



사람들은 왜 AI에게 화를 내는가?
안녕하세요. 지난번 카카오 i의 작고 소중한 힐링 포스팅에서 힐링 사운드에 대해 소개드렸던 AI 기획팀 레아라고 합니다. 이번 포스팅에서는 내부에서 ‘사오정’이라 칭하는 음성인식 개선 프로젝트에 대해 소개하고자 합니다.
여러분은 AI 스피커에게 화내본 경험이 있나요? 혹은 주변의 누군가가 AI와 대화 중 급발진 하는 모습을 목격한적 있나요? (제겐 너무 흔한 일입니다만...🙄)
헤이헤이! 거기 있어요? 대답 없는 너.
아니... 그거 말고! 동문서답 하는 너.
또 이해하기 어렵다고? 똑똑한거 맞니 너….😂

왜 기계에게 화를 내냐구요?
우리는 인간을 닮았다는 인공지능이 진짜 인간처럼 대화하길 기대합니다. 부르면 재깍 반응하고, 뻔한 품사쯤 생략해도 맥락을 이해하고, 살짝 틀려도 새겨듣고, 이전 대화를 기억하기를... 별 거 아닌 ─사실은 별 거인─ 기대가 무너지기 때문이겠죠.
이러한 대화 스킬을 알고리즘으로 구현해 내는 것이 인공지능의 중대한 과제입니다. 제 아무리 뛰어난 기술이라도 대화를 ‘이해’하고, ‘추론’하는 단계를 거쳐야 비로소 사람과 소통할 수 있으니까요.
카카오 i는 음성인식, 자연어 이해, 추론, 학습, 검색 등 여러 분야에서 연구를 지속하고 있는데요. 화자의 의도를 추론하고 적중률을 높이는 검색 기법 중 하나가 바로 ‘사오정’ 모델입니다. 이름과는 역설적이게도 대충 말해도 찰떡 같이 알아 듣는 스킬을 가진.
기존 웹 검색 vs 음성 검색의 차이
사오정의 역할을 이해하기 위해 먼저 기존 웹 검색과 음성 검색의 차이를 이야기 해보려 합니다.

위 그림과 같이 카카오 i 음악 검색에서는 발화에서 ‘핵심 키워드’를 추출하고, 그 정보를 ‘검색'하게 되는데요. 검색 엔진의 코어 알고리즘은 기존과 크게 다르지 않습니다. 하지만 음성 검색에는 디스플레이가 없기 때문에 여러 개의 답변 후보를 제시하고, 결과를 재가공할 수 있는 탐색 기법에 한계를 가집니다.
(1) 화면이 없는 음성 검색의 한계는? 🤔
- 여러 후보군 또는 컬렉션을 제시할 수 없음. 즉, 첫번째 검색 결과가 만족도 기준에 절대적 역할을 함
- 검색어를 유추하고 추천해주는 자동완성 서제스트를 제공할 수 없음
- 연관/가이드 검색어를 제시할 수 없음
- 오타(오발화) 교정 기능을 제공할 수 없음
- 범주를 좁혀나갈 수 있는 필터 기능을 제공할 수 없음

