



시작하며
안녕하세요. 카카오엔터프라이즈에서 검색 서비스를 개발하고 있는 검색클라우드기술파트의 Sam(김삼영)입니다.
지난 글 서비스 개발자를 위한 컨테이너 뽀개기 (a.k.a 컨테이너 인터널)에서 예고해 드린 대로 이번 글부터는 서비스 개발자를 위한 컨테이너에 대해 본격적으로 파헤쳐보겠습니다. 컨테이너의 기원부터 발전과정을 하나씩 살펴보며 직접 핸즈온을 통해 들여다보려 하니 가능하시다면 실습환경을 미리 준비해주세요. 실습환경은 GitHub에 자세히 설명해두었습니다. 그럼 긴 여정의 첫걸음을 시작해볼까요?
컨테이너 맛보기
본격적으로 컨테이너(Container)를 만들어보기 전에, 도커(Docker)를 이용하여 컨테이너를 생성해보고 어떻게 생겼는지 한번 살펴보겠습니다. 후반부에 직접 만든 컨테이너 네임스페이스들과 비교해서 보겠습니다.
도커로 컨테이너 생성하기
먼저 하단의 docker 명령어로 busybox 컨테이너를 실행합니다.
root@ubuntu1804:~# docker container run -it --rm busybox:latest

docker 명령어는 아래 그림의 클라이언트(Client)에 해당하는데요. 클라이언트가 컨테이너 실행(run)을 요청하면 도커 데몬(Docker daemon)은 먼저 DOCKER_HOST(로컬 혹은 원격 서버)에 해당 이미지가 있는지 확인하고, 없으면 이미지 저장소(Registry)로부터 이미지를 다운로드하여 컨테이너를 실행합니다.

"컨테이너를 실행합니다."라는 표현은 많은 일들을 포함합니다. 이전 포스팅에서 설명드렸듯이 프로세스가 입주할 격리된 공간에 "이미지"로 패키징된 이삿짐들을 풀어놓고, 네트워크(Network)도 구성하고, CPU나 Memory, IO 등 각종 리소스를 할당하여 프로세스를 실행합니다.

busybox 컨테이너와 호스트
지금부터는 도커로 생성한 busybox 컨테이너 내부와 호스트를 비교해 보도록 하겠습니다.
루트 디렉터리(/)는 유닉스 계열 OS에서 “디렉터리 트리 구조”의 최상위로, 모든 디렉터리 브랜치의 시작점입니다. 루트 디렉터리(root directory)는 루트(/) 파일시스템이라는 특별한 파일시스템이 마운트(mount)됩니다. 루트 파일시스템은 다른 모든 파일시스템들이 마운트되는 최상위 파일시스템으로, 커널의 동작이나 모니터링 등에 사용되는 여러 특수한 디렉터리들이 포함되어 있습니다. (위키 참조)
컨테이너와 호스트의 루트 디렉터리를 비교해보면 포함된 파일 및 폴더 구성이 다르다는 것을 알 수 있습니다. chroot와 pivot_root에서 자세히 살펴보겠습니다.

df(display filesystems) 명령어는 파일시스템 정보와 디스크 사용량, 마운트 정보를 출력합니다. "Mounted on"칼럼에서 루트 디렉터리(/)를 찾아 비교해보면 컨테이너와 호스트의 루트 파일시스템이 다릅니다. 루트 파일시스템 외에도 파일시스템 구성이나 마운트 정보가 다른 것을 확인할 수 있습니다. pivot_root와 마운트 네임스페이스에서 자세히 살펴보겠습니다.

hostname 명령어를 이용하여 컨테이너와 호스트의 이름을 비교해 보세요. "내 방"이라고 문패를 달아 놓는 것처럼 컨테이너를 식별하기 위해 UTS 네임스페이스를 사용하면 컨테이너의 이름을 호스트와 다르게 부여할 수 있습니다. UTS 네임스페이스에서 자세히 살펴보겠습니다.

ps 명령어로 컨테이너와 호스트의 실행 중인 프로세스 목록을 비교해보세요. 서로 다른 OS 위에서 구동되는 것처럼 프로세스 목록이 다릅니다. PID(Process ID) 네임스페이스에서 자세히 살펴보겠습니다.

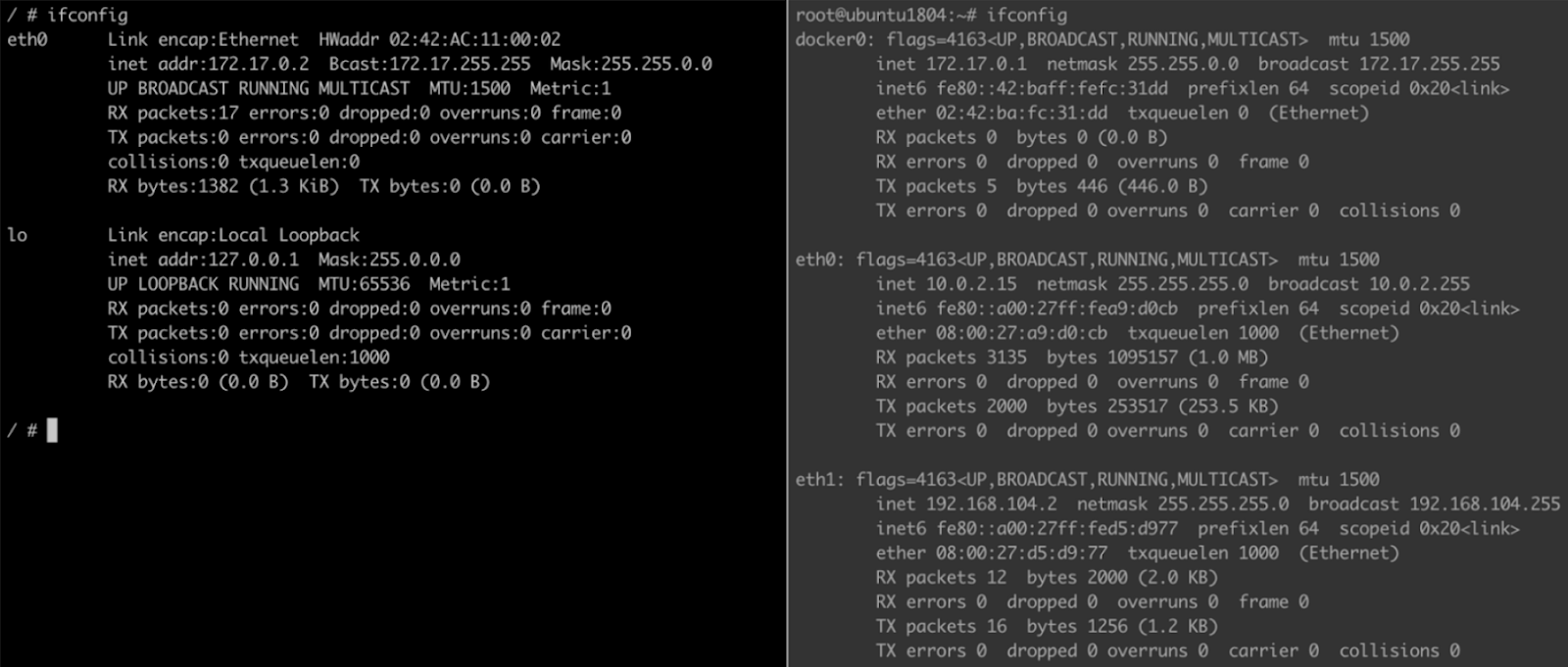
ifconfig 명령어로 네트워크 디바이스(인터페이스)를 조회하여 호스트와 비교해보면 디바이스 종류와 개수, IP 설정 등이 다릅니다. 네트워크 구성이 다르면 어떻게 통신이 이루어질까요? 네트워크 네임스페이스에서 자세히 살펴보며 분산 환경에서 컨테이너 네트워크가 동작하는 방법에 대해 알아보겠습니다.
id 명령어로 현재 프로세스의 유저/그룹 정보를 확인해 보세요. 유저 및 그룹 정보로 프로세스의 시스템 및 파일에 대한 접근권한을 제어할 수 있습니다. 뒤에서 컨테이너의 보안과 관련된 사용자, 그룹, 권한 등을 격리하는 USER 네임스페이스에 대해서도 다루게 됩니다.

