 적용되어 극적인 성능 향상이 이루어진 것처럼 CNN 방식에서도 유사한 과정이 진행되었다고 볼 수 있습니다. CNN에서는 Time-Step이 없으므로 단위 정보의 위치 정보를 표현하기 위한 다른 방법이 필요한데 이를 위해 Positional Encoding을 사용합니다.
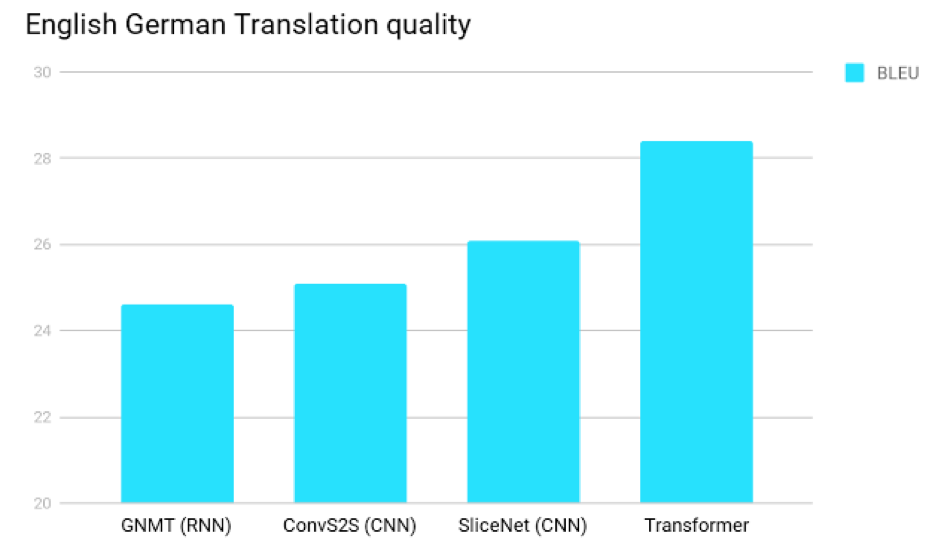
[그림 5]는 주요 모델들의 성능을 비교하여 보여줍니다. 그동안 자연어 텍스트 처리에는 RNN이 적합하다는 관점이 우세했지만 이를 뒤엎는 결과가 나온 것을 확인할 수 있습니다. 필자는 이 결과를 보고 RNN의 시대가 벌써 저무는 것 아닌가 하고 생각했는데요. 과연 그럴지는 두고 볼 일입니다.
Transformer의 등장
비슷한 시기에 RNN, CNN 기반 모델에 비해 압도적인 성능을 보여준 모델이 하나 더 공개되었습니다. Transformer라 불리는 이 모델은 부제가 Attention Is All You Need[10]입니다. RNN과 CNN이 모두 필요 없다는 말이죠. 이 모델의 뉴럴 네트워크는 Attention Net과 Normalization, Feed-Forward Net의 반복적인 구조로 이루어진 매우 단순한 형태입니다. 하지만 Attention Net이 기존에는 Decoder의 Sequence와 Encoder의 Sequence 간 Align을 맞춰주는 용도로 사용되었다면, 여기서는 추가로 Encoder/Decoder 각 Layer의 입력 정보를 함축하는 데 사용되는 방식으로 확장되었습니다. 이 때문에 Transformer에서 추가로 적용된 Attention 방식을 Self-Attention이라고 부르기도 합니다. [그림 6]은 Transformer의 구조를 보여줍니다.
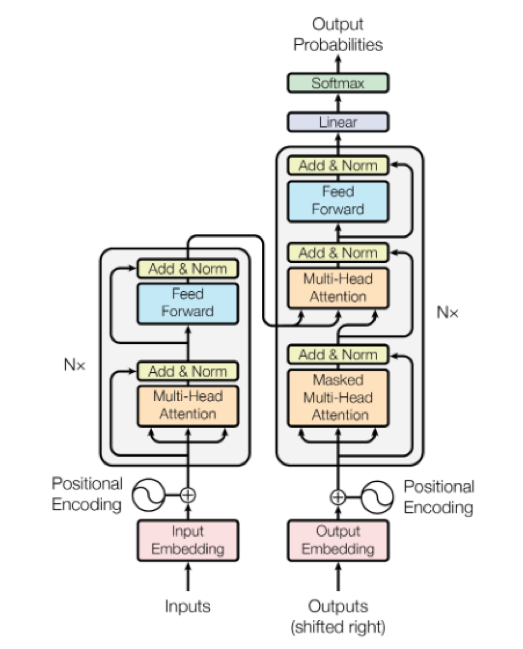
전형적인 Encoder-Decoder 모델의 동작 방식을 다시 되새겨 볼까요? Encoder는 Input 정보를 Vector Representation으로 함축하고, Decoder에서 이 정보를 바탕으로 최종 Output을 생성합니다. 지금까지의 모델은 Input 정보를 함축하기 위해 RNN이나 CNN을 사용했던 반면, Transformer에서는 단위 정보 각각의 상관관계를 Attention Net 구조로 풀어내면서 정보를 함축합니다. 이러한 구조만으로도 Feature 정보를 충분히 잘 추출해내어 RNN과 CNN보다 오히려 더 나은 성능을 보여주었습니다. 이러한 점은 고정관념을 깨는 것으로부터 새로운 발전이 출발한다는 좋은 실례를 보여준다고 할 수 있습니다.
