



시작하며
안녕하세요. 저는 Chaos 팀의 Ella(최윤주)입니다. Chaos 팀은 카카오 i 클라우드의 서비스 전체 및 서비스를 관리하는 주변 플랫폼들에 대한 품질 관리, 즉 QA(Quality Assurance)를 담당하고 있습니다. Chaos라는 팀명에서 유추할 수 있듯이, 저희 팀은 천지 창조 이전의 혼돈 상태를 질서와 조화를 지닌 세계로 탈바꿈하는 사명을 가지고 있는 셈이죠.
클라우드 서비스는 제가 이전에 경험했던 B2C 서비스 검증과는 조금 다릅니다.
B2C 서비스에서는 UI/UX에 비중을 두고 어떻게 하면 좀 더 사용자 친화적인 서비스를 만들어갈 수 있을지에 주안점을 두고 검증을 진행합니다. 예를 들어, '콘솔에서 인스턴스 상세 정보가 화면에 모두 잘 표시되는가?' '사용자가 정보를 보고 사용하기 어렵지 않은가?' '네트워크나 서버 장애 상황에서 콘솔 에러 페이지로 잘 전환되는가?' 등에 중점을 두게 됩니다.
반면 클라우드 서비스는 UI/UX보다 사용자들이 다양한 클라우드 리소스를 생성하고, 생성한 리소스를 사용하는 과정과 발생할 수 있는 장애, 문제점 등을 더 중요하게 검증합니다. 즉, '생성된 인스턴스에 데이터를 지속적으로 넣고 있을 때 인스턴스를 추가하더라도 유실되는 데이터가 없는가?'라는 다소 구체적이고, 실제 기능의 사용성에 더 중점을 두게 됩니다.
오늘 포스팅에서는 카카오 i 클라우드 서비스의 QA 검증 방식과 최근 3차까지 릴리즈한 Redis 서비스의 검증 여정을 소개하고자 합니다.
우리의 클라우드 서비스 검증 방식
많은 분들이 QA 테스트는 개발과 배포 과정의 마지막 테스트와 오류 검증만을 진행하는 것으로 알고 계신데요. 저희가 담당하는 클라우드 서비스의 검증 범위는 기획부터 개발, 배포, 개선 작업까지 일련의 작업을 모두 포함합니다. 서비스 검증 범위를 이렇게 확대하여 진행하는 가장 큰 이유는 무엇보다 서비스 안정성을 높이기 위함인데요. 클라우드의 고객은 컴퓨팅, 스토리지, 네트워크의 다양한 서비스를 이용하여 가상화된 인프라 환경을 구성합니다. 클라우드 서비스 제공자 입장에서는 각각의 서비스 안정성을 높여 고객의 클라우드 환경 구성이 문제없도록 제공해야 하는 의무가 있죠. 따라서 무엇보다 서비스 검증의 역할이 중요하다고 볼 수 있습니다.
아래 다이어그램에서 볼 수 있듯이, 클라우드 서비스의 전반적인 QA 과정은 기획에서부터 서비스 개발 사이클의 모든 과정에 걸쳐 진행됩니다. 간략하게, 고객이 기대하는 서비스의 안정성을 위하여 모든 작업에 QA가 개입하고 있다고 해도 무방합니다.
