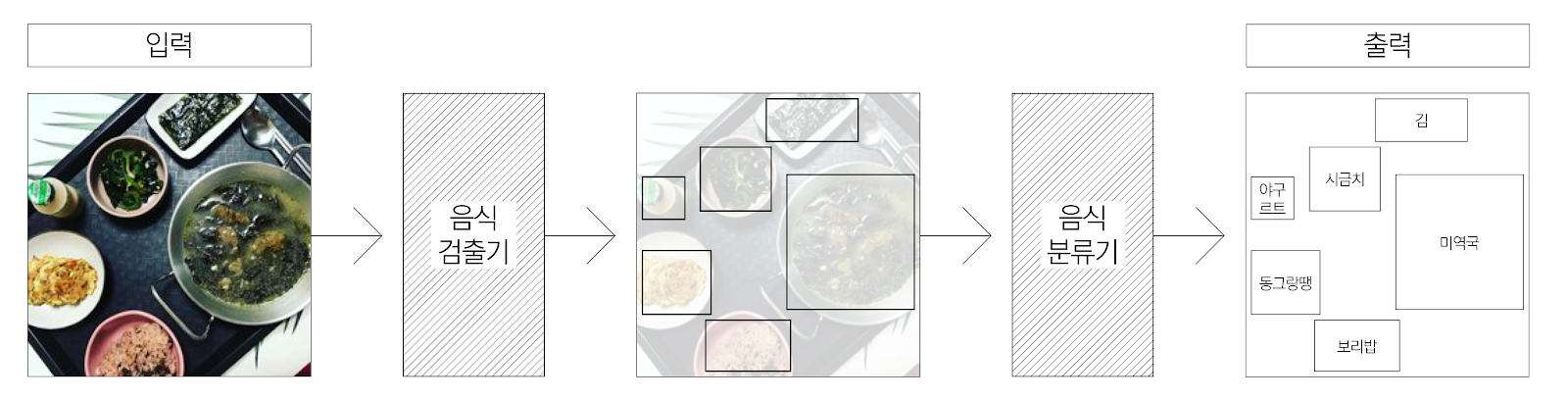
스마트하게 식단을 관리하는 딥러닝 기술
시작하며
많은 전문가는 잘못된 식습관 개선과 꾸준한 운동으로 요요가 없는 체중 감량이 가능하다고 말합니다. 특히 식단 구성에서 잘된 점과 잘못된 점을 분석하고 이를 개선해 점차 영양소가 골고루 들어있는 균형 잡힌 식단을 꾸리는 게 체중 감량에 큰 도움이 된다고 강조하고 있죠. 섭취한 음식 종류와 그 양을 최대한 상세하게 적을수록 감량 효과는 더 커집니다. 다만 문제는, 끼니마다 식단을 꾸준히 기록해나가는 게 생각보다 쉽지 않다는 거죠.
이런 이유로 요즘 다이어트 앱은 사진 속 음식을 자동으로 인식해 섭취 칼로리와 영양학적 정보를 좀 더 쉽게 기록할 수 있게 합니다. 카카오 VX가 만든 ‘스마트홈트’ 또한 사진 속 음식의 이름과 칼로리를 자동으로 입력해주는 식단카메라 기능을 제공하고 있습니다. 이 식사 기록을 토대로 스마트홈트의 AI코치가 적절한 운동과 식단을 제안해줍니다.

이번 글에서는 식단카메라에 적용된 카카오엔터프라이즈 AI Lab(이하 AI Lab)의 음식 인식 기술을 소개해드리고자 합니다. 1,000 여 종을 구분할 수 있는 AI Lab의 음식 인식 모델은 입력 이미지에서 음식 영역을 추출하는 ‘검출기’와 검출된 영역 내 존재하는 음식의 이름을 인식하는 ‘분류기’로 나눠볼 수 있습니다. 이 개발 프로젝트를 이끈 AI Lab AI기술팀 멀티미디어처리파트 소속의 홍은빈 개발자와 이주영 개발자를 만나 검출기와 분류기에 해당하는 딥러닝 모델의 개발 과정에 대해 자세히 들어봤습니다.