도커로 실행한 컨테이너 내부는 루트 디렉터리나 파일시스템, 실행 중인 프로세스 목록, 네트워크 디바이스 구성 등 호스트의 환경과 다르다는 것을 알 수 있습니다. 컨테이너의 환경은 애플리케이션을 실행하는데 맞춰진 환경입니다. 컨테이너 환경은 가상 머신의 운영체제와 매우 유사해 보이는데 지금부터 그 이유를 천천히 알아보겠습니다.
컨테이너의 기원 chroot
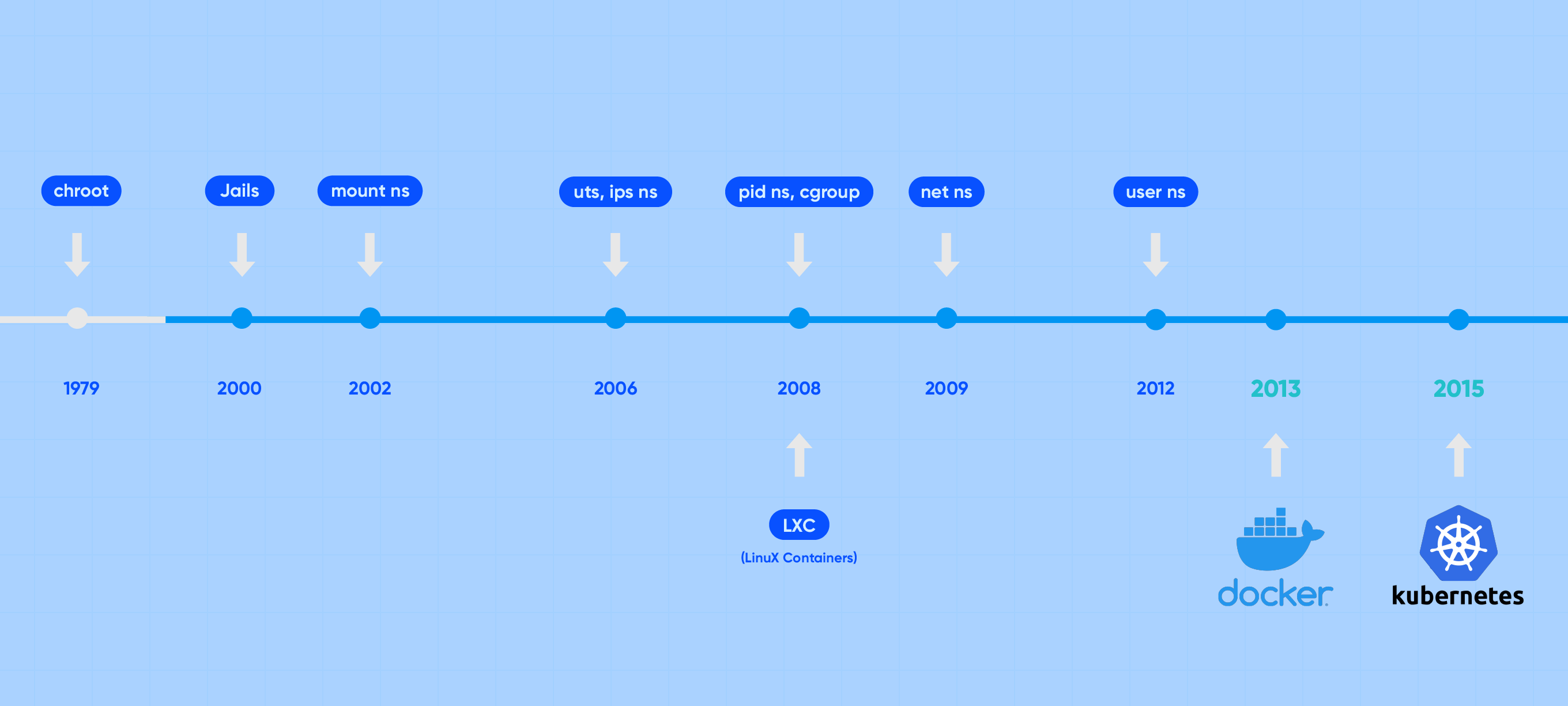
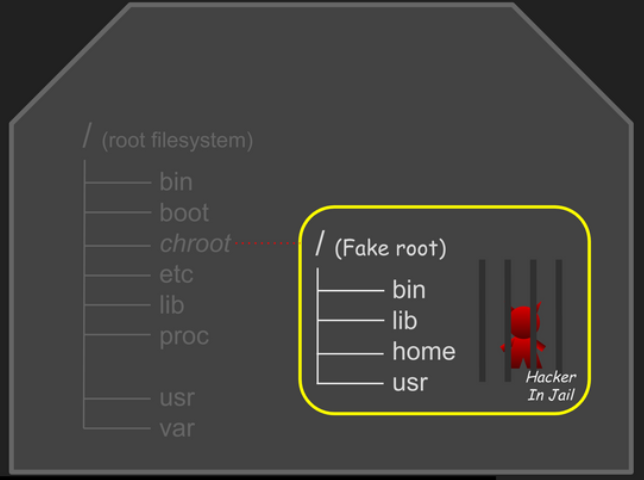
컨테이너의 역사를 거슬러 올라가면 제일 처음 chroot가 등장합니다. chroot는 프로세스의 루트 디렉터리를 변경하는 리눅스 시스템콜/명령어로, 1979년 UNIX V7에서 추가되어 원격 유저(FTP, SSH 등)를 특정 디렉터리에 가두기 위한 용도로 사용되었습니다. chroot는 Change Root Directory의 줄임말로, 특정 디렉터리를 “루트 디렉터리”로 지정할 수 있으면 루트 디렉터리 밖으로는 못 나가기 때문에 해당 경로에 프로세스를 가둘 수 있다는 점에 착안하였습니다. chroot에 갇힌 프로세스는 현재 디렉터리를 루트로 인지하여 작동하기에 프로세스를 실행할 때 필요한 커맨드 프로그램, 라이브러리, 설정 등을 chroot로 지정할 경로에 함께 넣어 주어야 합니다.
사실, chroot를 직접 사용할 일은 별로 없을 겁니다. 하지만 chroot를 사용해보면 리눅스에서 프로세스를 격리하는 기본적인 방법을 직접 경험해 볼 수 있어 컨테이너 원리를 이해하는 데 큰 도움이 됩니다. chroot는 bash, ls 프로그램이나 이미지(nginx)를 가져다가 실행하는 방식으로 사용할 수 있습니다. 이어서 자세히 알아보겠습니다.
Bash, Is로 chroot 사용하기
먼저 bash, ls 프로그램을 한 땀 한 땀 복사하여 chroot로 실행하는 방법에 대해 알아보겠습니다.
chroot 로 bash 셸 실행하기
1. chroot로 Bash 셸(shell)을 실행하기 위해 change할 루트(NEWROOT)를 지정하고, NEWROOT를 기준으로 실행할 "커맨드"를 인자로 줘 실행합니다. “커맨드"를 지정하지 않는 경우, env($SHELL)에 정의된 셸이 실행됩니다.
2. NEWROOT로 사용할 디렉터리(new-root)를 만들고 chroot를 실행해 보겠습니다. 실습은 /tmp 경로에서 진행합니다.
# 실습 경로로 이동해 주세요
root@ubuntu1804:~# cd /tmp
# 루트로 사용할 디렉터리를 만듭니다.
root@ubuntu1804:/tmp# mkdir new-root
# chroot로 new-root를 루트 디렉터리로 지정하여 /bin/bash를 실행합니다.
root@ubuntu1804:/tmp# chroot new-root /bin/bash
chroot: failed to run command '/bin/bash': No such file or directory
3. 실행 시 에러 메시지가 출력됩니다. chroot에서 지정한 루트 디렉터리를 기준으로 "커맨드"(/bin/bash)를 찾기 때문에 (인자로 넘기는) "커맨드"가 new-root 밑에 있어야 합니다.
# bash 커맨드의 위치를 확인한 후
root@ubuntu1804:/tmp# which bash
/bin/bash
# 동일한 경로를 만들고 복사해 줍니다.
root@ubuntu1804:/tmp# mkdir -p new-root/bin
root@ubuntu1804:/tmp# cp /bin/bash new-root/bin
# chroot를 실행해 보세요
root@ubuntu1804:/tmp# chroot new-root /bin/bash
chroot: failed to run command '/bin/bash': No such file or directory
4. 이번에도 에러가 발생한 이유는 커맨드(/bin/bash)에서 사용하는 의존성 라이브러리들이 없기 때문입니다. ldd 명령을 이용하여 커맨드(/bin/bash)에서 사용하는 라이브러리를 확인한 다음, new-root 경로에 해당 라이브러리들을 복사해 주세요. 그리고 다시 chroot를 실행해 봅니다. 에러 메시지 출력 없이 프롬프트 모양이 바뀌었다면 성공한 것입니다.
# /bin/bash 의존성 라이브러리를 확인합니다.
root@ubuntu1804:/tmp# ldd /bin/bash
linux-vdso.so.1 (0x00007ffcef1f9000)
libtinfo.so.5 => /lib/x86_64-linux-gnu/libtinfo.so.5 (0x00007f811d3d5000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f811d1d1000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f811cde0000)
/lib64/ld-linux-x86-64.so.2 (0x00007f811d919000)
# 의존성 라이브러리들을 복사할 디렉터리를 만듭니다
root@ubuntu1804:/tmp# mkdir -p new-root/{lib/x86_64-linux-gnu,lib64}
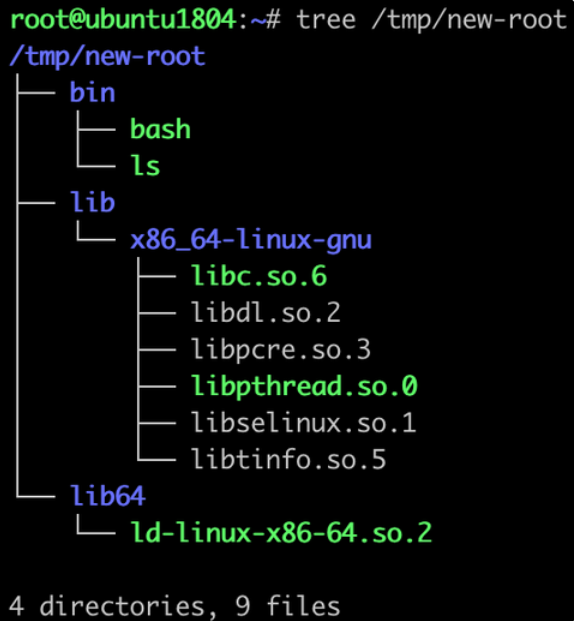
root@ubuntu1804:/tmp# tree new-root
new-root
├── bin
│ └── bash
├── lib
│ └── x86_64-linux-gnu
└── lib64
# 의존성 라이브러리들을 new-root 디렉터리로 복사합니다. (vdso 파일은 제외)
root@ubuntu1804:/tmp# cp /lib/x86_64-linux-gnu/{libtinfo.so.5,libdl.so.2,libc.so.6} new-root/lib/x86_64-linux-gnu
root@ubuntu1804:/tmp# cp /lib64/ld-linux-x86-64.so.2 new-root/lib64
# 의존성 라이브러리들이 잘 복사됐는지 확인해보세요
root@ubuntu1804:/tmp# tree new-root
new-root
├── bin
│ └── bash
├── lib
│ └── x86_64-linux-gnu
│ ├── libc.so.6
│ ├── libdl.so.2
│ └── libtinfo.so.5
└── lib64
└── ld-linux-x86-64.so.2
# chroot를 실행합니다.
root@ubuntu1804:/tmp# chroot new-root /bin/bash
bash-4.4#
지금까지 과정을 요약하면 경로 ⇒ 복사 ⇒ 실행 순서가 됩니다.
- 새로운 루트 경로(new-root)를 만들고
- 실행할 커맨드(/bin/bash)와 의존성 라이브러리들(ldd 조회)을 new-root에 복사
- chroot로 new-root를 지정하여 커맨드(/bin/bash)를 실행하였습니다.
그럼 chroot로 실행한 환경을 한 번 탐색해 볼까요?
ls 명령어가 없다고 나옵니다. 세상일이란 게 호락호락하지 않네요. 이제 어떡해야 할까요? 이미 다들 마음 속에 답이 있으신 것 같습니다. 앞서 bash 프로그램을 new-root에 복사한 것처럼 ls 프로그램을 new-root 복사해주면 됩니다.
# chroot로 실행한 환경 탐색 결과
bash-4.4# ls
bash: ls: command not found
chroot한 Bash 셸에서 ls 해보기
그렇다면 ls 프로그램을 new-root 복사하는 것은 어떻게 할 수 있을까요?
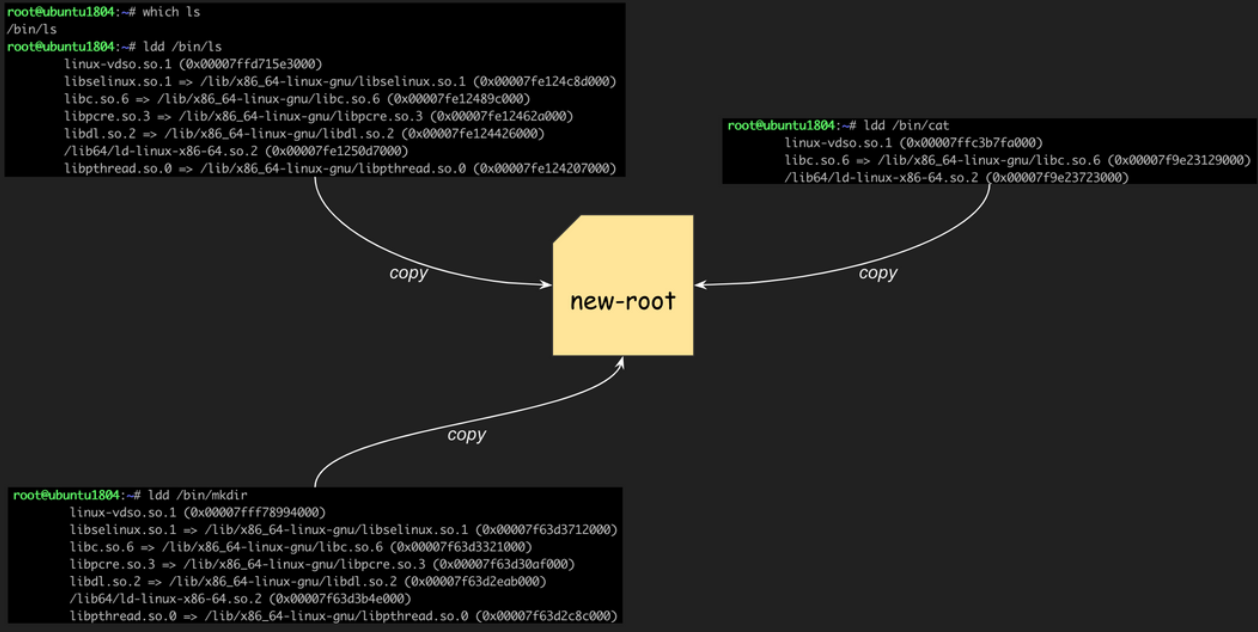
1. 자, 이번에는 ls의 의존성 라이브러리를 확인해 보겠습니다. 복잡해 보이지만 별거 없습니다. /bin/ls 실행 파일과 ldd로 조회한 라이브러리 파일이 /lib/x86_64-linux-gnu 경로에 5개, /lib64 밑에 1개 있습니다.
root@ubuntu1804:/tmp# which ls
/bin/ls
root@ubuntu1804:/tmp# ldd /bin/ls
linux-vdso.so.1 (0x00007ffd9df7c000)
libselinux.so.1 => /lib/x86_64-linux-gnu/libselinux.so.1 (0x00007fd0cd180000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fd0ccd8f000)
libpcre.so.3 => /lib/x86_64-linux-gnu/libpcre.so.3 (0x00007fd0ccb1e000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fd0cc91a000)
/lib64/ld-linux-x86-64.so.2 (0x00007fd0cd5ca000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007fd0cc6fb000)
2. 한 번 해보았으니 ls 복사는 좀 더 능숙하게 진행할 수 있을 것 같습니다. 복사 후 chroot 를 실행해 주세요.
# /bin/ls를 복사합니다.
root@ubuntu1804:/tmp# cp /bin/ls new-root/bin
# ls 의존성 라이브러리를 복사합니다.
root@ubuntu1804:/tmp# cp /lib/x86_64-linux-gnu/{libselinux.so.1,libc.so.6,libpcre.so.3,libdl.so.2,libpthread.so.0} new-root/lib/x86_64-linux-gnu
root@ubuntu1804:/tmp# cp /lib64/ld-linux-x86-64.so.2 new-root/lib64
# chroot를 실행합니다.
root@ubuntu1804:/tmp# chroot new-root /bin/bash
bash-4.4#
3. chroot한 컨테이너 환경에서 ls로 호스트와 루트 디렉터리를 비교해 보세요. 아래 그림에서 왼쪽이 컨테이너, 오른쪽이 호스트인데요. 루트 디렉터리( / )가 서로 다른 것을 확인할 수 있습니다.

4. 이번에는 chroot한 컨테이너에서 루트 디렉터리 밖으로 벗어날 수 있는지 확인해 보겠습니다.
# 루트 조회
bash-4.4# cd /
bash-4.4# ls
bin lib lib64
# 루트 탈출 시도 및 확인
bash-4.4# cd ../../../../
bash-4.4# ls
bin lib lib64도망 못 가게 잘 가두고 있는 것 같습니다.
이처럼 사용자에게 제공하고 싶은 프로그램을 한 곳에 모으고, 사용자 프로세스가 활동할 수 있는 경로를 제한해서 실행한 것이 컨테이너의 초창기 모습입니다.
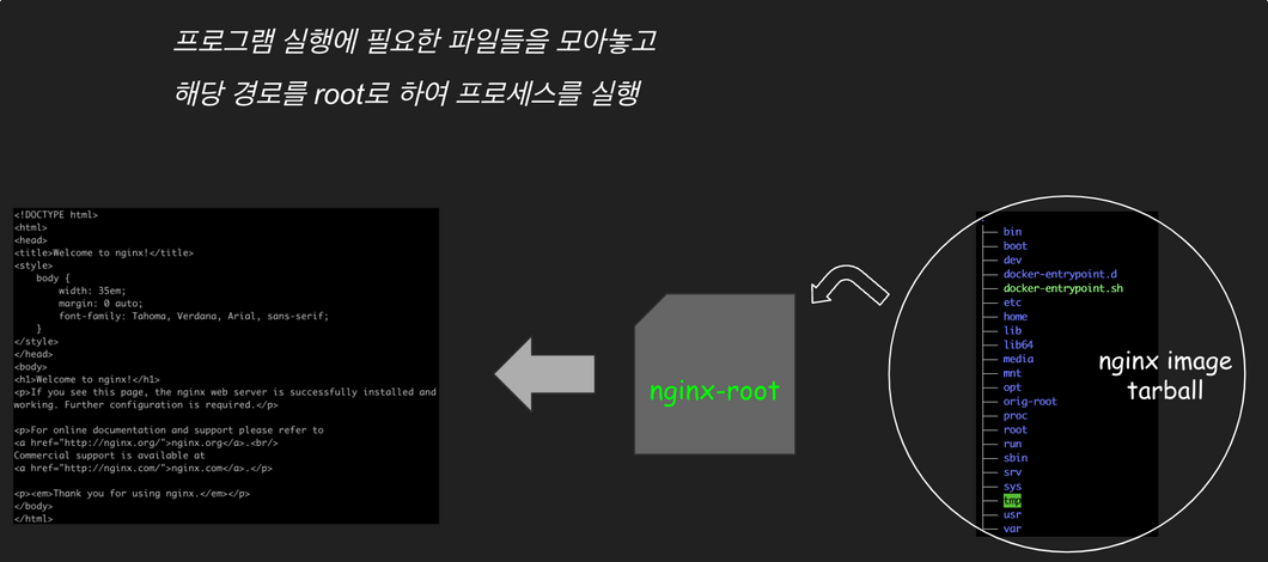
그런데, 이렇게 필요한 프로그램들을 일일이 라이브러리까지 복사해 넣는 것은 너무나도 손이 많이 갑니다. 누군가가 미리 필요한 모든 것을 모아둔 "그것"을 가져다 쓰면 정말 편하겠죠? 미리 모아둔 "그것"이 바로 "이미지(image)"입니다. 이미지는 프로그램 실행에 필요한 것들을 모아둔 패키지로, 마치 필요한 살림살이를 담아둔 이삿짐이라고 할 수 있습니다.
이미지로 chroot 해보기
Bash, Is로 chroot 사용하기에서는 사용할 프로그램들(bash, ls)을 복사하여 chroot로 실행해 보았다면, 이미지로 chroot 사용하기에서는 누군가 만들어 놓은 이미지(nginx)를 가져다가 실행해 보도록 하겠습니다.
# nginx-root 디렉터리를 만듭니다.
root@ubuntu1804:/tmp# mkdir nginx-root
# 도커를 이용하여 nginx 이미지를 nginx-root에 압축을 풀어줍니다.
root@ubuntu1804:/tmp# docker export $(docker create nginx:latest) | tar -C nginx-root -xvf -
## (출력 생략)
# nginx-root 경로를 한번 살펴보세요
root@ubuntu1804:/tmp# tree -L 1 nginx-root
nginx-root
├── bin
├── boot
├── dev
├── docker-entrypoint.d
├── docker-entrypoint.sh
├── etc
├── home
├── lib
├── lib64
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin
├── srv
├── sys
├── tmp
├── usr
└── var
# chroot로 셸을 실행해 보세요
root@ubuntu1804:/tmp# chroot nginx-root /bin/sh
# 루트를 확인해 보세요
# ls /
bin boot dev docker-entrypoint.d docker-entrypoint.sh etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
ls로 chroot한 컨테이너의 루트 디렉터리를 살펴보면 nginx 이미지로부터 가져온 nginx 실행에 필요한 각종 파일과 디렉터리들이 준비되어 있습니다. 가져다 쓰니 정말 편하네요!