결국 RNN/CNN에 이어 Self-Attention이라는 기반 뉴럴 네트워크가 가세하면서, Encoder-Decoder라는 큰 구조를 제외하면 이에 대한 구현체들은 얼마든지 다양한 방식으로 결정될 수 있다는 생각이 자연스러워졌습니다. Seq2seq는 RNN2RNN, RNN2CNN, CNN2CNN 뿐만 아니라 Any2Any로 고민될 수 있게 된 것이죠. 하지만 개발자 입장에서는 선택의 폭이 넓어진 것이 썩 달갑지만은 않습니다. 대부분의 경우 특정 문제에 어떤 뉴럴 네트워크를 사용하는 것이 적합한지에 대한 명확한 근거가 없기 때문에 실험적으로 접근할 수밖에 없기 때문입니다. 이러한 실험은 수많은 Hyperparameter 최적화 과정뿐만 아니라 기반 뉴럴 네트워크의 다양한 조합들이 모두 고려되어야 하기 때문에 상당한 부담이 됩니다. 그렇지만 조금 더 넓은 틀에서 본다면 특징 추출을 위한 가장 적합한 구조의 뉴럴 네트워크들이 다양하게 발표되고, 많은 연구자들에 의해 이들의 장단점, 특징들이 파악되어 감에 따라 AI가 완전한 Black Box에서 어느 정도 투명하고 제어 가능한 모습을 가지게 될 것이란 기대를 해봅니다. 추가로 AutoML이라는 분야의 연구도 활발히 진행되고 있는데 이는 뉴럴 네트워크 선택과 Hyperparameter 튜닝의 자동화에 대한 연구로 AI 개발자들의 가려운 곳을 많이 긁어줄 수 있을 것으로 기대됩니다.
더욱 강력한 기반 뉴럴 네트워크의 출현
어떻든 Self-Attention Net의 성능에 대해서는 어느 정도 증명이 되었다고 볼 수 있고, 그렇다면 이를 능가하는 새로운 기반 뉴럴 네트워크가 또 나올 것인지를 예측해 보는 것도 흥미로울 것 같아 개인적인 의견을 달아봅니다.
어떤 지도 학습(Supervised Learning) 모델(모델 A)의 Power를 측정하기 위한 간단한 접근 방식 중 하나는 샘플을 충분히 많이 확보하여 기준 모델(모델 B)에 적용한 후, 그 결과로 만들어진 데이터를 학습 셋으로 이용하여 모델 A를 다시 학습하고 그 성능이 모델 B와 유사한지 아닌지 보는 것입니다. 만일 성능이 서로 유사하다면 모델 A는 모델 B 보다는 약하지 않다고 판단할 수 있습니다. 그리고 위의 과정을 역으로 진행했을 때 성능이 유사하지 않다면 모델 A가 모델 B보다 나은 성능을 가진다고 말할 수 있습니다.
Transformer는 거의 복사기 수준으로 기존 모델을 모사해냅니다. 이런 면에서 Transformer는 충분히 강력하다고 판단되며 이를 월등히 능가하는 모델은 쉽게 나오기 힘들 것이라고 예상합니다. 모델 간의 경쟁 과정은 거의 수렴 단계로 보이며 따라서 번역에 관련해서는 전혀 새로운 형태의 강자가 나타나기보다, 기존 뉴럴 네트워크를 토대로 더 넓은 문맥을 다루는 모델로 진화해 나가지 않을까 생각됩니다.
Adversarial Neural Machine Translation
글을 마무리하기 전에 Adversarial Neural Machine Translation[11]도 살짝 언급해야 할 것 같습니다. 이 논문에서는 CNN 기반 모델들의 연구가 활발히 이루어지고 있는 동안 전혀 다른 학습 방식을 사용하는 접근도 이루어졌는데요. 지금도 여전히 활발한 연구가 이루어지고 있는 Generative Adversarial Networks(GAN)의 접근 방식을 NMT에 유사하게 적용한 모델입니다. 이 모델은 사람의 번역과의 유사도를 극대화하는 기존 학습 방식 대신 NMT 모델과 사람의 번역을 구별해 내는 CNN 기반의 Adversary Net을 도입하여 둘 사이를 경쟁 관계로 두고 서로 발전해 나갑니다. RNN 기반의 Seq2seq 모델을 토대로 했지만, 새로운 학습 방법을 통해 기존 모델의 성능을 개선한 것입니다.