(2) 이러한 기법의 차이가 어떤 결과를 초래할까? 🤔
실제로 이러한 한계점이 품질에 어떤 영향을 미치는지 확인하기 위해, ‘음악’과 ‘장소’ 검색의 몇 가지 샘플을 살펴보았습니다.
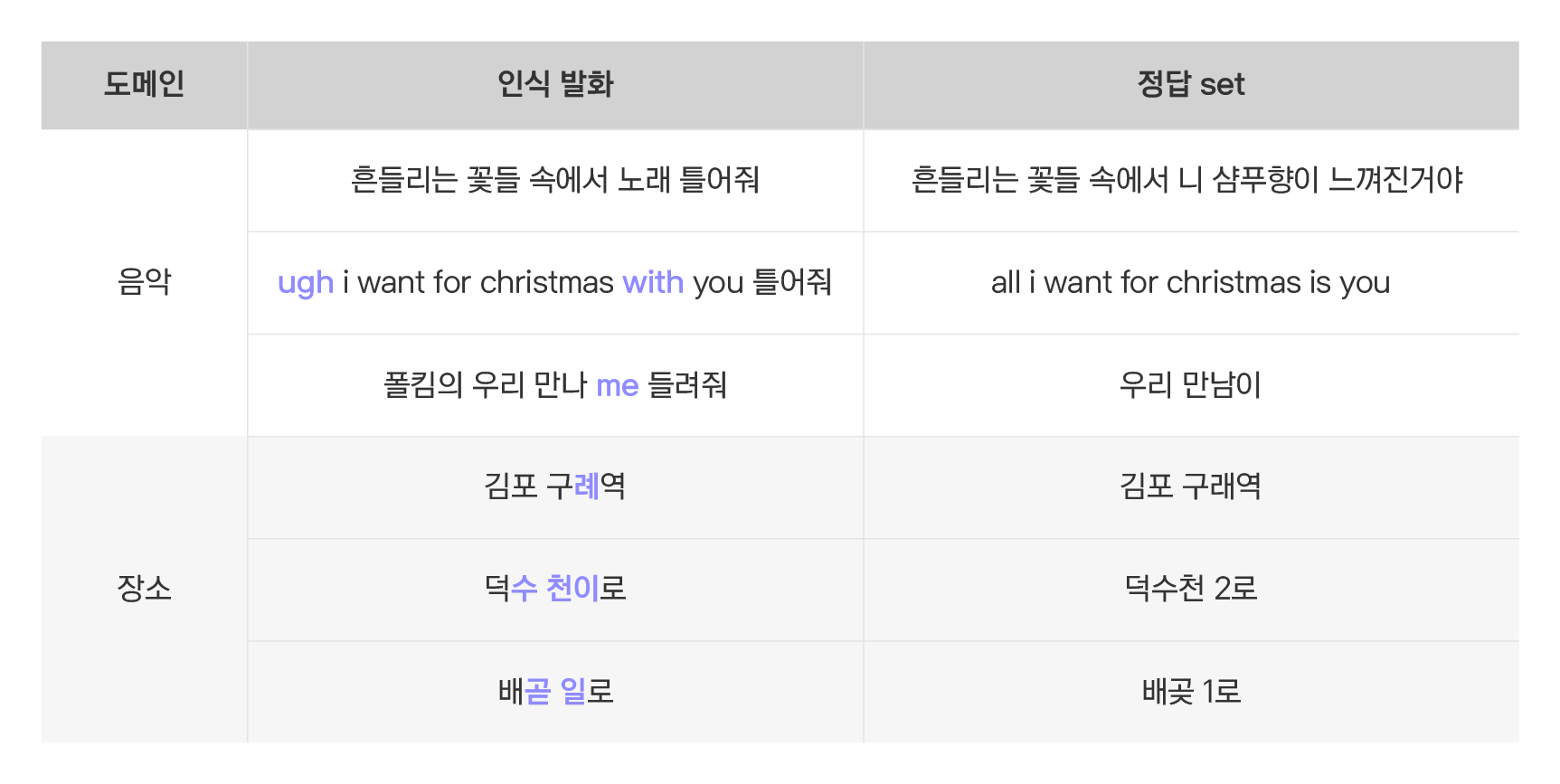
문자열 한 끗 차이로 실패한 맴찢 발화들입니다. 사용자가 잘못 발화하거나, 음성 인식 단계에서 인식 실패하는 경우도 있는데요. 앞서 말씀드린 suggest, 오타 교정, 연관 검색어만 있었더라면・・・ 구제할 수 있는 것들이 눈에 띕니다.
음성을 텍스트로 변환하고(Speech To Text, STT) 데이터를 추출하는(Slot tagging) 등 전처리 단계는 더 복잡해졌는데 다양한 후보조차 줄 수 없다니 😱 그렇다고 음성으로 줄줄이 다른 정답을 늘어놓는다면 우리 사이는 3000만큼 더 멀어질지도 모릅니다. 😂
AI Suggest 눈치 빠른 사오정
이러한 안타까운 실패를 구제하기 위해 기존의 검색 기법을 응용한 기술이 바로 사오정 모델입니다.
추출한 핵심 정보를 기반으로 의도를 추론하여 정답을 제시하는 일종의 추천–suggest 음성 버전이라고 할까요?