이번에는 컨테이너 안에서 nginx를 실행해 보고 잘 떴는지 확인해 봅시다. (nginx 기동 시 "daemon off" 옵션을 주어 foreground로 실행합니다)
# nginx를 실행합니다.
# nginx -g "daemon off;"터미널 창을 새로 띄워서 기동 여부를 확인해 보겠습니다.
# 맥에서 vagrant 셸에 접속합니다 (Vagrantfile 경로기준)
sam@kakaoenterprise % vagrant ssh ubuntu1804
Last login: Sat Jun 25 06:16:23 2022 from 10.0.2.2
# curl을 이용하여 nginx에 요청을 보내보세요
vagrant@ubuntu1804:~$ curl http://localhost:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
## (이하 생략)지금까지 nginx 이미지와 chroot를 사용해서 루트 디렉터리를 격리하고 nginx를 실행해 보았습니다.
컨테이너 구현 시 chroot의 한계
chroot를 통해 본 컨테이너는 프로그램을 모아놓고 격리된 디렉터리에서 실행한 프로세스입니다. VMware처럼 별도의 OS를 설치하고 그 위에 nginx를 실행하는 VM과는 방식이 다르지요. 그렇다면 chroot만 있어도 컨테이너 구현은 충분할 것 같지 않나요? 하지만 컨테이너로 쓰기에 chroot만으로는 부족한 부분이 많습니다. 왜 그럴까요?
- 첫째, 탈옥이 가능하다. chroot의 목적은 프로세스를 특정 디렉터리에 가두기 위한 것인데, 탈옥이 가능하다는 한계가 있어 실제 컨테이너에서는 쓰이지 않습니다.
- 둘째, 격리되지 않는다. 호스트 상의 다른 프로세스들이 루트 권한만 있으면 chroot 경로에 접근할 수 있고, chroot한 프로세스도 “ps”, “mount” 등 시스템 바이너리만 복사하면 다른 프로세스 및 시스템 정보들을 볼 수 있습니다. “보인다"는 것은 곧 격리되지 않음을 의미하고 프로세스 간에 서로 영향을 주고받을 수 있음을 의미합니다. (앞의 nginx 이미지를 이용한 chroot 실습에서도 호스트의 네트워크를 사용하여 웹서버를 띄우는 것을 보셨죠)
- 셋째, 루트 권한 제어가 필요하다. chroot 명령을 쓰려면 루트 권한이 필요하고 , chroot로 실행하는 프로세스도 루트 권한을 가지게 됩니다. 보안 측면에서 컨테이너를 비롯한 어떤 프로세스든 루트 권한을 가지게 하는 것은 매우 위험합니다. 따라서 루트 권한 없이도 컨테이너를 기동하고, 컨테이너 프로세스가 필요한 작업을 수행할 수 있도록 적절한 권한을 부여하는 방법이 필요합니다.
- 넷째, 리소스 제한이 되지 않는다. chroot로 실행하더라도 호스트의 리소스를 제한 없이 사용할 수 있어 CPU나 Memory, IO, 네트워크 등의 사용량을 제한하지 못합니다. 이는 특정 컨테이너에서의 과도한 리소스 사용으로 다른 프로세스에 영향을 줄 수 있습니다. (nginx 이미지 실습에서 컨테이너 nginx로 엄청난 요청 트래픽을 받는다고 상상해 보세요. 직접 부하를 줘보셔도 됩니다)
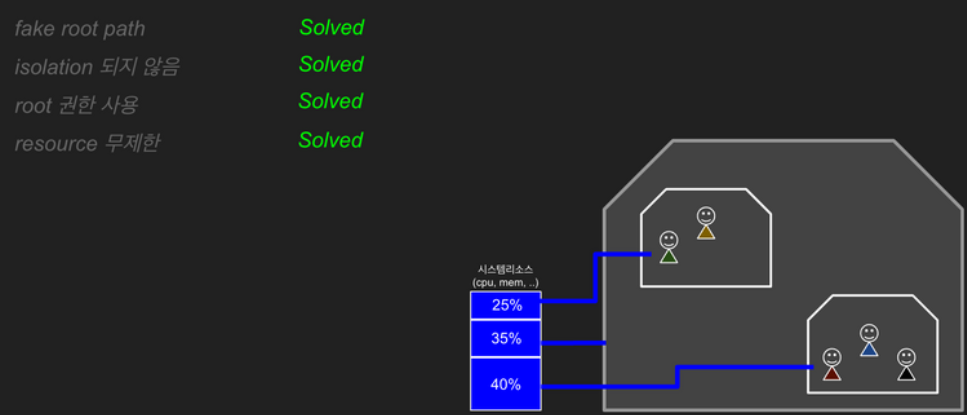
이런 이유로 실제 컨테이너에서는 chroot를 사용하지 않게 되는 거죠. 하지만 사용 방법이 간단한 보안상 위험하지 않은 작업(패키징, 배포 환경 격리)이나 학습 및 테스트 용도 등으로 활용할 수 있습니다. 그럼 지금부터는 탈옥 가능, 격리 안 됨, 루트 권한, 리소스 무제한 문제를 하나씩 해결해보겠습니다.
탈옥 가능 문제
chroot에는 치명적인 문제가 있습니다. chroot가 지정한 “루트” 디렉터리에서 탈출이 가능하다는 건데요. 이는 사용자(FTP 등)가 허용된 경로를 벗어나 호스트 루트를 탈취할 수 있어 보안에 심각한 위협이 됩니다.
pivot_root를 통해 컨테이너가 호스트와 격리된 별도의 루트 파일시스템 위에서 동작할 수 있게 함으로써 무너지지 않는 확실한 집터를 준비합니다.
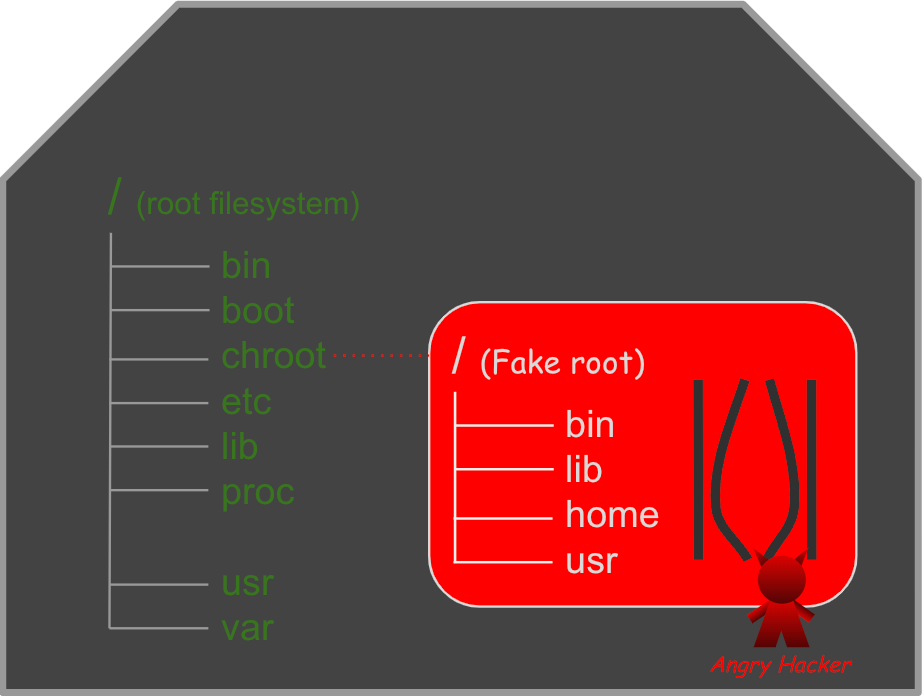
먼저 탈옥 가능이 어떤 문제인지 알아보겠습니다.
1. /tmp 경로에서 코드를 작성합니다.
root@ubuntu1804:/tmp# vi escape_chroot.c
2. 탈옥 코드를 앞의 (실습) 경로인 new-root에 컴파일하고, chroot 환경에서 실행해 보겠습니다.
/* 탈옥 소스코드 */
#include <sys/stat.h>
#include <unistd.h>
int main(void)
{
mkdir(".out", 0755);
chroot(".out");
chdir("../../../../../");
chroot(".");
return execl("/bin/sh", "-i", NULL);
}# 탈옥 코드를 new-root에 컴파일합니다.
root@ubuntu1804:/tmp# gcc -o new-root/escape_chroot escape_chroot.c
# chroot로 셸을 실행합니다.
root@ubuntu1804:/tmp# chroot new-root /bin/bash
# 루트 디렉터리 조회합니다.
bash-4.4# ls /
bin escape_chroot lib lib64
# 탈옥 코드를 실행합니다
bash-4.4# ./escape_chroot
3. 탈옥 코드 실행 후에 루트 디렉터리가 컨테이너가 아닌 호스트 루트가 출력되는 것을 확인할 수 있습니다.
# 루트 확인
# ls /
bin dev home initrd.img.old lib64 media opt root sbin srv tmp var vmlinuz.old boot etc initrd.img lib lost+found mnt proc run snap sys usr vmlinuz
그럼 이제부터 pivot_root로 chroot의 탈옥 문제를 해결해 보겠습니다. chroot가 현재 경로를 루트 디렉터리인 것처럼 속인다면, pivot_root는 실제로 루트 파일시스템 자체를 바꿉니다. 루트 파일시스템을 바꾼다는게 잘 상상이 안 가시죠? 뭔가 어마어마해 보입니다.
pivot_root
무너지지 않는 확실한 집터 준비하기
pivot_root는 실제로 루트 파일시스템 자체를 바꿔, 컨테이너가 전용 루트 파일시스템을 가지도록 합니다. 컨테이너가 안전하게 호스트와 다른 별도의 루트 파일시스템을 가지게 하려면 "마운트 네임스페이스"가 필요합니다.
"마운트 네임스페이스"는 특정 프로세스에 대해 마운트를 호스트와 격리하는 것으로, 컨테이너 내부의 마운트 변경 사항이나 마운트된 파일시스템 및 파일시스템 내부의 파일 변경 사항들이 호스트에서는 보이지 않습니다. 따라서 루트 파일시스템을 pivot_root로 바꾸더라도(즉, 마운트 포인트가 바뀌더라도) 마운트를 호스트와 격리했기 때문에 호스트에는 전혀 영향을 미치지 않고, 컨테이너 안에서만 새로운 루트 파일시스템으로 바뀌게 됩니다.
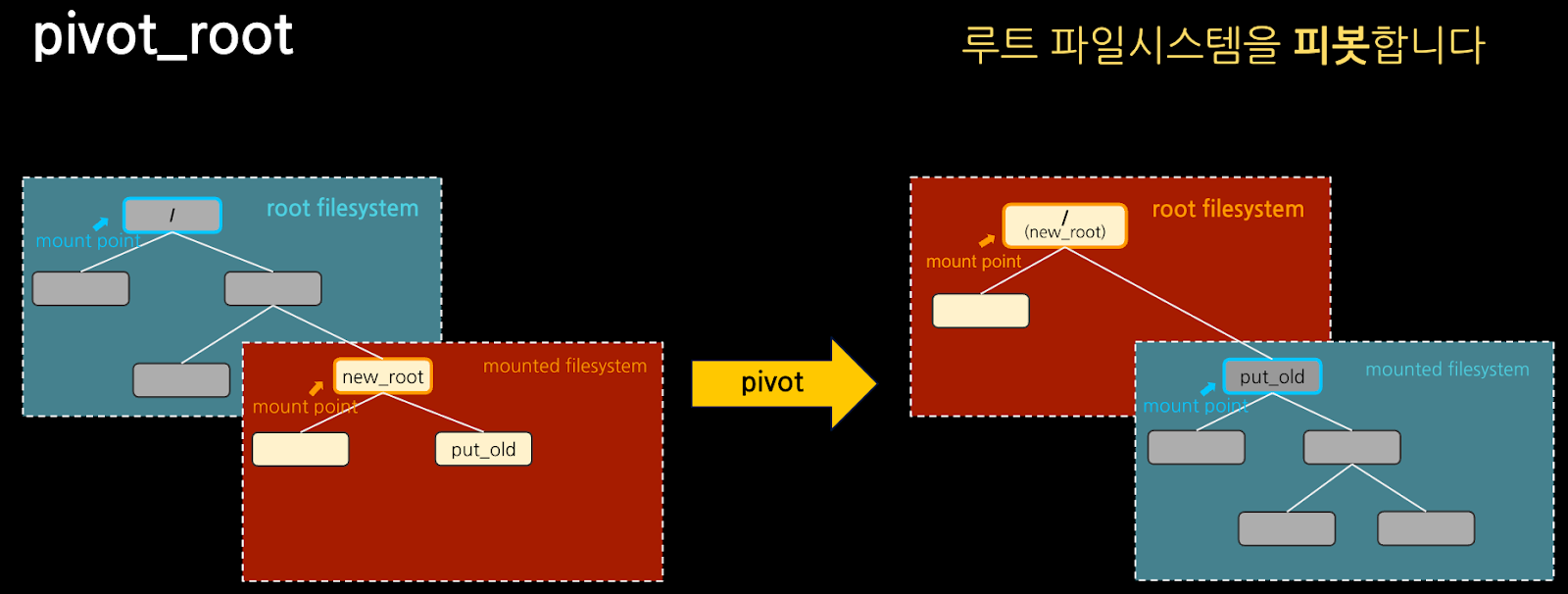
바로 이전의 chroot 탈옥 실습에서 사용한 탈옥 프로그램(escape_chroot)을 이용해서 pivot_root 로 만든 컨테이너도 탈옥이 가능한지 확인해 보겠습니다.
1. 먼저 pivot_root 를 하기 위한 준비가 필요합니다. 루트파일시스템의 마운트 포인트를 pivot 해야 하므로 현재 시스템의 마운트에 영향을 주지 않기 위해서 마운트 네임스페이스를 격리합니다.
# 마운트 네임스페이스를 격리하여 셸을 실행합니다.
root@ubuntu1804:/tmp# unshare --mount /bin/bash
# new_root 디렉터리를 생성합니다. (이전 실습과 다르게 '_' underbar 입니다)
root@ubuntu1804:/tmp# mkdir new_root
# 루트 파일시스템으로 사용할 new_root를 마운트합니다. * tmpfs 타입(temporary filesystem)
root@ubuntu1804:/tmp# mount -t tmpfs -o size=10M none new_root
# chroot 실습1(new-root) 파일들을 new_root로 복사합니다.
root@ubuntu1804:/tmp# cp -r new-root/* new_root/
# 기존 루트 파일시스템을 마운트할 디렉터리를 생성합니다.
root@ubuntu1804:/tmp# mkdir new_root/put_old
# new_root로 이동
root@ubuntu1804:/tmp# cd new_root
2. pivot_root를 사용하여 기존 루트 파일시스템 대신 new_root를 루트 파일시스템으로 바꿔 보겠습니다. pivot_root는 인자(args)로 "마운트 포인트(new_root)"와 현재 루트 파일시스템을 옮겨 놓을 "디렉터리 경로(put_old)"를 받습니다.
# pivot_root를 실행합니다.
root@ubuntu1804:/tmp/new_root# pivot_root . put_old
3. pivot_root를 이용하여 루트 파일시스템을 호스트와 피봇(pivot) 하였습니다. 설명대로 루트( / ) 경로에는 new_root에 있던 파일들이 보이고, put_old에는 호스트 루트 경로의 파일들이 있음을 확인할 수 있습니다.
# 현재 경로와 루트 경로를 비교해 보세요
root@ubuntu1804:/tmp/new_root# ls .
bin escape_chroot lib lib64 put_old
root@ubuntu1804:/tmp/new_root# ls /
bin escape_chroot lib lib64 put_old
# 루트 경로로 이동해 보세요
root@ubuntu1804:/tmp/new_root# cd /
# 루트 경로와 put_old를 비교해 보세요
root@ubuntu1804:/# ls
bin escape_chroot lib lib64 put_old
root@ubuntu1804:/# ls put_old
bin dev home initrd.img.old lib64 media opt root sbin srv tmp var vmlinuz.old boot etc initrd.img lib lost+found mnt proc run snap sys usr vmlinuz
4. pivot_root를 이용해서 chroot처럼 루트 디렉터리를 바꿀 수 있었는데요. 이제 탈옥이 가능한지 확인해 봐야겠죠.
# 탈옥 프로그램을 실행합니다
root@ubuntu1804:/# ./escape_chroot
# 루트를 확인합니다
root@ubuntu1804:/# ls /다들 탈옥에 실패하셨을까요?
pivot_root가 프로세스의 루트 파일시스템 자체를 new_root로 바꿔 버리기 때문에 탈옥이 되지 않습니다.
마운트 네임스페이스를 격리한 상태에서 pivot_root하기 때문에 호스트에는 영향을 주지 않으면서 컨테이너는 호스트와 격리된 루트파일시스템에서 동작할 수 있게 되었습니다.
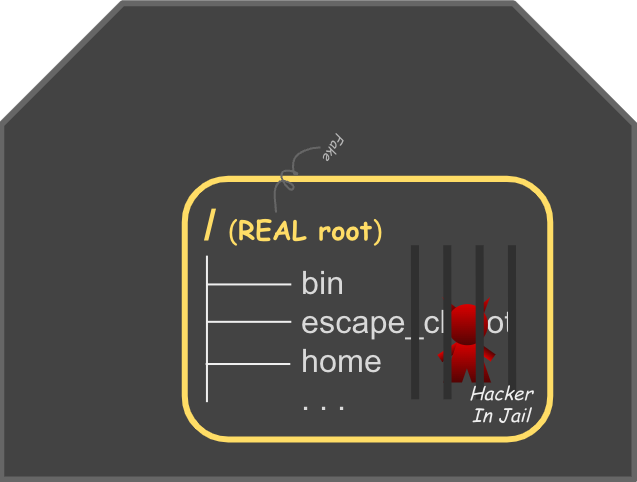
지금까지 pivot_root 를 사용해서 chroot의 탈옥 문제를 해결해 보았습니다. 그리고 앞부분에서 실습한 것과 같이 컨테이너는 전용 루트파일시스템을 가지게 되었습니다. 컨테이너가 전용 루트 파일시스템을 가짐으로써 “이미지"에 꾸려진 파일, 설정 등 살림살이도 풀어놓고 자유롭게 파일시스템도 마운트할 수 있게 되었습니다.
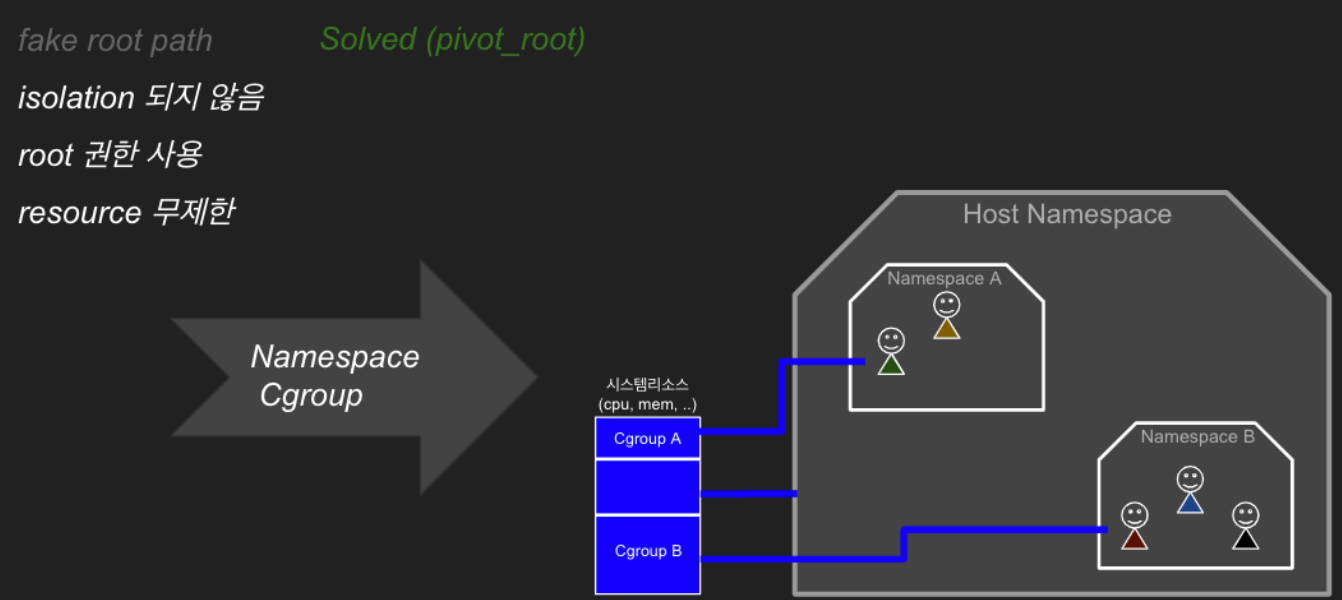
격리 안 됨과 루트 권한 문제
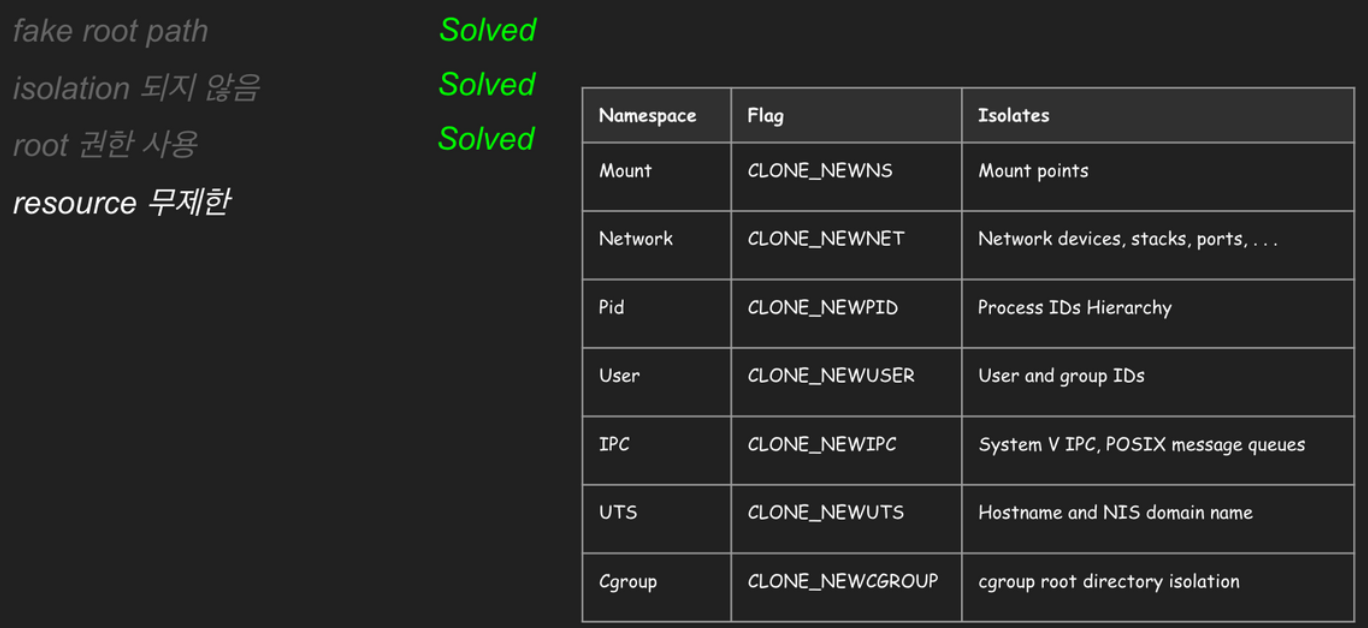
chroot는 프로세스의 격리가 전혀 되지 않아, 프로세스 간에 서로 영향을 주고받을 수 있다는 문제가 있습니다. 2002년 리눅스 2.4.19 버전에 kernel feature로 처음 포함된 네임스페이스(위키)는 프로세스에 격리된 환경과 리소스를 제공해 이러한 문제를 해결할 수 있게 되었습니다. 전용 파일시스템 마운트, uts(명패), ipc(직통전화), pid(족보), 전용 네트워크 구성, cgroups(계량기), user(루트 권한) 등 다양한 네임스페이스로 문제를 해결하죠.
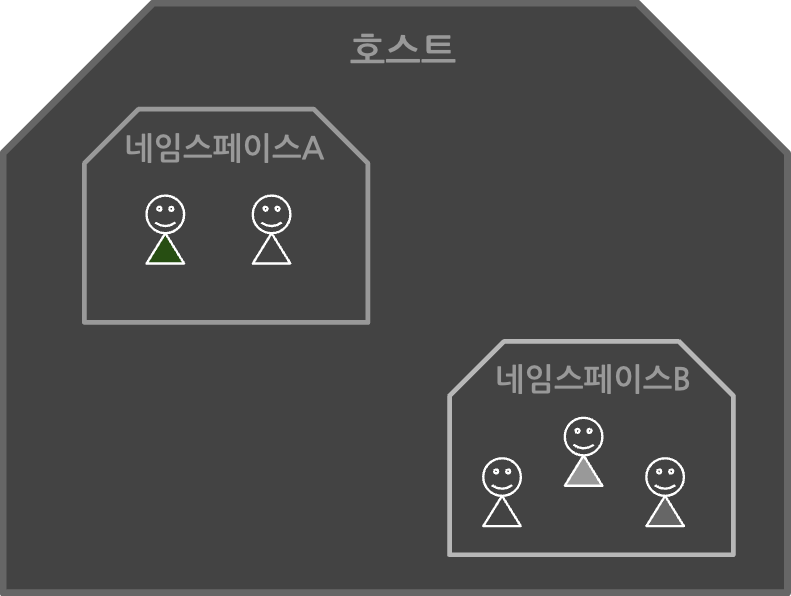
네임스페이스 안에서의 변경은 내부의 프로세스에만 보이고 다른 프로세스에게는 보이지 않습니다. 네임스페이스와 관련된 프로세스는 부모와 자식의 특징을 갖는데요. 다음과 같은 규칙이 있습니다.
- 첫째, 모든 프로세스들은 네임스페이스 타입별로 특정 네임스페이스에 속합니다.
- 둘째, 자식 프로세스는 부모 프로세스의 네임스페이스를 상속받습니다.
네임스페이스는 격리하는 자원에 따라 다음과 같이 다양하게 구분되어 있습니다.
- 마운트 네임스페이스 (CLONE_NEWNS)
- UTS 네임스페이스 (CLONE_NEWUTS)
- IPC 네임스페이스 (CLONE_NEWIPC)
- PID 네임스페이스 (CLONE_NEWPID)
- cgroup 네임스페이스 (CLONE_NEWCGROUP)
- 네트워크 네임스페이스 (CLONE_NEWNET)
- USER 네임스페이스 (CLONE_NEWUSER)
앞서 살펴본 컨테이너의 기원, chroot에서 소개한 연표를 따라 각 네임스페이스를 살펴보며 어떤 문제를 해결하는지 알아봅시다.
마운트 네임스페이스