☛ Tech Ground 데모 페이지 바로 가기 : 음식 인식 데모
1. 음식 분류기
(1) 데이터셋 수집
AI Lab은 스마트홈트 사용자가 많이 입력할 법한 음식명을 목록화하는 작업을 진행했습니다. 다음(Daum) 검색에 입력되는 음식 관련 요청 쿼리 수가 높은 순서대로 정렬한 목록에서 '안주'나 '소풍도시락'처럼 음식 이름이 아닌 대상은 제외했습니다. 반면, 낫또, 김, 마늘 등 스마트홈트 앱 사용자가 자주 입력하는 음식은 목록에 새롭게 추가했습니다.
그 다음, 준비한 음식별 후보 이미지 수백 장을 몇 가지 기준을 가지고 정제하는 작업을 진행했습니다. 대표적인 기준은 다음과 같습니다. 1) 동일한 음식을 지칭하는 레이블(또는 범주)은 하나로 통일했습니다. 2) 음식을 플레이팅한 방법이 제각기여도 모두 같은 레이블을 붙였습니다. 3) 서로 다른 음식이지만 외관이 비슷하면(large inter-class similarity) 대표 범주만 남기고 나머지는 제거했습니다.
| 1 | - 두루치기와 제육볶음 - 감자볶음과 감자채볶음 - 오징어채볶음과 진미채볶음 - 연어덮밥과 사케동 - 깻잎찜과 깻잎장아찌 |
| 2 | - 만두와 야채가 모두 양념에 버무려진 비빔만두와 야채만 버무려진 비빔만두 |
| 3 | - 아구찜과 대구뽈찜 - 도가니탕과 설렁탕 - 쪽갈비구이와 등갈비구이 - 애호박찌개와 고추장찌개 - 요거트와 라씨 |
(2) 모델 채택 및 훈련
AI Lab은 개발 당시 최신 분류 모델 중 자체 실험에서 가장 높은 성능을 달성한 InceptionV4을 음식 분류를 위한 기반 모델(baseline model)로 활용하고, 추가적인 성능 향상 기법을 탐색했습니다.
1) 최적화 알고리즘(optimizer)
오차를 최소화하는 방향으로 가중치(weight) 값을 수정하는 최적화 알고리즘의 작동 방식은 크게 2가지로 나눌 수 있습니다. 모든 가중치에 동일한 학습률을 적용하는 SGD(Stochastic Gradient Descent) 계열은 일반화(generalization)1에 큰 도움이 되지만 학습 속도가 느립니다. 가중치마다 서로 다른 학습률을 반영하는 ADAM(ADaptive Moment estimation) 계열은 학습 속도는 빠르나, 가중치 값보다 학습률이 지나치게 크거나 작은 상황에서는 일반화가 잘되지 않을 수도 있습니다.
이에 AI Lab은 가중치별 학습률의 최소값과 최대값 범위를 제한해 초반에는 학습 속도가 빠른 ADAM처럼 동작하고, 후반에는 SGD처럼 높은 성능에 안정적으로 수렴하는 Adabound를 선택했습니다. 자체 실험 결과, Adabound는 top-1 정확도2를 0.5%P 올리는 데 영향을 미쳤습니다.
2) 레이블 스무딩(Label Smoothing)
레이블이 잘못 부여된 데이터는 모델 학습에 악영향을 끼칩니다. 하지만 라벨링 데이터를 검수하는 데에는 만만치 않은 시간과 비용이 듭니다. 이 문제를 해결하고자 AI Lab은 정답 범주의 인덱스만 1로 표현하는 대신(one-hot label distribution), 일정한 값을 더하거나 빼는 방식으로 여러 범주의 인덱스에 값을 표시(multi-label distribution)하는 레이블 스무딩(Label Smoothing) 기법을 적용했습니다.