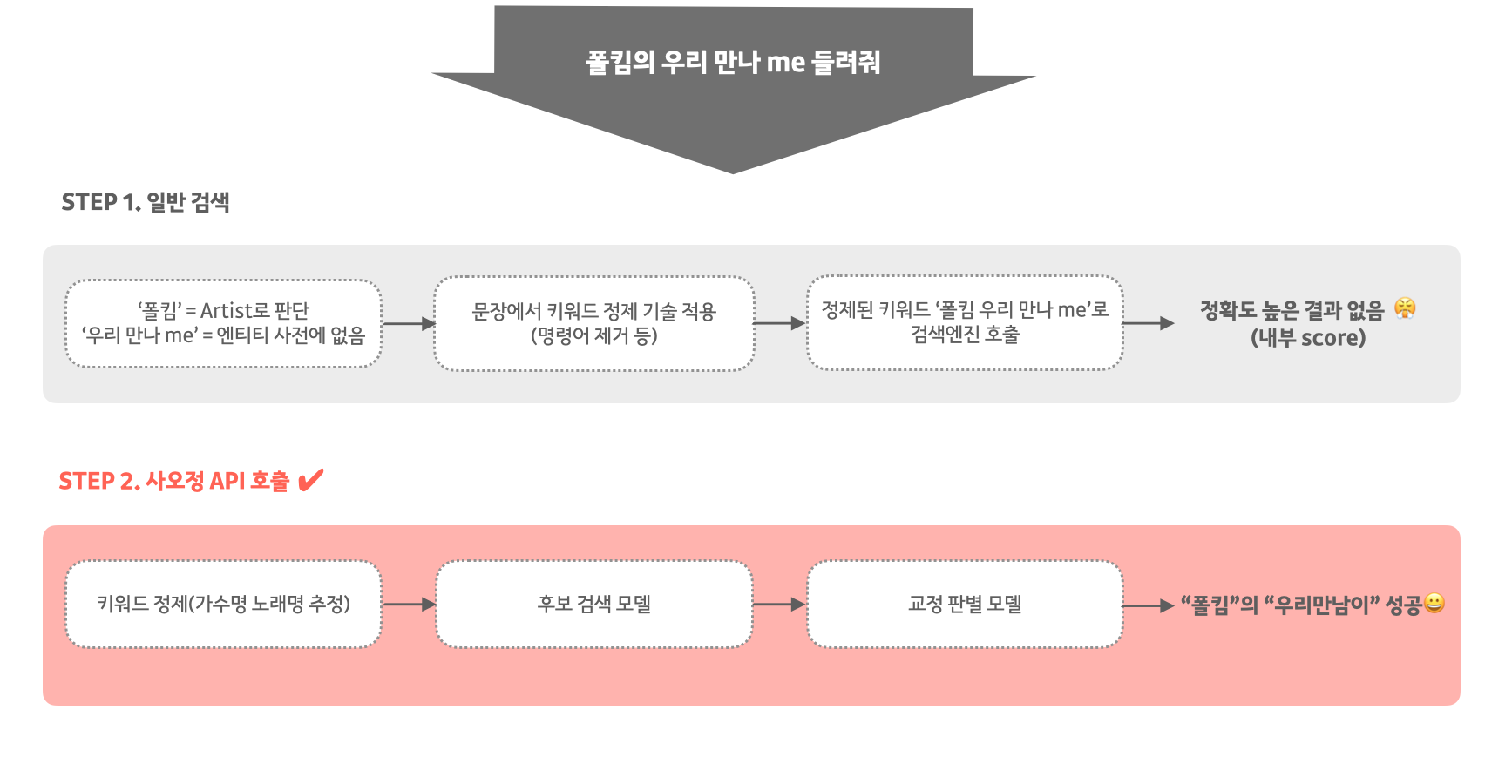
앞서 말씀드린 것처럼 카카오 i 엔진의 기술은 복잡하고 세분화된 레이어로 구성되어 있는데요. 다양한 기술을 거쳐 마지막 일반 검색 단계에서 품질을 담보하지 못할 때, 구원투수 사오정 API가 등장합니다.
사오정 API에서는 발화에서 핵심 정보를 추정 ・ 정제하고, 후보 검색 모델과 교정 판별 모델을 거쳐서 교정 결과를 제공합니다. ‘후보 검색 모델’에서는 찾았을 가능성이 높은 정답 후보를 만들고, ‘교정 판별 모델’에서 자질과 신뢰도를 검증하여 적중률을 높입니다.
사용자의 의도를 ‘예측'하는 기능인만큼 신뢰도가 매우 중요하기 때문에 문자열 유사도, 콘텐츠의 인기도, 최신성 등 다양한 요소를 지속적으로 튜닝하여 최적의 랭킹을 만들고 있습니다. 현재는 콘텐츠 자체 유사도만 판별하지만, 실제 사용자의 사용 패턴을 학습하여 모델에 적용하는 기술도 준비하고 있습니다. 예를 들면 유저의 실패 발화를 기점으로 전후의 발화 및 성공 여부에 따라 인과 관계를 찾아가는 방식입니다.