마운트 네임스페이스(Mount Namespace)는 2002년(Linux 2.4.19)에 발표된 "최초의 네임스페이스"입니다. pivot_root를 사용하기 위해서는 호스트의 파일시스템에 영향을 주지 않는 방법이 필요한데요. 마운트 네임스페이스가 그 방법을 제공합니다.
마운트 네임스페이스는 "마운트 포인트"를 격리(isolation)합니다. 앞서 pivot_root 실습에서 unshare --mount를 기억하시나요? 마운트 네임스페이스를 만들고 지정한 커맨드(기본값: $SHELL)를 실행해 주는 명령입니다. pivot_root는 프로세스의 "루트 파일시스템을 피봇"하는 명령이기 때문에, 호스트에게 영향을 주지 않고 컨테이너 전용 루트 파일시스템을 구성하기 위한 마운트 격리가 필요합니다.
마운트 네임스페이스는 “마운트 포인트”를 격리(isolation) 합니다.
1. 마운트 네임스페이스를 격리하여 bash를 실행해보겠습니다.
# 마운트 네임스페이스를 격리한 상태로 셸을 실행
root@ubuntu1804:/tmp# unshare --mount /bin/bash
2. mount_ns 디렉터리를 생성하고, tmpfs 타입으로 마운트합니다.
# mount_ns 디렉터리를 생성하고 tmpfs 타입으로 마운트
root@ubuntu1804:/tmp# mkdir /tmp/mount_ns
root@ubuntu1804:/tmp# mount -t tmpfs tmpfs /tmp/mount_ns
3. mount_ns에 a라는 파일을 생성합니다.
# mount_ns에 a파일을 생성
root@ubuntu1804:/tmp# touch /tmp/mount_ns/a
터미널 창(터미널 #2)을 하나 더 띄워서 현재 터미널(컨테이너)과 비교해 보겠습니다. 터미널#2 (호스트)에서는 df -h와 mount 명령으로 mount_ns가 보이지 않습니다. 컨테이너가 마운트 네임스페이스로 격리되었기 때문에 컨테이너 안에서 마운트한 것은 호스트에서는 보이지 않습니다. 호스트에서 ls /tmp/mount_ns 했을 때도 디렉터리는 보이지만 ‘a’라는 파일은 보이지 않습니다. 왜 그럴까요? 마운트 네임스페이스로 격리되었기 때문입니다. 디렉터리(/tmp/mount_ns)는 볼 수 있지만, 디렉터리(/tmp/mount_ns)를 마운트 포인트로 하여 부착된 파일시스템(tmpfs)은 호스트에서는 볼 수 없습니다. 따라서 해당 파일시스템(tmpfs)에 write 한 파일 ‘a’ 역시 호스트에서는 볼 수 없습니다.

터미널 #1이 마운트 네임스페이스로 격리돼 있는지 어떻게 알 수 있을까요? /proc 파일시스템으로부터 특정 프로세스의 네임스페이스 정보를 알 수 있습니다. 아래와 같이 컨테이너와 호스트의 마운트 네임스페이스 inode 값을 비교해 보세요.