이처럼 딥러닝의 많은 기본 아이디어들은 그 사용성이 일반적인 경우가 많습니다. 어떤 아이디어가 유효하다면 그 쓰임새가 특정 모델에 국한되지 않는다는 의미죠. 지금까지 살펴보았던 Attention Net, Residual Connection, Positional Encoding 등도 모두 그러한 예입니다. NMT가 짧은 기간 동안 큰 발전을 이루어 왔지만 아직 갈 길이 멉니다. [그림 7]의 구글의 번역 결과를 예로 들어보겠습니다.
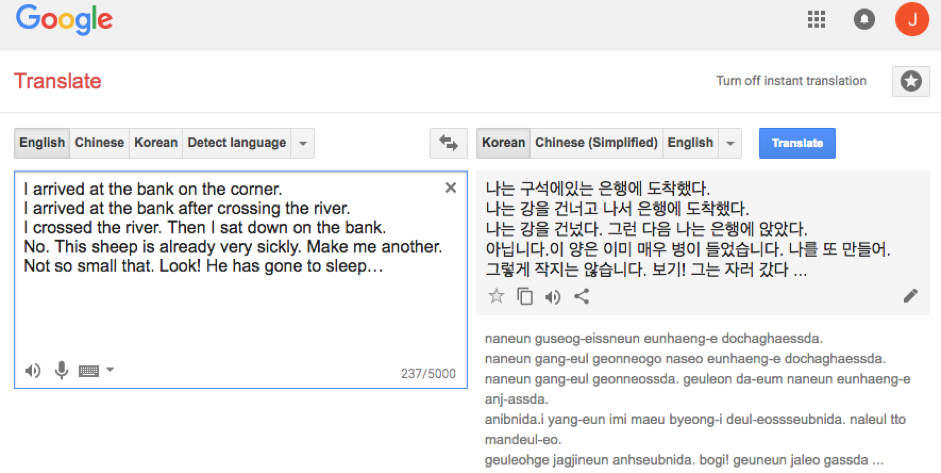
위 [그림 7]의 예에서 river와 같이 쓰인 bank라는 단어는 강둑이라는 뜻이 더 적합합니다. 또 NMT는 Make me another.처럼 대명사가 들어간 문장을 제대로 번역해 내기도 힘듭니다. 구어체에서 많이 나타나는 짧은 어구나 문장들은 앞뒤 문맥을 더 넓게 봐야 정확한 번역이 이뤄질 수 있죠. 카카오에서도 완전히 새로운 형태의 뉴럴 네트워크를 연구하기보다는 잘 동작하는 기존 모델을 기반으로, 문체나 더 넓은 문맥에 초점을 맞춰 모델을 연구하고 있습니다. 위 문장들을 카카오에서 실험 중인 모델로 다시 번역하면 [그림 8]과 같은 결과가 나옵니다.
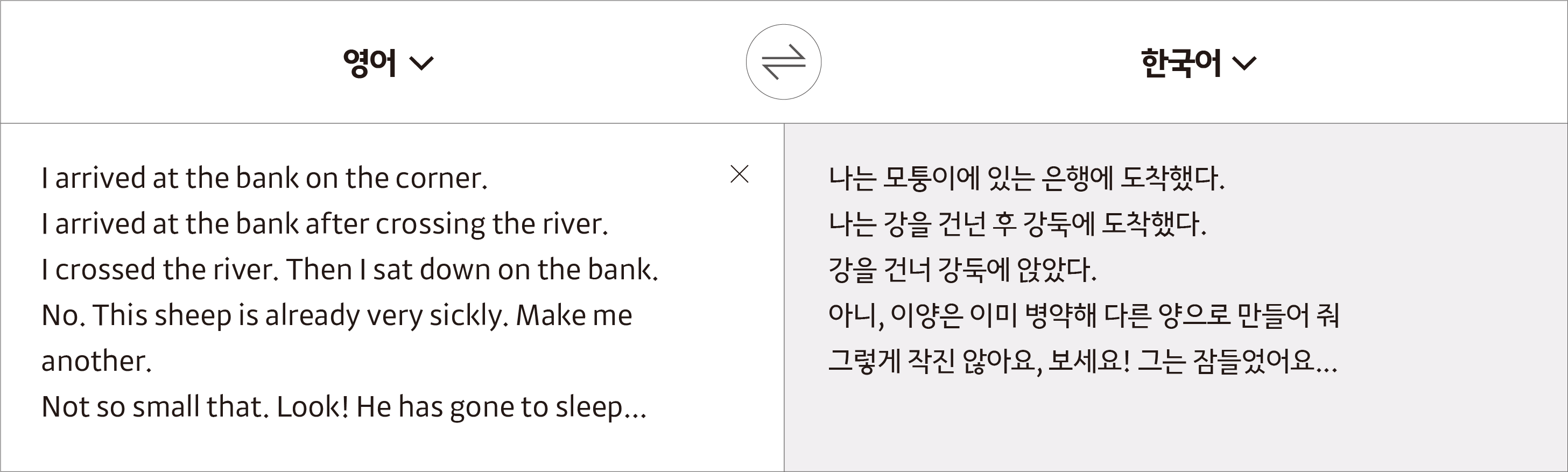
짧은 예시라서 성급한 판단은 이르지만 가능성은 확인할 수 있습니다. [그림 8] 첫 두 문장에서 bank의 번역은 RNN에 비하여 Attention 기반 모델이 문맥을 더 잘 활용하는 예이고, 나머지 번역은 카카오에서 연구 중인 Larger Context 모델로 더 적절한 번역문을 만들어 낸 예시입니다.