단, 사용자가 후보 선택하는 과정 없이 자체 처리하는 방식이기 때문에, 과교정하지 않도록 유의해야 합니다. 보수적 관점에서 정교한 정책 설계가 필요한 부분입니다.
사오정! 그 활동 무대를 넓혀 나갈 것
기획파트에서는 장기적으로 크게 두 가지 관점에서 Next Step을 고민하고 있습니다.
하나는 디스플레이가 없는 음성 검색 인터페이스의 한계를 어떻게 극복할 수 있을까 하는 UX 관점입니다.
음성에서도 여러 개의 정답 후보를 유연하게 제안하고, 원하는 검색 결과를 좁혀나갈 수 있는 장치를 제공하고, 축적된 데이터를 활용하여 내일이 더 기대되는– 사람과 AI가 더 인터렉티브하게 소통하는 방법을 찾고 있습니다.
다음은 사오정 모델의 적용 도메인 확대입니다. 현재는 사용 빈도가 가장 높은 음악 도메인에서 주로 사용하고 있지만 더 많은 도메인으로 확대할 경우 서비스 전반의 품질을 높일 수 있을 것입니다.
특히나 모빌리티 도메인의 경우에는 Use Case가 명확하고, 인식이 까다로운 장소와 주소 데이터를 다루기 때문에 그 품질 개선 효과도 높을 것으로 예상됩니다. ‘좋은 알고리즘은 널리 쓰여야 사용자를 이롭게 한다’는 말도 있구요. (...없나요?🙄)
눈치 빠른 사오정 덕에 AI와 더 다정해질 날을 기약하며!! 기획썰을 마칩니다.
후보를 선정하고 자질을 판단하는 자세한 구현 기술이 궁금하신 분들은 아래 글을 클릭해서 읽어보세요. 😍
📍이 글과 함께 보면 좋아요!
✓ 사오정 - 음악 재생 발화는 내게 맡겨주세요. [기술편]

최예진(Rhea)
궁금한 게 많아서 먹고 싶은 것도 많은 INFP=조용한 꾸러기=획자 입니다.




댓글