프로세스의 mnt: [inode] 값을 비교하여 같으면 동일한 네임스페이스입니다. 프로세스별(pid) 네임스페이스 정보는 /proc/{pid}/ns에서 확인할 수 있습니다. $$로 현재 프로세스의 pid 값을 알 수 있고, readlink /proc/$$/ns/mnt 명령을 실행하면 현재 프로세스의 mount namespace inode 값을 확인합니다.
UTS 네임스페이스
컨테이너에 문패를 달아줍니다.
여러 세대 중에 어떤 게 우리 집(컨테이너)인지 표시해 주세요.
UTS 네임스페이스는 IPC 네임스페이스와 함께 2006년 Linux 2.6.19 버전에 포함되었습니다. UTS 네임스페이스는 호스트명을 서버와 다르게 설정하여 사용할 수 있도록 합니다.

저는 UTS 네임스페이스의 이름 때문에 자주 헷갈리는데요. UTS는 "Unix Time-Sharing(시분할)"의 약자입니다. "시분할"과 호스트명이 무슨 상관인데 생각할 분도 계실 텐데요. "시분할" 기법은 컴퓨팅 리소스를 공유하기 위한 방법으로 여러 사용자가 interactive하게 대화식으로 컴퓨터를 이용할 수 있게 하는 시도에서 출발하였습니다. single (core) CPU였던 당시(1970년대) 여러 사용자 요청을 처리하는 방법은 "cpu 시간을 쪼개서" 돌아가며 처리하는 방식인 Time-Sharing 기법을 사용하였는데요. 여러 사람이 한 대의 서버를 나누어 쓰다 보니 사용자(프로세스) 환경별로 호스트명이나 도메인명을 구분할 수 있도록 격리를 제공합니다.
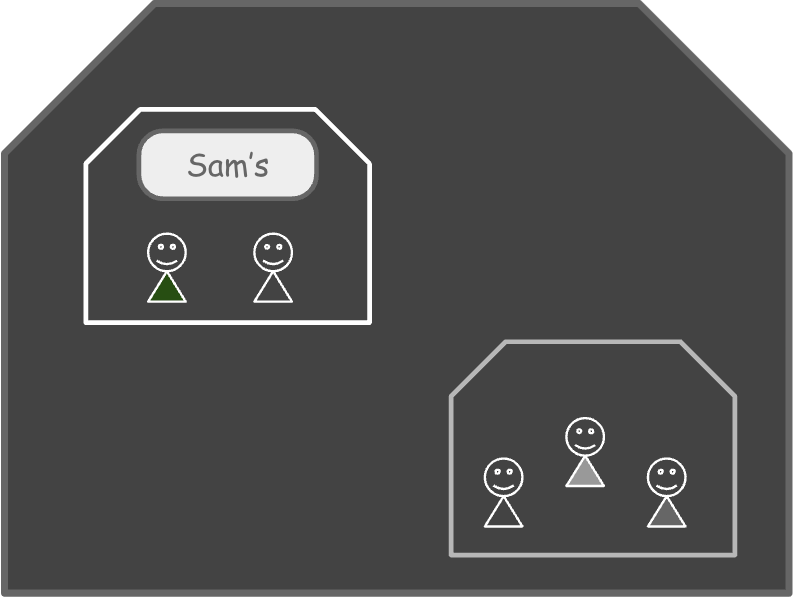
1. unshare 명령어에서 --uts 옵션을 주면 UTS 네임스페이스를 사용할 수 있습니다.
# uts 네임스페이스를 격리하여 셸 실행
root@ubuntu1804:/tmp# unshare --uts /bin/bash
2. hostname 명령을 실행하여 호스트명을 확인해 보세요.(호스트와 동일하게 출력됩니다) 부모 네임스페이스 (호스트)의 값을 상속받았음을 알 수 있습니다.
# 호스트명 확인
root@ubuntu1804:/tmp# hostname
ubuntu1804
# 호스트명 변경
root@ubuntu1804:/tmp# hostname HelloSam
컨테이너와 호스트의 hostname을 비교해 보세요.

IPC 네임스페이스
직통 전화를 한 대 설치합니다.
IPC 네임스페이스는 UTS 네임스페이스와 함께 2006년 Linux 2.6.19 버전에 포함되었습니다.
리눅스에는 “프로세스 간 통신”(Inter-Process Communication)을 지원하는 pipe, named pipe, message queue, shared memory, memory map, socket 등 다양한 리소스들이 존재합니다. IPC 네임스페이스는 UNIX System V (five, 1983) 기반의 IPC 리소스에 대한 격리를 제공합니다.
1. unshare 명령어로 IPC 네임스페이스로 격리한 컨테이너 안에서 Shared Memory를 생성하고 호스트와 비교해 보겠습니다.
# 터미널 1 (컨테이너)
# ipc 네임스페이스를 격리하여 셸을 실행합니다.
root@ubuntu1804:/tmp# unshare --ipc /bin/bash
# ipcmk 명령으로 Shared Memory 2000 bytes를 생성합니다.
root@ubuntu1804:/tmp# ipcmk -M 2000
Shared memory id: 0
# ipcs 명령으로 ipc 리소스를 확인해보세요
root@ubuntu1804:/tmp# ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00371704 0 root 644 2000 0
2. 비교를 위해 호스트에서도 Shared Memory를 생성합니다.
# 터미널2 (호스트)
# ipcmk 명령으로 Shared Memory 1000 bytes를 생성합니다.
vagrant@ubuntu1804:~$ sudo ipcmk -M 1000
Shared memory id: 0
# ipcs 명령으로 ipc 리소스를 확인해보세요
vagrant@ubuntu1804:~$ sudo ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x49818c67 0 root 644 1000 0
3. 컨테이너와 호스트는 서로 다른 IPC 네임스페이스로 격리되어 있으므로 서로의 IPC 리소스가 보이지 않습니다.
# 터미널2 (호스트)
# ipcs 명령으로 ipc 리소스를 확인해보세요
vagrant@ubuntu1804:~$ sudo ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x49818c67 0 root 644 1000 0
(참고) LXC
2008년 컨테이너 런타임, LXC(LinuX Containers)가 발표되었습니다. LXC는 리눅스 호스트 안에 격리된 OS 환경을 제공할 목적으로 만들었습니다. 앞서 소개해 드린 네임스페이스들과 함께 시스템 리소스(cpu, memory, network, devices …)를 제한할 수 있는 “Cgroups”가 LXC에 포함되었는데요, Cgroups는 구글이 개발하여 리눅스에 컨트리뷰션 합니다. LXC는 도커(2013)보다 앞서 발표되었지만 사용하기 어렵고 복잡하여 당시에는 많은 호응을 얻지는 못하였습니다.
* LXC는 현재도 활동 중인 프로젝트로 공식 홈페이지에 따르면, 2023년 LXC 3.0, 2025년 4.0이 릴리즈 될 예정이라고 하네요.

PID 네임스페이스
가문의 족보와 같이 관계와 계통을 알아보자.
PID 네임스페이스는 pid 리소스를 격리하고, 이때 부여되는 pid는 PID 네임스페이스 안에서 unique 합니다.
그럼 pid란 무엇일까요? 트리구조인 리눅스 프로세스는 프로세스마다 pid(process id)라는 고유번호가 있고, 프로세스 트리의 가장 최상위에는 pid 1번인 “init 프로세스”라는 특별한 프로세스가 있습니다. 모든 프로세스는 init 프로세스(pid 1)를 루트(root)로 부모-자식 관계로 트리를 확장해 나갑니다. PID 네임스페이스를 격리하면 컨테이너 안에도 pid 1로 시작하는 자체적인 트리구조를 가지게 됩니다.

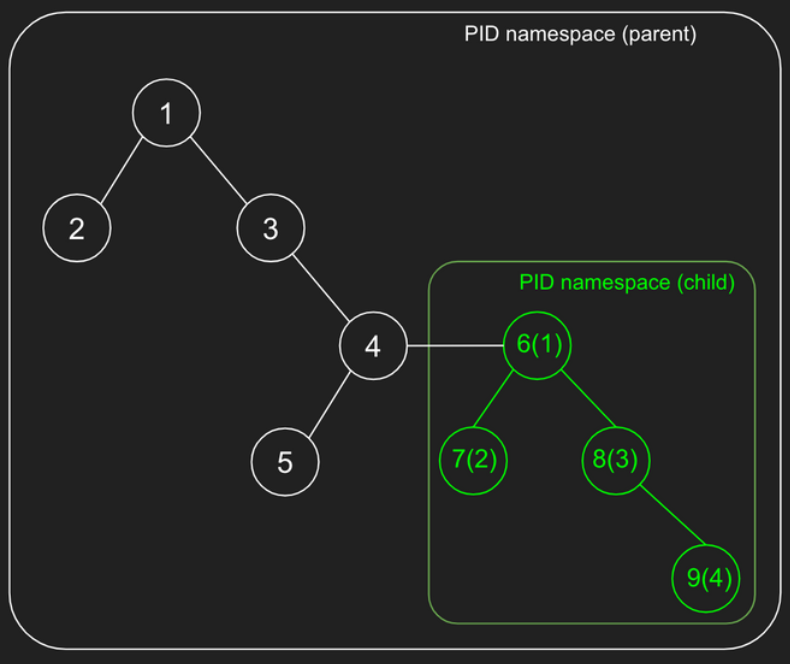
PID 네임스페이스는 앞에서 살펴본 다른 네임스페이스들과는 달리 부모 네임스페이스와 자식 네임스페이스가 중첩(nested)되는 구조로, 자식 네임스페이스의 프로세스들은 부모 네임스페이스의 pid와 해당 네임스페이스에서의 pid 모두 가지게 됩니다. (중첩된 PID 네임스페이스 각각 pid가 부여됩니다)
아래 그림의 pid 4에서 PID 네임스페이스를 생성하면, 커널은 child 프로세스 pid 6을 만들고 pid 6을 "init 프로세스"로 하여 PID 네임스페이스를 생성합니다. PID 네임스페이스 안에서 pid 1은 init 프로세스로, 해당 PID 네임스페이스의 라이프사이클과 관련된 특별한 프로세스입니다. 즉, pid 1이 죽으면 PID 네임스페이스도 사라집니다. PID 네임스페이스가 닫히면 네임스페이스 안에 포함된 모든 프로세스도 종료됩니다.
1. PID 네임스페이스를 생성해 볼까요.
# 터미널 1 (컨테이너)
# 현재 프로세스의 pid를 기억해주세요(각자 다름)
root@ubuntu1804:/tmp# echo $$
7062
## unshare 명령어로 PID 네임스페이스를 생성합니다.
root@ubuntu1804:/tmp# unshare --pid --fork --mount-proc /bin/bash
# 앞에서 출력한 pid 값과 비교해 보세요
root@ubuntu1804:/tmp# echo $$
1
2. 아래 (그림)처럼 컨테이너(터미널 1)와 호스트(터미널 2)에서 각각 ps aux 명령으로 프로세스를 조회해 보세요. ps 명령에 대한 자세한 내용은 man 페이지(man ps)를 참고해주세요. [그림 33]의 좌측 컨테이너에는 호스트 프로세스들은 보이지 않고, 오직 컨테이너의 프로세스들만 보입니다. 여기서 "-bash"의 pid 1(노란색 박스)을 주목해주세요. 우측의 호스트에서도 "-bash"(노란색 박스, pid = 7062)가 보입니다.
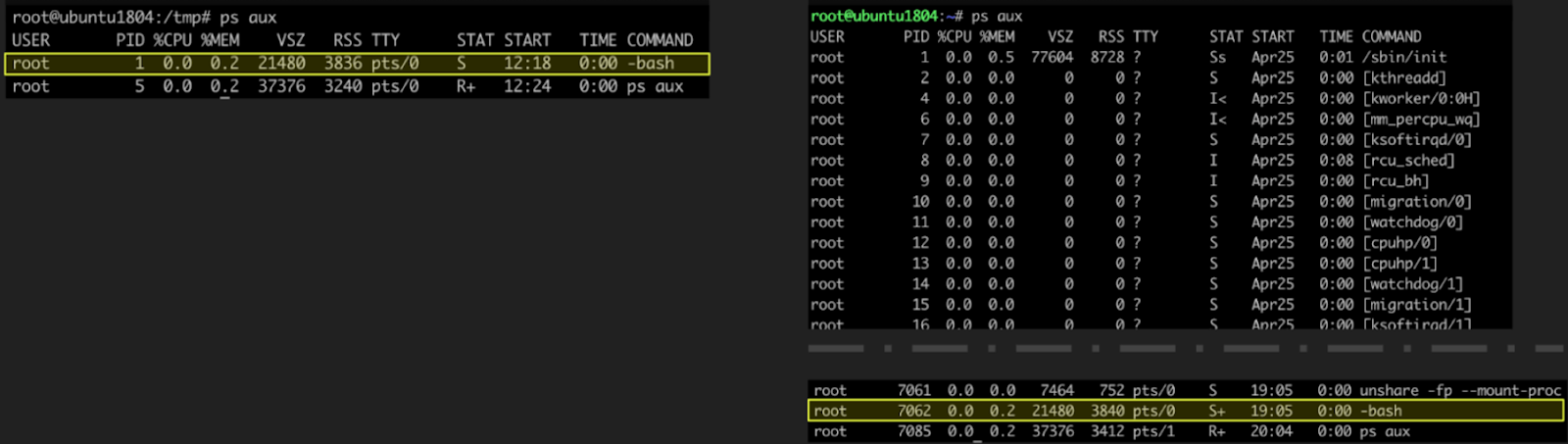