음식 인식과 같은 다범주 모델은 N개의 범주와 완전히 연결된 FC 층(fully connected layer)을 통과 시켜 점수(확률)가 가장 높은 범주를 고릅니다. 그러니까 음식 이미지를 [짜장면, 짬뽕, 라면, 라볶이]로 분류할 때 [0.1, 0.8, 0.03, 0.02]나 [0.2, 0.5, 0.15, 0.15] 모두 짬뽕인 사실에는 변함이 없는 거죠. 레이블 스무딩 또한 top-1 정확도를 0.5%P 올리는 데 영향을 미쳤습니다.
추가로, 이 레이블 스무딩은 잘못된 손실의 영향(overconfident)을 줄여 모델 정규화(regularization)3는 물론, 일반화와 보정(calibration)4 모두에 도움이 되는 것으로 알려져 있습니다.
3) 데이터 어그먼테이션(augmentation)
학습 데이터가 많을수록 딥러닝 모델의 성능이 높아집니다. 목표로 하는 분류 성능을 달성하기에는 충분한 양의 데이터 확보에 어려움을 느낀 AI Lab은 어그먼테이션을 통한 학습 데이터 양을 대폭 늘리는 데 집중했습니다. 어그먼테이션은 이미지를 좌우로 뒤집거나(flipping) 자르는(cropping) 등 데이터에 인위적인 변화를 가하는 방법론을 뜻합니다.
일반적인 머신러닝 모델은 학습 데이터가 범주별로 비슷한 비율로 구성돼 있다고 가정하고 학습을 진행합니다. 하지만 실제 음식 데이터셋의 분포는 그렇지 않았죠(class imbalance). 이처럼 데이터가 불균형한 상황에서는 과적합(overfitting)5이 발생하기가 쉽습니다. 소수 범주에 속한 데이터가 입력됐을 때 다수 범주에 속한 데이터보다 분류 정확도가 낮을 가능성이 높기 때문입니다. 이에 AI Lab은 데이터 수를 절대적으로 늘리기보다는, 범주별 데이터 수를 균일하게 만드는 데 집중했습니다.
사용자는 다양한 촬영 각도로 사진을 찍을 것입니다. 음식의 일부 영역만 촬영할 수도 있죠. 이런 데이터 특징에 착안, AI Lab은 이미지 일부를 무작위로 자르고(random crop), 이미지를 임의의 방향으로 돌리고(random rotation), 이미지를 위아래로 뒤집었습니다(horizontal flip). 음식 이미지에서는 색을 임의로 바꾸지 않아야 합니다. 빨간색 바나나나 검은색 햄버거는 제대로 인식하지 못할 수도 있기 때문입니다. 반면, 실제 음식 사진은 다양한 조도에서 촬영된다는 점은 충분히 추론해볼 만한 부분입니다. 이에 AI Lab은 이미지의 명도만 무작위로 조절(color jittering)6하는 기법을 적용했습니다.
4) 학습률(learning rate)
학습 한 번에 가중치를 얼마나 갱신할지를 정하는 매개변수인 학습률은 딥러닝 모델 훈련에서 중요합니다. 학습률이 지나치게 낮으면 최종 성능에 이르는 데 걸리는 학습 시간이 굉장히 오래 걸릴 뿐만 아니라, 오차가 최소값(global minimum)7이 아닌 극소값(local minimum)8에 수렴하는 문제가 발생합니다. 반면, 학습률이 지나치게 높으면 입력층으로 갈수록 전파되는 오차가 되려 폭증하는 현상으로 인해 최소값을 지나칠 수 있습니다. 최신 기법인 코사인(cosine) 그래프를 따라 학습률을 줄이는 방식으로는 효과를 보지 못한 AI Lab은 일정 에폭(epoch)9 마다 손실(loss) 값이 줄지 않으면 학습률을 1/2씩 줄여나갔습니다.