마치며
기계 번역이 인간의 수준을 따라잡기는 쉽지 않을 것입니다. 언어는 수천 년간 독립적으로 형성된 문화를 반영하므로 언어 간 1:1 매칭이 되지 않는 번역 규칙이 수없이 존재하기 때문입니다. 정확한 번역은 문화에 대한 이해와 더불어 역사/경제/과학/예술 등의 도메인 지식 또한 필요로 합니다. 인간은 단순히 텍스트 정보로만 번역하는 것이 아니라 수많은 추가 정보를 토대로 논리적인 유추 과정을 거치면서 번역을 하는 것입니다.
다행히 언어는 각 언어 별로 공통적인 규칙이 매우 많기 때문에 현재 기술로도 놀라운 성과를 내고 있습니다. 하지만 궁극의 번역 기술은 AGI(Aritificial General Intelligence) 영역에 속한다고 볼 수 있기에, 수년 내에 완벽한 번역을 해내는 AI를 기대하는 것은 무리입니다. 물론 AGI도 언젠가는 탄생할 것입니다. 아마도 지구적 진화 과정의 시간관념으로는 찰나에 불과하는 시간이 걸리겠지만, 기껏해야 한 세기를 살 수 있는 인간의 관점에서는 긴 시간이겠죠. 언제가 될지 모르는 이 시점에 대한 두려움과 기대감이 교차합니다.
이상으로 2017년 당시 바라본 NMT 모델의 발전 흐름을 소개해드렸습니다. 약 2년이 지난 지금, 과거에 예상했던 기술 전망과 현재를 비교하며 살펴보는 것도 큰 의의가 있으리라 생각합니다. 최근 카카오엔터프라이즈는 Transformer 기반의 Pretraining 기법을 적용하여 기계번역 성능을 향상하려는 노력을 하고 있습니다.
이와 관련된 내용은 이 블로그의 카카오 i 번역 성능 향상 실험 : 대규모 말뭉치를 활용한 사전학습에서 확인할 수 있습니다.
참고 문헌
[1] Sutskever, I. et al. (2014). Sequence to Sequence Learning with Neural Networks. In Proceedings of NIPS.
[2] Cho, K. et al. (2014). Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP 2014).
[3] Bahdanau, D., Cho, K. H., & Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of 3rd International Conference on Learning Representations, ICLR 2015 (pp. 1-15).
[4] Zhou, J. et al. (2016). Deep Recurrent Models with Fast-Forward Connections for Neural Machine Translation. Transactions of the Association for Computational Linguistics, 4, 371-383.
[5] Wu, Y. et al. (2016). Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. Arxiv.
[6] Kalchbrenner, N. et al. (2016). Neural Machine Translation in Linear Time. Arxiv.
[7] Gehring, J. et al. (2017). Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning (pp.1243-1252).
[8] Kaiser, L. et al. (2017). Depthwise Separable Convolutions for Neural Machine Translation. In Proceedings of ICLR.
[9] https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
[10] Vaswani, A. et al. (2017). Attention Is All You Need. In Proceedings of NIPS.
[11] Wu, L. et al. (2018). Adversarial Neural Machine Translation. In Proceedings of ACML.

새로운 길에 도전하는 최고의 Krew들과 함께 해요!

배재경
도전 과제를 찾고 이를 해결해 나가는 것이 재밌고 신나는 개발자입니다. 아이디어를 아낌없이 공유해 주시는 많은 훌륭한 분들이 있어서 세상이 더 빨리 나아지는 것 같습니다. 저도 그 길에 작은 보탬이 되고 싶습니다.