컨테이너와 호스트의 “-bash” 프로세스는 같은 프로세스일까요?
3. 컨테이너(터미널#1)와 호스트(터미널#2)의 “-bash” 가 동일 프로세스인지 확인해 보겠습니다. 동일 프로세스인지 확인하려면 해당 프로세스가 속한 PID 네임스페이스 정보를 확인하면 됩니다. 앞서 마운트 네임스페이스에서 해보셨듯이 /proc/{pid}/ns에서 PID 네임스페이스의 inode 값을 비교하여 확인할 수 있습니다. 예상한 대로 “-bash”는 PID 네임스페이스가 같은 동일한 프로세스입니다.
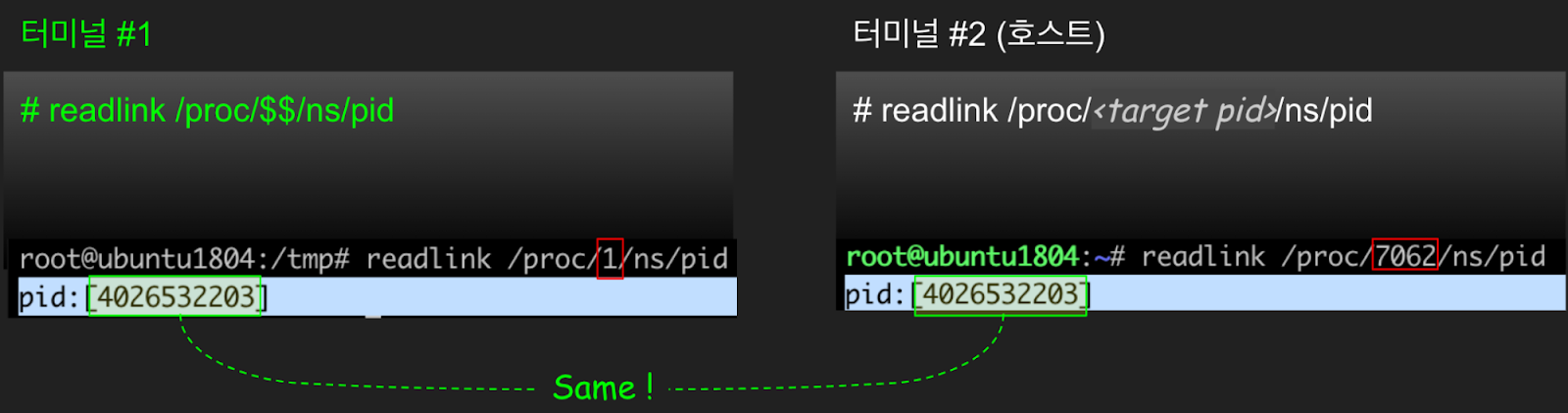
앞의 개념 설명에서 PID 네임스페이스는 다른 네임스페이스들과 달리 부모-자식의 중첩 구조를 가진다고 하였습니다. 호스트(터미널 #2)의 PID 네임스페이스가 부모 네임스페이스이고, 컨테이너가 자식 네임스페이스입니다. 방금 "-bash" 프로세스의 동일 여부에서 확인했듯이 부모 네임스페이스에서는 자식 네임스페이스의 프로세스들이 보입니다. 반면, 자식 네임스페이스에서는 부모 네임스페이스의 프로세스들이 보이지 않고, 오로지 자식 네임스페이스에 속한 프로세스들만 보이게 됩니다.
cgroup 네임스페이스
컨테이너 계량기
사이좋게 자원을 나눠 써요
서버 안에는 여러 프로세스가 함께 살고 있습니다. 그런데 CPU, Memory처럼 한정된 시스템 리소스를 누군가 독차지한다면 다른 프로세스들은 피해를 볼 수밖에 없으므로 리소스에 대한 보장도 필요합니다.
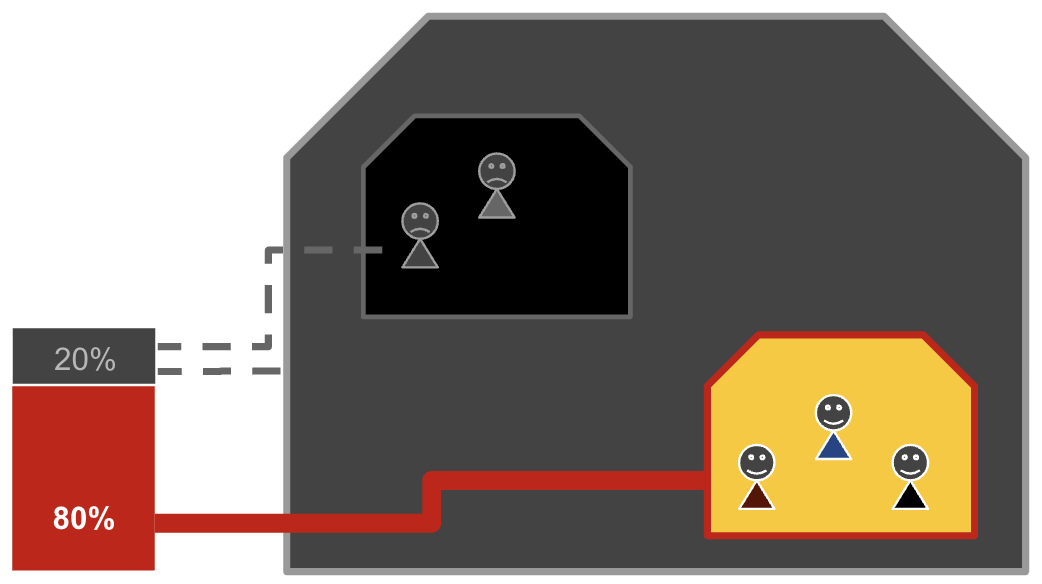
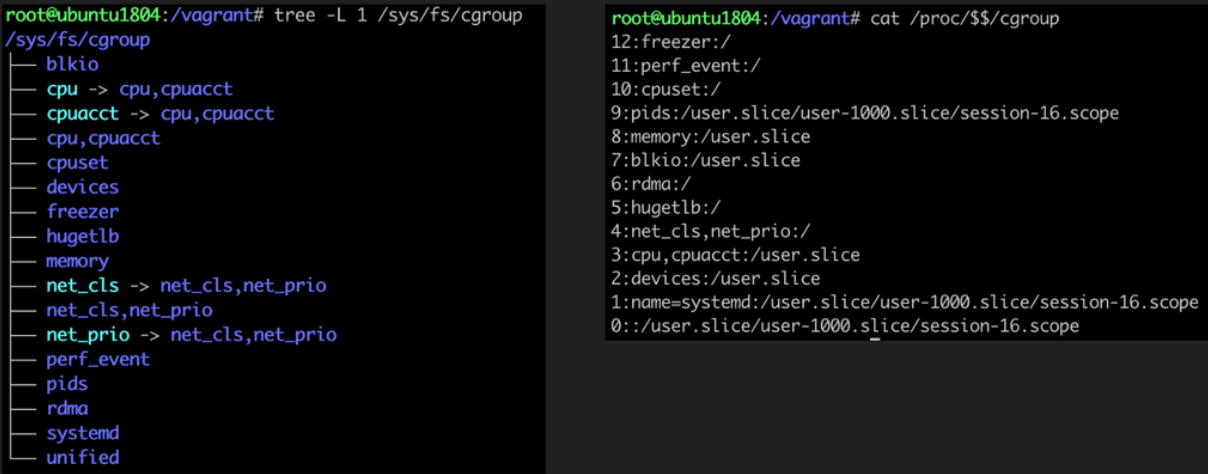
cgroup(Control Group)은 프로세스에 할당할 시스템 리소스(CPU, Memory, Network… )에 대한 제어를 제공합니다. cgroup이 시스템 리소스를 할당하고 제어하는 방식은 파일시스템을 기반으로 하고 있는데요. 이 특수한 파일시스템에서 디렉터리를 만들고 파일을 수정하는 방식으로 시스템 리소스들을 설정하고 관리하게 됩니다. 이렇다 보니 컨테이너에서 cgroup이 관리하는 파일시스템에 접근하게 되면 다른 컨테이너는 물론이고 호스트의 시스템 리소스까지 건드릴 수 있습니다. cgroup 네임스페이스는 cgroup 파일시스템(/sys/fs/cgroup)을 격리합니다.
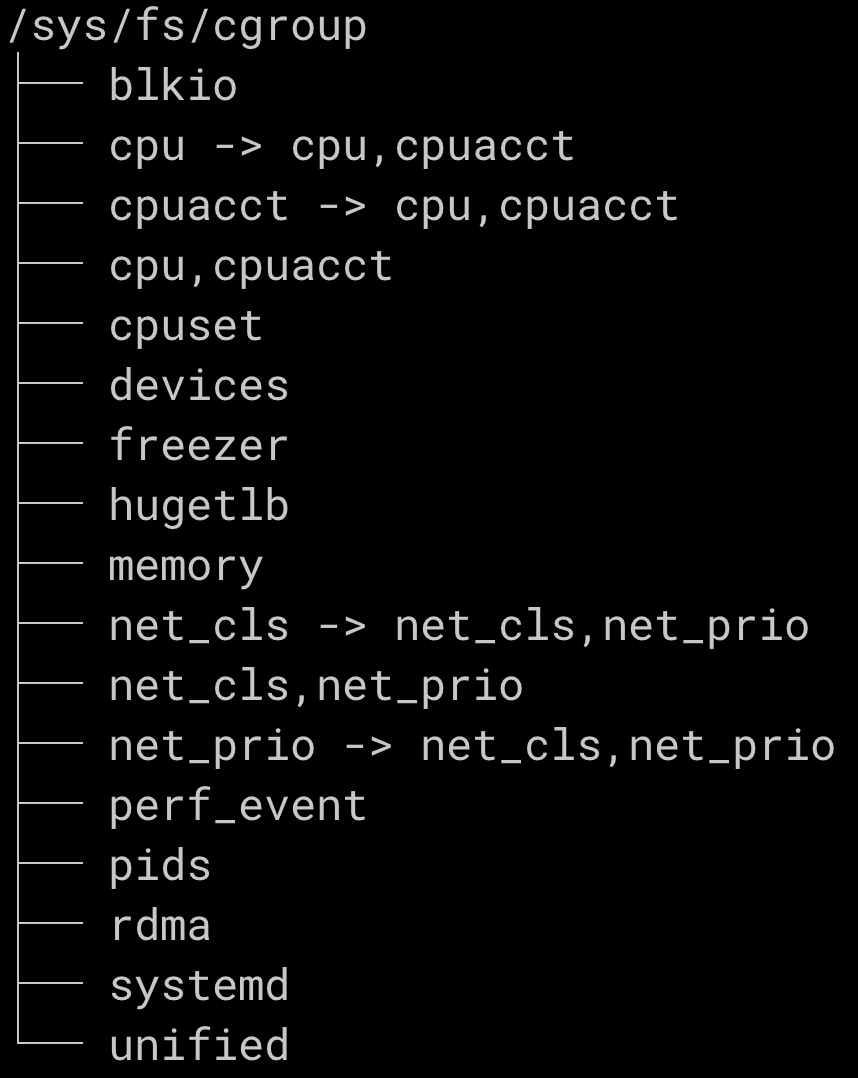
cgroup 파일시스템을 가볍게 살펴보도록 하겠습니다.
tree -L 1 /sys/fs/cgroup각 디렉터리가 cgroup으로 제어할 수 있는 리소스입니다.(참고) 디렉터리 이름으로 어떤 리소스를 제어하는지 쉽게 추정되는데요. cgroup에서는 디렉터리 각 항목을 "subsystem"이라고 합니다.
각 subsystem 디렉터리로 들어가면 해당 subsystem 을 제어하기 위한 다양한 파일들이 존재합니다. 예로 cpu 디렉터리 항목으로 들어가 보겠습니다.
tree -L 1 /sys/fs/cgroup/cpucpu 리소스를 제어할 수 있는 다양한 파일들이 존재합니다. cgroup.procs 파일에 프로세스 pid를 추가하면 해당 cgroup 제어를 받게 됩니다. 예를 들면 cpu.shares 수치를 조절하여 CPU TIME 가중치를 설정할 수 있고, cpu.cfs_quota_us 수치를 입력하여 CPU 사용률을 제어할 수 있습니다.
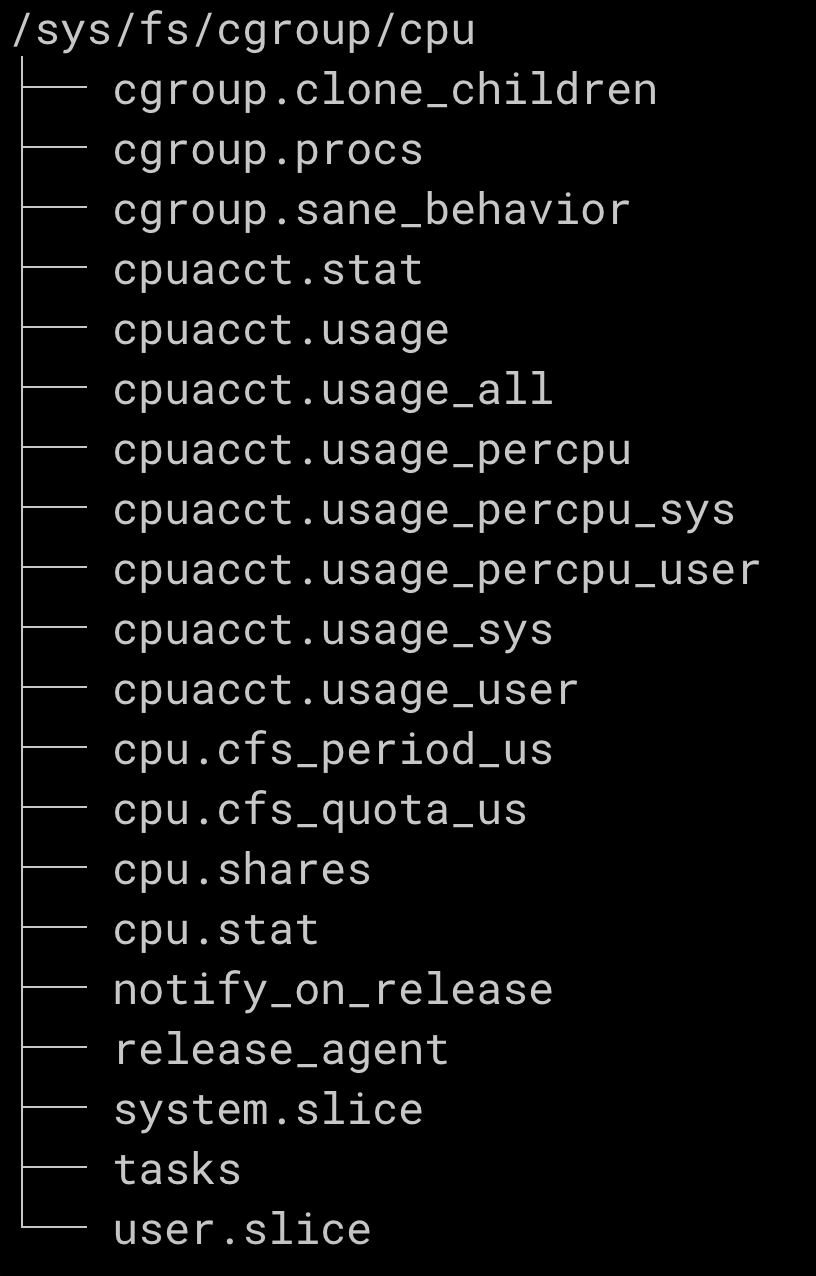
"리눅스는 모든 게 파일"이라는 얘기가 실감 나지 않나요. 이처럼 cgroup 파일시스템으로 다양한 호스트 리소스를 제어할 수 있기 때문에, 격리하여 컨테이너가 호스트 자원을 마음대로 주무르지 못하도록 제한할 필요가 있습니다. cgroup 네임스페이스는 컨테이너가 속한 cgroup 만 보이도록 격리합니다.
네트워크 네임스페이스
컨테이너 환경을 운영하다 보면 컨테이너 관련된 지식보다 네트워크 지식이 더 많이 요구됩니다. 향후 깊게 다뤄보기로 하고 여기서는 간단한 개념과 맛보기 실습을 진행해보겠습니다.
네트워크 네임스페이스는 컨테이너의 네트워크 스택(OSI 7 Layer)을 격리합니다. 이를 통해 호스트 안에서 컨테이너를 “가상” 네트워크 상 별도의 노드로 취급할 수 있습니다.