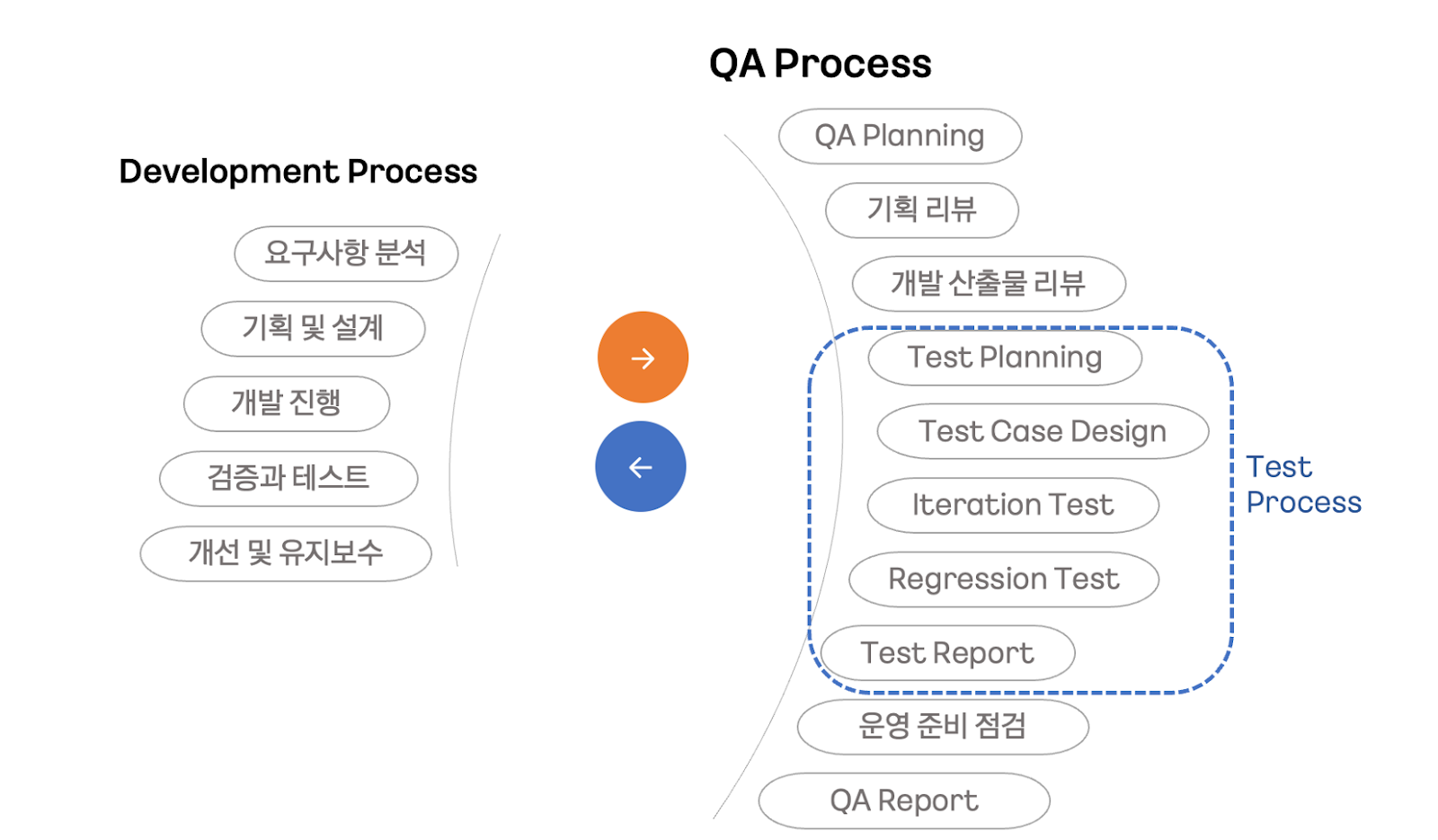
QA 프로세스의 첫 단계인 QA Planning 단계에서는 전반적인 품질 요건 달성을 위한 계획을 수립합니다. 각 서비스의 릴리즈 범위를 식별하고, 검증이 필요한 기획/개발 산출물, 향후 로드맵이나 마일스톤 등을 확인합니다. 다음 기획 리뷰 단계에서는 서비스 이해를 높이고, 서비스 개발에서 발생할 수 있는 기능적, 사업적 리스크가 있는지 식별합니다. 또 유저 스토리를 기반으로 철저히 사용자 중심의 서비스 정책, 기능 정의, UI/UX 관점의 개선 사항 등을 명확히 확인합니다.