5) TTA(Test-Time-Augmentation, 테스트 단계에서의 어그먼테이션)
TTA는 각기 서로 다른 어그먼테이션 기법을 적용한 테스트(추론) 데이터를 최종 모델(훈련 데이터와 검증 데이터로 학습을 마친 모델)에 입력하는 방식으로 성능을 끌어올립니다. 마치 서로 다른 어그먼테이션 기법을 적용한 학습 모델을 앙상블(ensemble)10한 것과 비슷한 수준의 성능 향상을 기대해볼 수 있죠. 테스트 데이터를 모델에 여러 차례 입력하기 때문에 정답을 추론하는 시간은 좀 더 길 수는 있습니다. 하지만 최종 모델의 매개변수를 변경하지 않고도 추론 성능을 높일 수 있어 추가 학습에 드는 시간과 비용을 획기적으로 줄이는 데 도움이 됩니다.
AI Lab은 이미지에서 여러 부분을 잘라내고 이를 다시 원본 크기만큼 늘려서 모델에 입력하는 멀티 크롭(multi-crop) 기법을 통해 분류 모델의 성능을 1.29%P(top-1 정확도 기준) 더 높일 수 있었습니다.
(3) 이진 분류기 추가
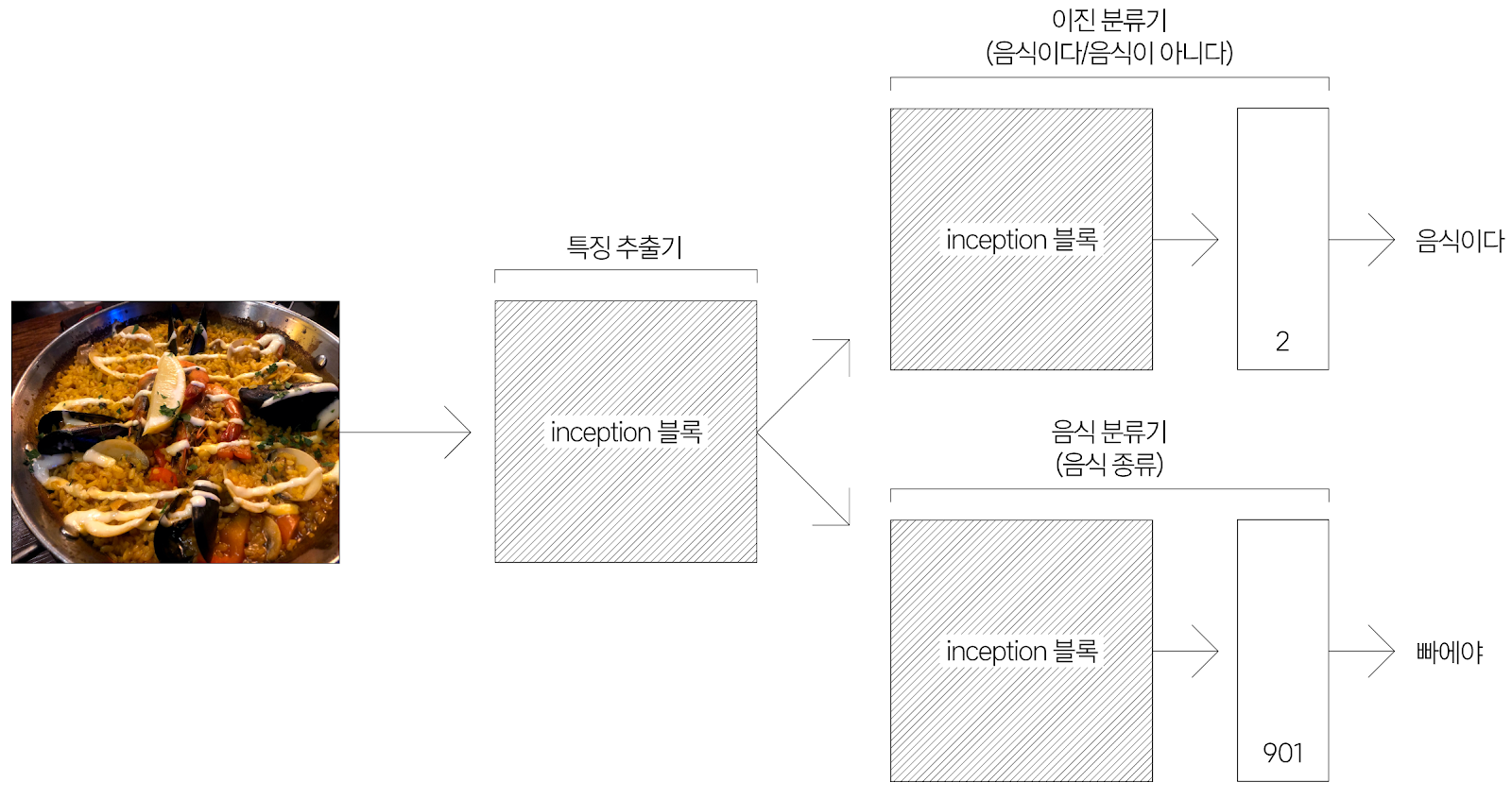