바로 만들어 보실까요. 호스트와 컨테이너의 네트워크 인터페이스 목록을 비교해 보세요. (호스트와 컨테이너의 네트워크 인터페이스 목록이 다릅니다) 네트워크 네임스페이스를 격리하면 네트워크 인터페이스뿐만 아니라 route table, iptables, arp table, bridge forward db 등 네트워크 관련한 모든 것들이 격리되어 따로 구성됩니다.
# 호스트 N/W 인터페이스 조회 ~ 기억해두세요
root@ubuntu1804:/tmp# ip a
# 네트워크 네임스페이스를 격리하여 bash 셸 기동
root@ubuntu1804:/tmp# unshare --net /bin/bash
# 컨테이너 N/W 인터페이스 조회
root@ubuntu1804:/tmp# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00이번에는 프로세스의 네트워크 네임스페이스 정보를 조회해 보겠습니다. 네임스페이스는 프로세스를 격리하는 것이므로 현재 격리한 셸 프로세스의 pid($$)와 격리하지 않은 호스트 프로세스(여기서는 pid 1)의 네임스페이스 정보를 비교해보면 됩니다.
lsns를 이용하면 namespace에 대해 더 많은 정보를 얻을 수 있습니다. 조회 타입(-t)을 네트워크(net)로 지정하였으므로 출력 결과의 맨 앞 NS 칼람은 네트워크 네임스페이스의 inode 값입니다. 현재 프로세스($$)와 init 프로세스 (pid 1)의 inode 값이 서로 다름을 알 수 있습니다. NPROCS 칼럼은 해당 네임스페이스에 포함된 프로세스 개수입니다. (호스트 네임스페이스의 프로세스 개수가 많습니다)
PID, USER, COMMAND 칼람은 해당 네임스페이스를 소유한 프로세스 정보를 나타냅니다.
root@ubuntu1804:/tmp# lsns -t net -p $$
NS TYPE NPROCS PID USER COMMAND
4026532270 net 2 20097 root /bin/bash
root@ubuntu1804:/tmp# lsns -t net -p 1
NS TYPE NPROCS PID USER COMMAND
4026531993 net 105 1 root /sbin/init
USER 네임스페이스
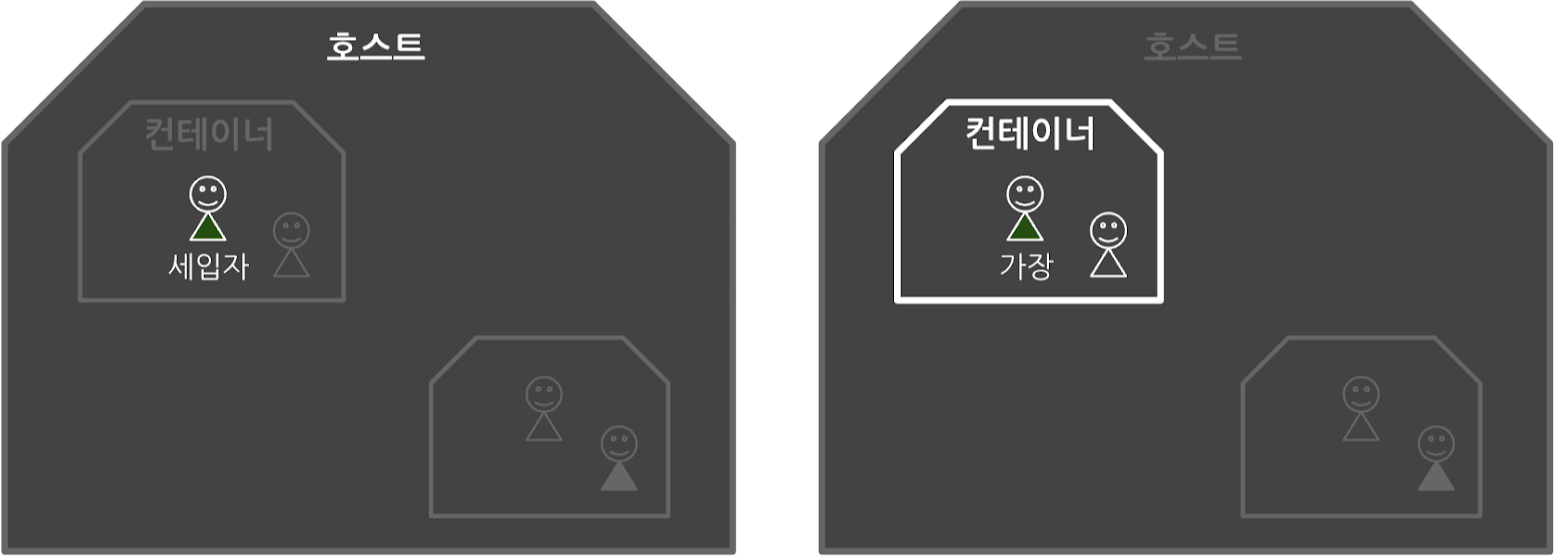
앞에서 chroot, pivot_root, 그리고 각종 네임스페이스를 루트 유저로 실습을 진행했는데요. 아무리 컨테이너가 유용하더라도 루트 유저로 실행하는 것은 보안상 매우 위험합니다. USER 네임스페이스를 이용하면 호스트에서는 권한이 최소화된 일반 유저지만, “컨테이너 안에서만 루트 유저”로 부여할 수 있습니다.
USER 네임스페이스는 2012년 Linux 3.5에 포함되었습니다. 지금까지 다룬 네임스페이스 중에서는 가장 최근에 개발되었고, 컨테이너 보안 관련하여 중요한 기능임에도 출시 이후로 10년 가까이 흘렀지만 정식 도입된 사례는 없었습니다.