개발이 진행되는 동안에도 개발 산출물 리뷰는 계속됩니다. QA 담당자는 서비스 아키텍처와 서비스 명세를 기반으로 정의된 Specification을 보다 명확히 하고, 다른 서비스와의 의존성으로 발생할 수 있는 Risk 식별, 테스트 환경 및 실제 환경에서의 테스트 수행의 제약사항 식별 등의 관점에 집중하여 개발 산출물을 리뷰합니다.
위 단계가 끝나면 이제 본격적인 테스트 프로세스(Test Process)에 진입합니다. 앞서 전반적인 서비스 수준을 위한 검증의 계획과 범위를 파악했다면, 이 프로세스에서는 테스트 수행에 필요한 직접적인 작업을 진행합니다. 각 단계의 특성은 아래 표에서 간략하게 소개해드릴게요.
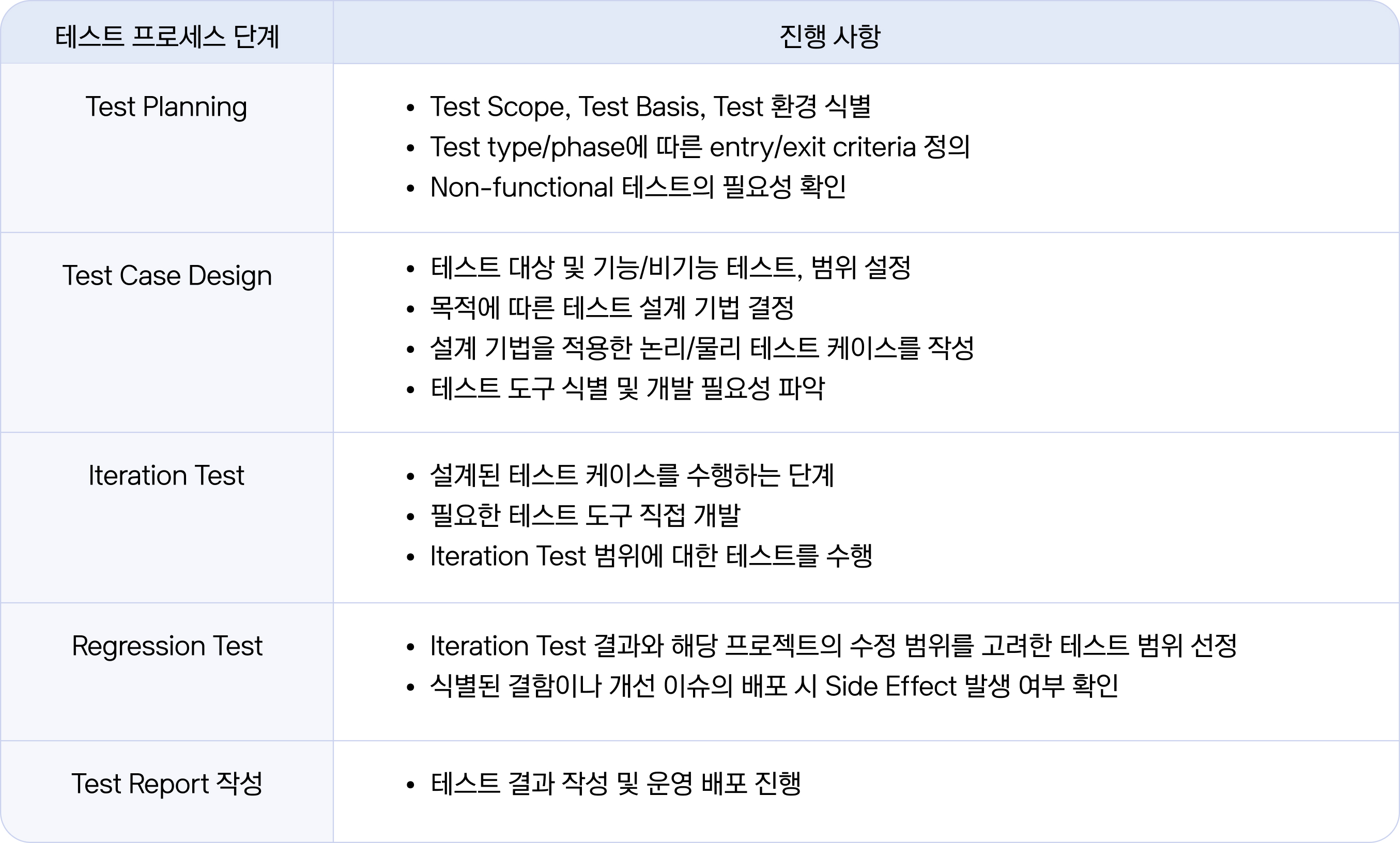
이 프로세스 이후에 운영 준비 점검 단계를 거친 뒤, QA 계획에 따라 QA 결과를 정리한 Test Report를 작성하면 일련의 프로세스가 마무리됩니다. 대부분의 클라우드 서비스가 이와 같은 프로세스로 검증이 이루어지는데요. 실제로 가장 중요한 것은 각 서비스의 특성을 이해하여 검증 목표를 잘 설정하면서 테스트를 진행해 나가는 것입니다.
Redis 서비스의 검증 여정
앞서 카카오엔터프라이즈의 클라우드 서비스 검증 방식을 소개해 드렸는데요. 이번에는 카카오 i 클라우드의 Redis 개발 여정을 '서비스 검증' 관점에서 자세히 소개해보려고 합니다.
Redis는 Key-Value(키-밸류) 구조의 비정형 데이터를 메모리에 저장하여 사용할 수 있는 NoSQL DB로, 모든 데이터를 메모리에 저장, 관리하므로 빠른 처리를 보장합니다. 카카오 i 클라우드에서 제공하는 Redis 서비스는 이러한 Redis DB를 운영자의 도움 없이 자동으로 운영, 관리해 주는 서비스입니다. 자세한 내용이 궁금하시면 카카오 i 클라우드 공식 사이트에서 확인하실 수 있습니다.