음식 분류기는 100% 완벽하게 동작하지 않습니다. ‘치와와 얼굴’, ‘갈색 털 푸들’, ‘웰시코기 엉덩이’처럼 음식이 아닌 이미지를 각각 ‘블루베리 머핀’, ‘프라이드 치킨’, ‘식빵’으로 잘못 분류할 수도 있기 때문이죠. AI Lab은 음식인 이미지와 음식이 아닌 이미지를 먼저 분류하고 나서(이진 분류기), 음식인 이미지만을 대상으로 음식 분류 결과를 내놓는다면(음식 분류기) 음식 인식 카메라를 향한 사용자 만족도를 한층 더 끌어올릴 수 있을 거라 판단했습니다.

하지만 같은 음식 데이터셋을 학습하는 두 분류기가 배우는 음식 표현(representation)이 서로 비슷할 가능성이 높습니다. 이에 AI Lab은 분류 학습을 완료한 앞쪽 인셉션(Inception) 블록의 가중치를 고정(freezing)하고, 뒤쪽 인셉션 블록의 가중치는 이진 분류 데이터셋(음식이다, 음식이 아니다)으로 미세 조정(fine tuning)11했습니다. 그 결과, AI Lab은 우수한 성능을 내는 이진 분류기를 만들 수 있었습니다.
2. 음식 검출기
(1) 데이터셋 수집
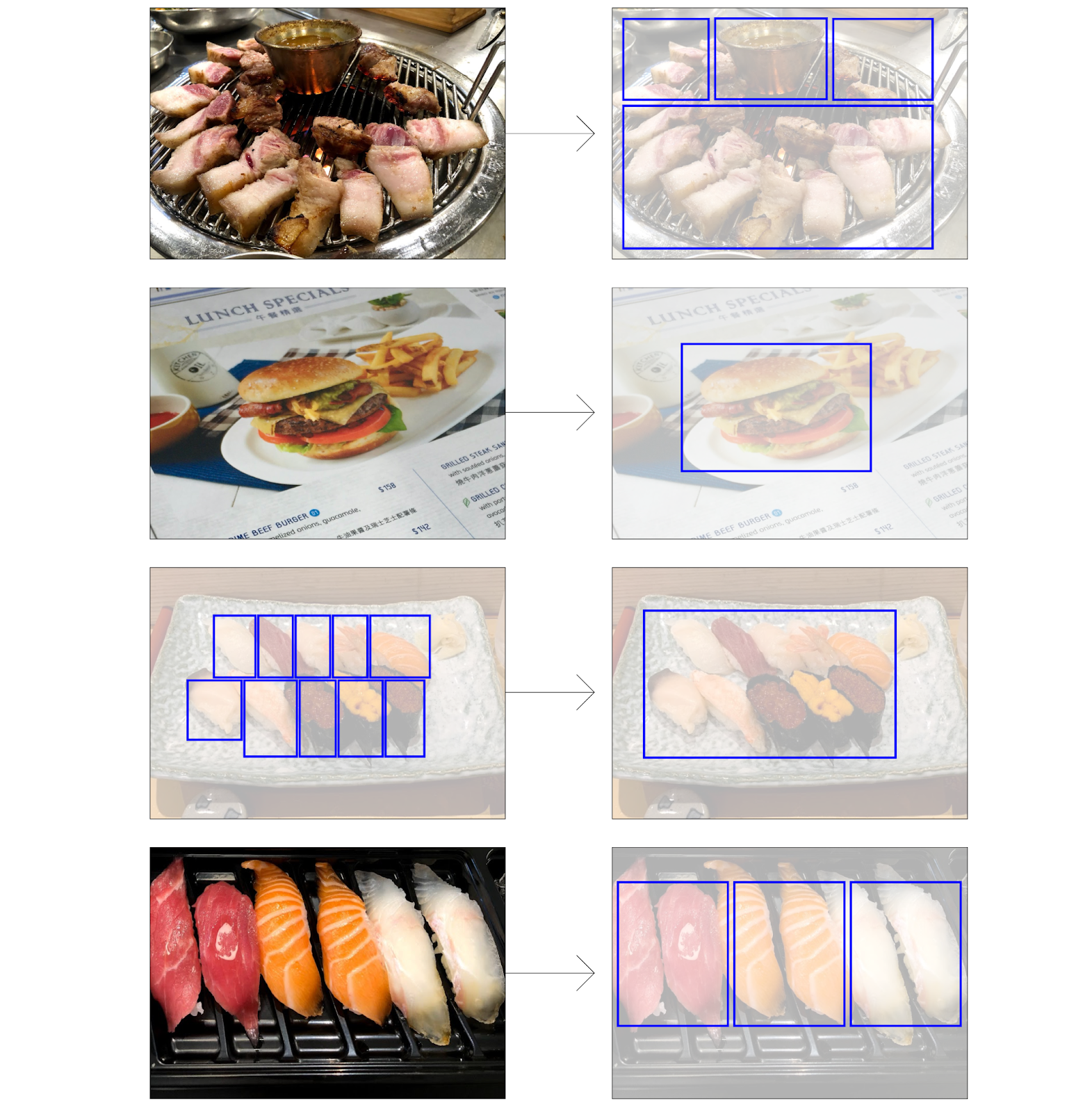