USER 네임스페이스 적용이 까다로운 이유는 리눅스 배포판 및 커널 버전에 따라 구성 방법에 차이가 있고, 루트 권한을 제한하려다 보니 컨테이너 생성 자체가 어려운 경우가 있기 때문입니다. 그리고 이미지에 포함된 파일이나 호스트에서 컨테이너로 마운트한 파일, 디렉터리의 권한이 USER 네임스페이스의 권한과 상충되는 경우 등 해결해야 할 문제들도 있었습니다. 이런 이유로 발표 후 10여 년이 흘렀지만 도입이 쉽지 않았는데요. 최근 쿠버네티스 1.22 버전의 SecurityContext에 USER 네임스페이스 지원이 alpha 버전으로 추가되었고, 이는 흥미롭게 지켜볼 대목입니다. (여러분들은 컨테이너 역사의 중간에 있습니다.)
이번 실습은 루트가 아닌 일반 유저(vagrant)로 진행을 합니다.
1. 루트(root) 유저와 일반(vagrant) 유저 각각 id 명령의 출력을 비교해보세요. 커널은 uid, gid 값으로 현재 프로세스의 유저를 확인하는데요. 값이 '0' 이면 루트 유저입니다.
(참고) 커널은 uid, gid의 (숫자) 값으로 유저를 식별하고, root, vagrant와 같은 유저명은 알지 못합니다. 유저명은 커널이 아닌 외부 툴(/etc/passwd, LDAP, 커버로스 등)에서 uid, gid에 매핑한 정보입니다.
# 터미널 1 (컨테이너)
# 루트 유저의 id 조회 => uid=0(root)
root@ubuntu1804:/tmp# id
uid=0(root) gid=0(root) groups=0(root)
# root 쉘을 종료합니다
root@ubuntu1804:/tmp# exit
exit
vagrant@ubuntu1804:~$
# 일반 유저의 id 조회 => uid=1000(vagrant)
vagrant@ubuntu1804:~$ id
uid=1000(vagrant) gid=1000(vagrant) groups=1000(vagrant) ...
2. 이번에는 unshare로 USER 네임스페이스를 격리한 컨테이너에서 id를 확인해 보세요.
# 터미널1 (컨테이너)
# USER 네임스페이스를 격리하여 bash 실행
vagrant@ubuntu1804:~$ unshare --user /bin/bash
nobody@ubuntu1804:~$
3. id 출력을 보면 컨테이너의 uid(=65534)와 호스트(uid=1000)가 다릅니다. 컨테이너가 호스트와 다른 uid 값을 출력하는 이유는 USER 네임스페이스가 다르기 때문입니다. USER 네임스페이스는 (PID 네임스페이스처럼) 부모와 자식 네임스페이스가 중첩 구조로 되어있고, 자식 네임스페이스에서 부모 네임스페이스와 다른 uid/gid 값으로 remap 됩니다.
# 컨테이너 id 조회 ⇒ nobody(uid=65534) ⇒ vagrant(uid=1000) 아님
nobody@ubuntu1804:~$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)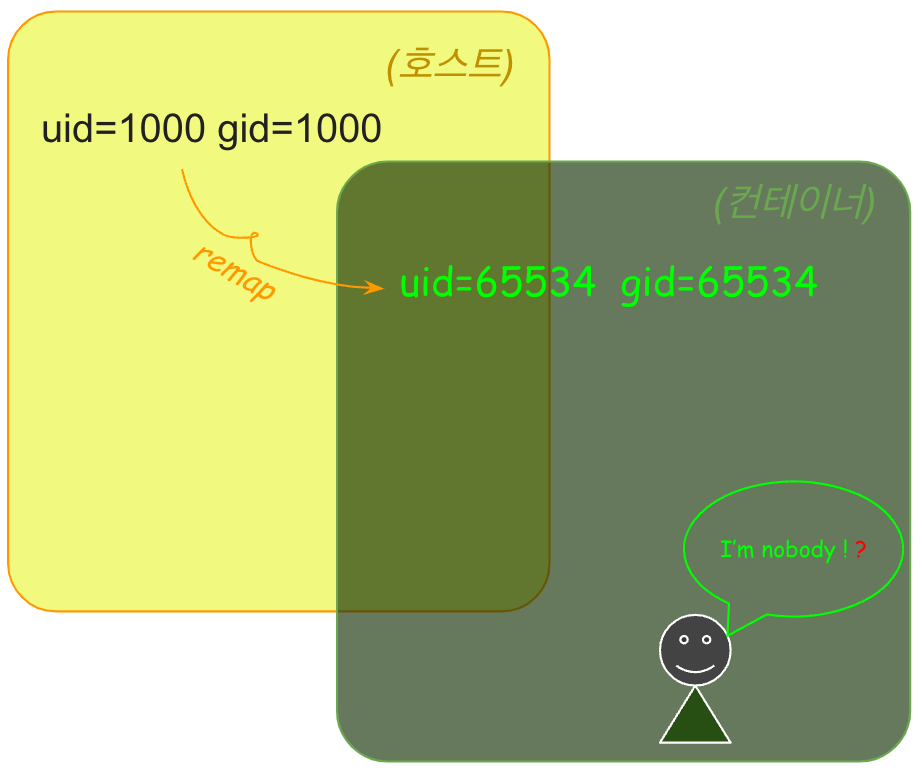
4. 현재 컨테이너의 권한을 확인해 보기 위해 컨테이너에서 UTS 네임스페이스 격리를 시도해 보세요. (권한이 없어 실패합니다)
# 터미널1 (컨테이너)
# UTS 네임스페이스 격리 시도
nobody@ubuntu1804:~$ unshare --uts /bin/bash
unshare: unshare failed: Operation not permitted
5. 컨테이너를 일반 유저(vagrant)로 실행하였기 때문에 UTS 네임스페이스를 만들 수 있는 권한이 없습니다. 현재 프로세스의 권한으로 (컨테이너 안에서) “할 수 있는 것들”(Linux Capabilities)을 조회해 보겠습니다. (아무것도 없네요) "Current: = " 현재 프로세스가 할 수 있는 것이 없습니다. (Current: Capabilities 가 비어있음) 호스트와 비교를 위해 프로세스 pid (여기서는 2781) 를 확인해 두세요. * 프로세스 pid (2781)는 실습환경마다 다릅니다.
# 터미널 1 (컨테이너)
# 현재 프로세스의 Capabilities 확인 ⇒ (없음)
nobody@ubuntu1804:~$ capsh --print | grep Current
Current: =
# 현재 pid(프로세스 ID) 확인
nobody@ubuntu1804:~$ echo $$
2781
6. 터미널 2를 열어서 호스트 상에서 살펴보겠습니다. 호스트도 일반 유저(vagrant)입니다. 호스트에서 프로세스 목록(ps -ef)을 조회하여 컨테이너의 pid (2781) 를 확인해 보세요. 해당 프로세스의 소유 계정이 vagrant로 보입니다.
# 터미널 2 (호스트)
# 호스트 USER 확인 => uid=1000(vagrant)
vagrant@ubuntu1804:~# id
uid=1000(vagrant) gid=1000(vagrant) groups=1000(vagrant)
#
vagrant@ubuntu1804:~# ps -ef
...
vagrant 2781 1875 0 03:36 pts/0 00:00:00 /bin/bash
...컨테이너(터미널 1)에서는 계정이 nobody였는데 왜 다른 계정으로 보일까요? 이는 USER 네임스페이스가 부모, 자식 중첩 구조로 프로세스의 유저 id가 컨테이너에서는 uid=65534 (nobody)이지만 호스트에서는 vagrant (uid=1000)이기 때문입니다.
이처럼 USER 네임스페이스는 "uid, gid의 number space를 격리"하는데요. 이때, 부모와 자식 네임스페이스 간의 uid, gid 매핑을 관리할 수 있습니다. (아래 더보기에서 예시 참고)
호스트(부모) 컨테이너(자식)
uid=1000 ⇒ uid=65534
uid=1001 ⇒ uid=65535
uid=1002 ⇒ uid=65536
부모/자식 네임스페이스 간의 uid 매핑 범위(range)를 설정할 수 있습니다.
그렇다면 컨테이너 안에서 uid=0(root)으로 지정되는 것은 어떤 의미일까요? 이어서 확인해 보겠습니다.
1. 터미널 2(호스트)에서 컨테이너 프로세스(2781)의 uid 값을 변경해 보겠습니다. 루트 권한이 필요하므로 sudo 명령으로 진행합니다.
자식 네임스페이스의 uid=0(root)으로 변경하고 부모 네임스페이스는 그대로 (uid=1000)입니다. 매핑 범위는 한 개(count=1)입니다.
# 터미널 2(호스트)
# 프로세스(2781) uid 매핑 변경 : 자식(uid=0) ⇒ 부모(uid=1000)
vagrant@ubuntu1804:~# sudo echo '0 1000 1' > /proc/2781/uid_map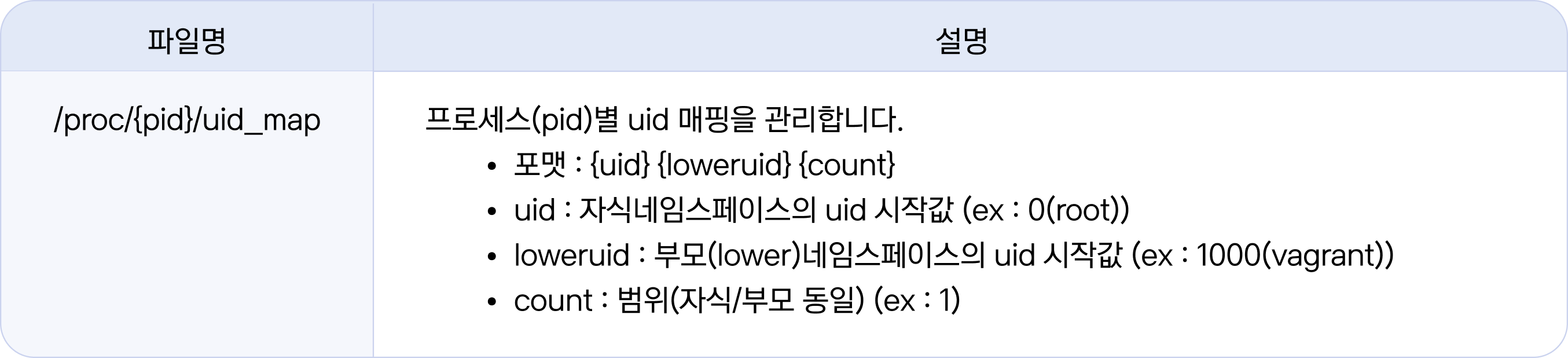
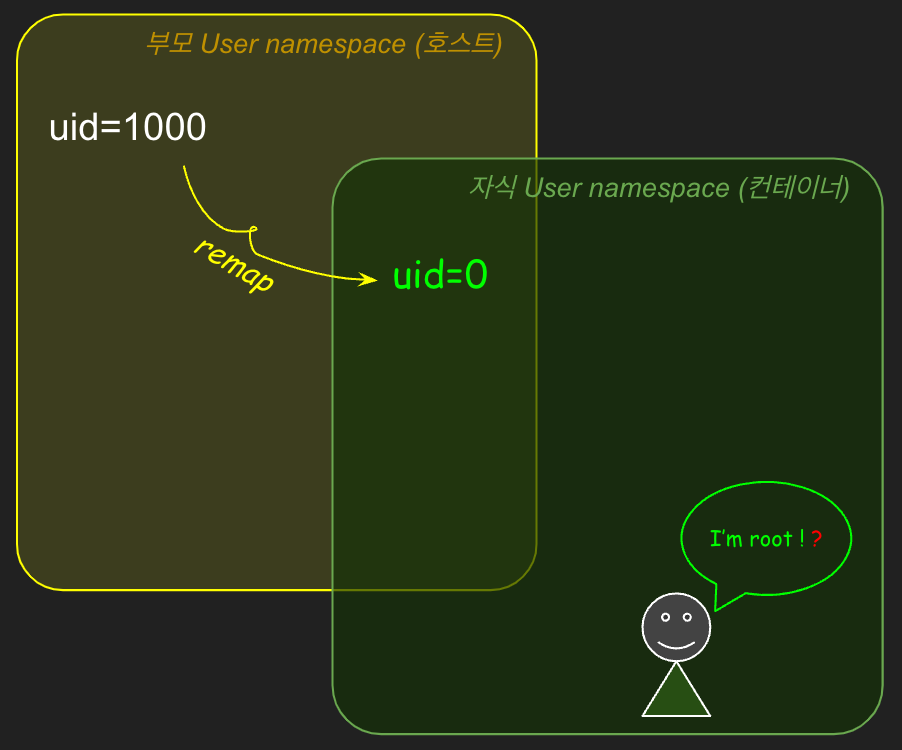
2. 다시 터미널 1(컨테이너)로 돌아와서 실습을 진행합니다. (uid=0으로 바뀌고 Capabilities도 출력됩니다.) 앞서 실행에 실패했던 UTS 네임스페이스를 격리하여 bash를 실행해보세요. (성공)
# 터미널 1(컨테이너)
# 컨테이너 id 조회 ⇒ uid=0(root)으로 바뀜
nobody@ubuntu1804:~$ id
uid=0(root) gid=65534(nogroup) groups=65534(nogroup)
# 현재 프로세스의 Capabilities 확인(있음, 엄청 많음)
nobody@ubuntu1804:~$ capsh --print | grep Current
Current: = cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,cap_wake_alarm,cap_block_suspend,cap_audit_read+ep
# UTS 네임스페이스 격리(성공)
nobody@ubuntu1804:~$ unshare --uts /bin/bash
# 호스트명 변경(성공)
root@ubuntu1804:~# hostname HelloSam
root@ubuntu1804:~# hostname
HelloSam호스트에서 컨테이너 pid(2781)의 uid 매핑을 변경하니 컨테이너의 uid가 0(root)으로 바뀌고, 비어있던 Capabilities가 채워졌습니다. USER 네임스페이스는 uid, gid 넘버스페이스를 격리하고 해당 uid, gid에 부여된 Capabilities 역시 컨테이너 안에서만 유효합니다. 즉 컨테이너 안에서는 root이지만 컨테이너 밖에서는 권한이 제한된 일반 계정(세입자, vagrant)입니다.
Linux Capabilities는 후속 연재 “4편: 컨테이너 격리와 제한”에서 User namespace와 함께 좀 더 자세히 살펴보겠습니다. 미리 더 확인해 보고 싶은 분들은 man 페이지를 참고해주세요.
지금까지 네임스페이스를 살펴보았습니다. 네임스페이스는 특정 자원에 대해 호스트로부터 컨테이너를 격리합니다. 네임스페이스에는 다양한 종류가 있고, 컨테이너의 "필요에 맞게 조합"하여 사용할 수 있습니다. 네임스페이스를 통하여 컨테이너의 "격리"와 "보안" 문제에 대한 해법을 얻었습니다.
마지막으로 컨테이너에 공급되는 CPU, Memory 등 시스템 리소스를 제한하는 방법을 살펴보겠습니다.
리소스 무제한 문제
chroot은 컨테이너가 사용하는 호스트 리소스를 제한할 방법이 없습니다. Cgroups을 이용하면 CPU, Memory 등의 리소스 사용을 제한할 수 있습니다.
Cgroups
컨테이너에 "리소스" 할당하기
각 세대에 전기, 수도, 가스 공급을 해볼까요
cgroup 네임스페이스가 cgroup 파일시스템 격리를 통해 컨테이너에서 함부로 호스트나 다른 컨테이너의 cgroup을 건드리지 못하도록 하였다면, Cgroups(Control Groups)는 cgroup 파일시스템을 통해서 호스트의 하드웨어 자원을 "그룹"별로 관리하는 모듈입니다. 관리할 수 있는 그룹에는 CPU, Memory, Network, Disk IO, Devices, ... 등 다양한 리소스들이 있습니다.
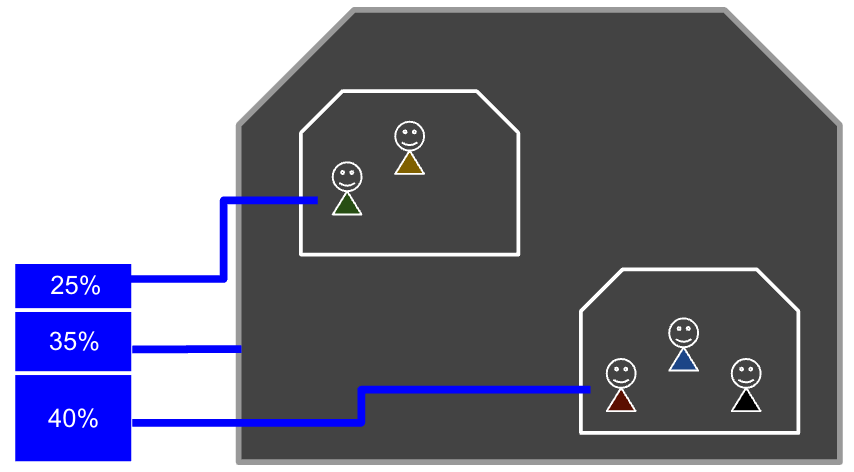
Cgroups는 하나 또는 복수의 장치를 묶어서 그룹을 만들 수 있고, 프로세스가 사용하는 리소스 총량은 Cgroups의 통제를 받습니다.
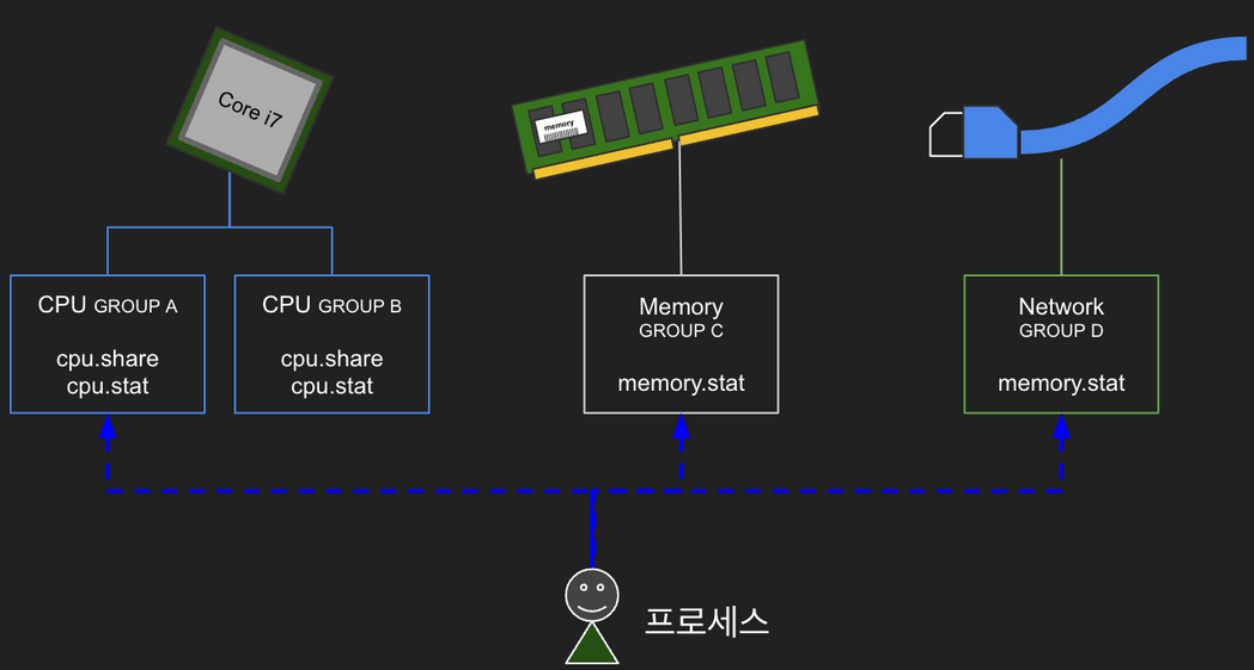
cgroup 네임스페이스에서 살펴보았듯이 Cgroups는 파일시스템으로 관리됩니다.
Cgroups를 이용하여 CPU 사용률을 제한해서 프로세스를 기동해 보겠습니다.
1. Cgroups 실습 도구를 설치하고, stress 툴을 실행합니다.
# 터미널 1
# cgroups 설정 및 관리 툴입니다.
root@ubuntu1804::/tmp# apt install -y cgroup-tools
# 스트레스 테스트 툴입니다
root@ubuntu1804::/tmp# apt install -y stress
# stress 실행 (-c 1: CPU 사용률 100%)
root@ubuntu1804::/tmp# stress -c 1
stress: info: [28302] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
2. 터미널 2에서 top 명령어로 %CPU(CPU) 사용률을 확인해보세요. stress 툴에 지정한 만큼 증가하는지 확인합니다.

3. COMMAND stress의 %CPU가 100.0 근방에서 변화를 보이는 것을 확인할 수 있습니다. CTRL+C 키를 눌러 터미널 1의 stress 실행을 멈춰주세요
4. 이번에는 cgroups 툴로 CPU 그룹을 생성하고 해당 그룹에 CPU 사용률을 30%로 제한하도록 할당하겠습니다.
# mycgroup을 생성(cgcreate)합니다.
root@ubuntu1804::/tmp# cgcreate -a root -g cpu:mycgroup
# mycgroup에 CPU 사용률을 30%로 제한하도록 설정(cgset)합니다.
root@ubuntu1804::/tmp# cgset -r cpu.cfs_quota_us=30000 mycgroup
# mycgroup으로 "stress"를 실행(cgexec)합니다.
root@ubuntu1804::/tmp# cgexec -g cpu:mycgroup stress -c 1
stress: info: [28629] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hddcpu 사용률 (%CPU) 계산 공식
(cpu.cfs_quota_us / cpu.cfs_period_us) * 100
* 1ms = 1000us
ex)
cpu.cfs_period_us = 100,000 (기본값)
cpu.cfs_quota_us = 30,000 (설정값)
%CPU = (30,000/100,000) * 100 = 30%
5. 터미널2(호스트)에서 top 명령어로 CPU 사용률을 모니터링해보세요.

"stress -c 1"로 동일한 옵션으로 실행했음에도 stress의 %CPU 값이 mycgroup에 설정된 CPU 사용률(30%)을 넘지 않는 것을 확인할 수 있습니다. 이렇듯 cgroups을 이용하면 cpu, memory 등의 리소스 사용을 제한할 수 있습니다.
마치며
지금까지 서버 다세대 주택 프로젝트 "컨테이너"를 설명드렸습니다. chroot로 시작하여 프로세스의 내 집 마련 과정을 시간순으로 따라가 보았는데요. pivot_root를 통해 무너지지 않는 확실한 집터를 준비하고, 전용 파일시스템 마운트, uts(명패), ipc(직통전화), pid(족보), 전용 네트워크 구성, cgroups(계량기), user(루트 권한) 등 다양한 네임스페이스 격리를 해보았습니다. 그리고 Cgroups으로 시스템 리소스를 제한하여 프로세스를 실행해 보았습니다. 한 땀 한 땀 해보신 이 과정들이 (도커가 만들어준 것과 같은) 컨테이너를 만드는 방법입니다.
본 "컨테이너인터널: 컨테이너 톺아보기" 편은 컨테이너를 이루는 기술들을 전체적인 맥락에서 이해하는 데 초점을 두고 작성하였습니다. 컨테이너 기술의 세부 항목들은 앞으로의 연재를 통해서 더 상세하고 재미있게 다뤄보도록 하겠습니다.
부족한 글 끝까지 읽어주셔서 감사드리고 컨테이너에 대해 마음에 드는 정의가 있어서 소개하고 마칠까 합니다.
| "Containers are processes born from tarballs, anchored to namespaces, controlled by cgroups" (출처) " 컨테이너는 타르볼에서 생성되고, 네임스페이스에 고정되며, cgroup에 의해 제어되는 프로세스입니다" |
🍪 아직 잠깐! 다음편 예고
다음 편은 "컨테이너 파일시스템"이라는 제목으로 마운트 네임스페이스와 오버레이 파일시스템을 해부합니다.
- 왜 마운트를 격리하였는지 리눅스 파일시스템 구조를 통해 더욱 상세히 알아보고,
- 프로세스 실행에 모든 걸 담고 있는 “이미지”에 대해 알아보겠습니다. 모든 걸 담고 있는 만큼 때에 따라 크기가 커지거나 중복이 발생할 수 있는데요. 이런 문제들을 어떻게 풀고 있는지 알아봅니다.
- 컨테이너가 저장소로부터 이미지를 내려받고 실행되는 과정과 변경되는 파일 처리는 어떻게 하는지 파일시스템 관점에서 다룹니다.

Sam (김삼영)
‘라이딩’과 ‘공부’를 좋아하는. 둘 다 ‘떼지어' 할 때가 가장 신나는 개발자입니다. 검색을 클라우드와 AI로 확장하는데 관심이 많습니다.




댓글