카카오 i 클라우드의 Redis 서비스의 경우, 출시를 3차(R1, R2, R3)에 걸쳐 진행했는데요. 각 릴리즈 시점에 QA에서 중점을 두었던 점들이 조금씩 달랐지만, Redis 서비스 검증의 핵심 목표는 '사용자를 위해 유실 없는 데이터의 안정적인 저장과 빠른 처리를 확인하는 것'이었습니다. 이를 위해 Redis에 입력한 Key-Value 데이터가 유실 없이 저장되고, 처리되는 과정에 중점을 두어 테스트를 수행해야 했습니다. Redis 인스턴스가 화면에 잘 생성되었다고 검증이 끝난 것이 아니고, 실제로 Redis를 통해 데이터를 읽고 썼을 때 유실 없이 모든 데이터가 조회되는지까지 확인하는 일이 중요한 것이죠.
그럼 각 릴리즈 시점에 맞춰 QA에서 테스트에 중점을 두었던 부분과 고민했던 부분들을 공유드려 보겠습니다.
1st Release | Single Instance
첫 번째 릴리즈에서의 Redis는 Single 인스턴스로 프로비저닝 되는 단계였습니다.
일반적으로 서비스 검증 항목은 기능 테스트와 비기능 테스트 확인으로 나뉘는데요. 첫 기능 테스트 검증 범위는 Redis 생성-조회-수정-삭제가 잘 되고, Redis connection을 맺은 후 Key-Value read/write에 이상이 없는지, 유실되는 데이터가 없는지에 대해 확인하는 것으로 잡았습니다. 비기능 테스트 측면으로는 Failure Test를 진행하여 장애 상황에서 서비스가 정의된 대로 작동하는지 확인하는 것을 계획하였죠.