여러 반찬이 함께 놓이는 한국의 상차림 모습은 메인 음식만 놓는 외국(특히 서양)과 다릅니다. 따라서 스마트홈트의 주 사용자층인 한국인이 즐기는 밥상 이미지로 모델을 훈련할 필요가 있었습니다. AI Lab은 한국인 밥상 이미지를 별도로 수집하고 음식에 해당하는 영역을 박스 형태(bounding box)12로 표시했습니다.
음식 안에 또 다른 음식이 있는 영역은 한 가지 음식만 포함될 수 있도록 박스 영역을 나눠서 표시했습니다. 공산품 포장지에 인쇄된 음식 영역에도 박스를 표시했습니다. 모둠 음식(모둠 초밥, 모둠전, 모둠회)이 서로 다른 하위 음식으로 구성되면 이를 하나의 박스로 표시했습니다. 단, 동일한 하위 음식이 2개 이상 모여 있으면 음식마다 박스를 따로 표시했습니다.
(2) 모델 채택 및 훈련
AI Lab이 채택한 당시 최고 수준의 검출 모델은 음식 간 관계를 고려하지 못하거나, 인식해야 하는 음식의 박스 영역이 옆 음식 영역과 약간 겹치는 이유로 음식을 잘못 분류했습니다. 예를 들면, 샐러드 식단에 함께 나온 요거트를 막걸리로 잘못 분류하거나, 꼬리곰탕 박스 영역과 부추 부침 박스 영역이 겹치면 부추 부침을 순대국으로 분류13하는 식이였던 거죠.