Redis 테스트 방식 설계
우선 테스트를 구현하기 위하여 API Test Code를 작성하고 주기적으로 Redis 인스턴스의 Provisioning, Connection, Key-Value Read/Write, Delete까지 일련의 동작을 확인하기 위한 계획을 세웠습니다. 또한, 검증을 위한 테스트 케이스 설계를 진행하였습니다. Redis CLI 명령어를 파악하고, 팀원들과 내부 Test Case Review 시간을 통해 좀 더 보완할 테스트 케이스가 있을지, 불필요하거나 잘못된 정보를 기반으로 설계된 케이스는 없는지 검토했습니다.
첫 번째 릴리즈에서 가장 고민했던 부분은 테스트 자동화 구현이었는데요. 자동화 구현 범위는 생성 - 조회 - 삭제 케이스인 'Redis 인스턴스 생성, 프로비저닝 → Key-Value 데이터 세팅 → 인스턴스를 삭제'로 정했습니다. 코드화하는 과정에서 첫 단계인 'Redis 인스턴스 생성과 프로비저닝'에 대한 서비스 검증의 초기 방향을 잡는데 애를 먹었습니다. 예를 들면, 'Redis 인스턴스에 접근하기 위한 VM 생성 필요 → Redis 인스턴스 생성 → 생성된 VM에 (SSH 접근을 하여) Redis 인스턴스 CLI를 통해 접근'으로 구분하더라도 VM에 SSH 접근을 한 후 Redis CLI를 사용하기까지의 코드 작성이 쉽지 않아 많은 시간을 할애했습니다.
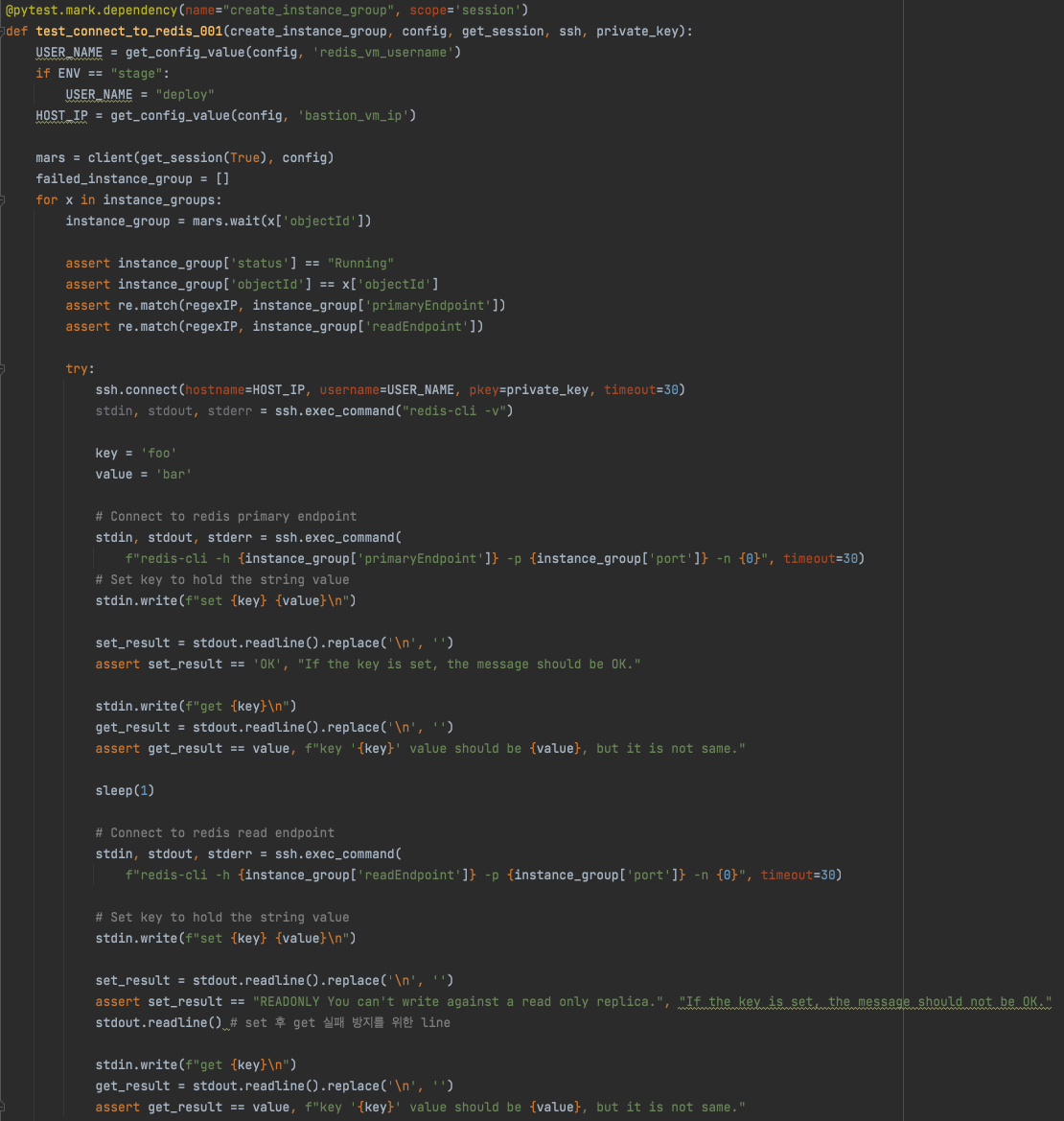
또, 각 과정이 서로 의존성을 갖지 않고 독립적으로 진행되도록 하는 것이 좋을지, 한번 테스트가 실행될 때 생성한 인스턴스로 조회, 삭제까지 확인하는 하나의 과정으로 구성하는 것이 좋을지에 대해서도 많이 고민했습니다. 지금 테스트 흐름을 잘 잡아두어야 이후에 코드 유지보수에도 문제가 없고, 테스트도 효율적으로 동작할 수 있을 테니깐요.