첫번째 문제를 해결하고자 AI Lab은 이미지의 특정 객체를 어떤 음식과 함께 나오는지를 보고 분류하는 맥락 인지(context-aware) 모델을 새로 구성했습니다. 여러 음식 간의 상관관계 정보를 담는 전역적 특징(global feature)과 오려진 이미지(각각의 음식)에 대한 고유의 정보를 담는 국소적 특징(local feature)을 분리해서 추출할 수 있도록 한거죠. 그리고 다시 두 벡터를 서로 이어 붙여서(channel-wise concatenation) 음식 분류기에 입력하면 이미지를 좀 더 정확하게 인식할 수 있게 됩니다.
두번째 문제는 음식 분류기가 특징을 추출하는 과정에서 박스의 중심부(내용물)에 더 집중하도록 어텐션(attention)14 모듈을 추가하는 방식으로 해결했습니다. AI Lab은 어텐션 모듈의 효과를 알아보고자 3번째, 7번째, 9번째, 11번째 모듈이 처리한 결과를 히트맵(heat map)15으로 나타냈습니다. 초중반 블록에 삽입한 모듈과는 달리, 10번째와 11번째 어텐션 모듈에서는 의미가 있는 특징을 뽑아냄을 확인할 수 있었습니다. AI Lab은 10번째와 11번째 어텐션 모듈만 남기고 나머지는 제거했습니다.

추가적인 성능 향상을 위해 검출된 음식 박스를 적절하게 오려내는 기법에 관한 실험을 진행한 결과, 1.1배 크기의 박스에 멀티 크롭 기법을 적용하는 방식이 1배 크기의 박스를 오려내는 방식(single scale)보다 top-1 정확도가 1.3%P 더 높음을 확인할 수 있었습니다.
한층 더 심화된 음식 관계 표현을 위해 다양한 형태의 이미지도 추가로 수집했습니다. 예로 들어, 족발과 함께 먹는 막국수의 인식률은 상대적으로 더 낮았는데 이는 수집된 이미지에 족발과 함께 오는 ‘쟁반 막국수’가 포함하지 않아 발생한 문제로 판단했습니다. 이에 ‘족발집 막국수’, ‘배달 막국수’라는 키워드로 수집한 이미지를 새로 추가해 음식 인식률을 높였습니다.
향후 계획
카카오 VX에서 제공한 테스트용 이미지를 가지고 음식 인식 모델의 성능을 측정한 결과, 기본 모델과 비교했을 때 AI Lab이 새롭게 제안한 어텐션 모듈 기반 맥락 인지 모델은 음식 인식의 성능을 크게 높이는 데 성공했습니다.
앞으로 AI Lab은 ‘더 많은’ 음식을 '더 정확하게’ 인식하는 기술을 만들어갈 계획입니다. 핵심은 다양한 학습 데이터셋을 대량 확보하는 데 있습니다. AI Lab은 밝은 조명이 있는 스튜디오 촬영 이미지 뿐만 아니라, 다양한 화각과 밝기에서 찍힌 사용자 제공 이미지도 학습 데이터로 활용할 계획입니다. 스마트홈트 앱에서 인식에 실패한 음식 사진의 태그를 사용자가 직접 수정하는 기능이 있어 정답 레이블이나 수요가 높은 새로운 범주의 음식 정보를 획득하기가 수월할 것으로 보입니다. 최근에 나온 다양한 어그먼테이션 기법(cutout, cutmix 등)의 유효성을 확인하는 실험도 병행될 예정입니다. 이미지 분류 및 객체 인식 관련한 최신의 모델과 자체 구축한 음식 데이터셋을 이용한 성능 향상 실험도 진행할 계획입니다.

이수경(Samantha) | 작성,편집
지난 2016년 3월 알파고와 이세돌 9단이 펼치는 세기의 대결을 취재한 것을 계기로 인공지능 세계에 큰 매력을 느꼈습니다. 현재 카카오엔터프라이즈에서는 딥러닝 전문가와 함께 인공지능을 제대로 이해하고픈 대중을 위한 콘텐츠를 쓰고 있습니다. 인공지능을 만드는 사람들의 이야기와 인공지능이 바꿀 미래 사회에 대한 글은 누구보다 쉽고, 재미있게 쓰는 사람이 되고자 합니다.

홍은빈(Erin) | 작성, 감수
대학원에서 딥러닝을 이용한 영상처리를 공부하면서, ‘논문’을 쓰기 위한 연구가 아닌, 실생활에 도움이 되는 기술을 만드려는 꿈을 꾸게 됐습니다. 이런 연구 경험을 바탕으로 현재 카카오엔터프라이즈에서는 이미지와 동영상을 이해하는 딥러닝 기술을 이용해 서비스를 개발하는 일을 담당하고 있습니다. 앞으로 사람보다 더 많은 걸 볼 수 있는 인공지능을 만들고 싶습니다.

이주영(Michael) | 감수
카카오엔터프라이즈에서 쇼핑∙검색 이미지 분석 관련 연구∙개발 조직을 맡고 있습니다. 많은 사람이 즐겁게 이용할 수 있는 인공지능 기술을 만들고 싶습니다.
- 학습 데이터와 조금이라도 다른 성격의 테스트 데이터가 입력되어도 모델이 잘 동작하는 상태를 가리킨다. [본문으로]
- 가장 높은 확률로 추정된 범주가 실제 정답과 일치하는 정도를 나타내는 성능 평가 지표 [본문으로]
- 설명력이 높으면서도 그 구조가 간단한 모델의 상태를 이르는 말 [본문으로]
- 예측값과 실제 관측값이 일치하는 정도를 이르는 말 [본문으로]
- 모델이 훈련 데이터에 지나치게 적응해버려, 한 번도 학습하지 않은 새로운 데이터에는 제대로 반응하지 못하는 현상 [본문으로]
- 이미지의 색상 채도, 명도를 랜덤으로 조절한다. [본문으로]
- 모든 점이 가지는 함수값 이하의 함수값 [본문으로]
- 주위의 점이 가지는 함수값 이하의 함수값 [본문으로]
- 주어진 훈련 데이터를 여러번 반복해서 보는 횟수를 가리킨다. 에폭을 늘리면 모델의 성능이 좋아진다. 하지만 특정 구간에 이르면 모델의 성능은 더 좋아지지 않는다. 반복학습을 거쳐 주어진 모델과 학습 전략에서 찾을 수 있는 가장 최소의 오차를 내는 것으로 추정되는 가중치 집합을 찾았기 때문이다. [본문으로]
- 독립적으로 훈련한 여러 개의 모델의 결과를 종합해 최종 성능을 평가하는 방법을 의미한다. 보통은 다수결의 원칙에 따라 예측 결과를 결정한다. [본문으로]
- 모델의 가중치 값을 세세하게 조정하는 과정을 가리킨다. [본문으로]
- 이미지에서 특정 범주의 객체가 포함된 직사각형 모양의 상자로, 경계 박스라고 한다. [본문으로]
- 이러한 결과는 순대국에 부추를 수북이 얹혀 놓은 사진을 학습했기 때문으로 분석된다. [본문으로]
- 인코더(encoder)와 디코더(decoder) 구조의 모델이 특정 시퀀스(sequence)를 디코딩할 때 관련된 인코딩 결과값을 참조할 수 있게 하는 기법 [본문으로]
- 이미지 위에 열분포 형태처럼 색상으로 다양한 정보를 표현하는 방법. 대표적으로 웹로그 분석에서 웹페이지 방문자가 마우스를 클릭한 영역을 이 방식으로 보여준다. 클릭이 많이 발생할수록 붉게, 클릭이 적게 발생할수록 푸르게 표현한다. [본문으로]