결국, 매번 Redis 인스턴스를 생성하고 삭제한다면 각 케이스 간 의존도는 없어지겠지만 테스트가 한번 수행될 때 걸리는 시간이 매우 길어진다는 단점을 해소하기로 했습니다. 따라서 매번 Redis 인스턴스를 생성 후 삭제하지 않고, 생성한 인스턴스로 조회 및 데이터 Read/Write까지 한 후 삭제해 보자는 결정을 하고 코드를 구현하였습니다. 이렇게 구현된 테스트 케이스와 API test를 통해 첫 번째 릴리즈 범위에 대한 검증을 본격적으로 진행하였습니다.
첫 Redis 검증의 아쉬움
아무래도 Redis에 대한 서비스 지식과 경험이 거의 없었던 상태였기에 아쉬움이 남을 수밖에 없지만, 짧은 시간 내 서비스에 대한 이해도를 빠르게 높이고자 정말 많은 참고 자료를 찾아보고 담당 개발자와 밀접하게 협업했습니다. 그러면서 테스트 코드를 설계하고 검증하고, 수정하면서 계속 완성도를 높여 나갔죠. 매일 1시간 간격의 테스트 코드 실행에서 개발자조차 미처 예상하지 못한 Redis 인스턴스 문제 상황을 발견하기도 했습니다. 어렵사리 구현해 둔 테스트 코드 덕분에 여러 상황에서 이슈를 발견하고 개발 측면에서도 대응할 수 있었습니다.
이렇게 첫 번째 릴리즈는 Redis에 대해 알아가고, 알아낸 지식을 검증하는 과정에서 테스트 자동화 구현까지 적용해 나갔던 고된 시간이었습니다. 하지만 이렇게 돌이켜보니 가장 힘들면서도 재밌는 요소들이 가득했던 시간이기도 하네요.
2nd Release | Instance Group
두 번째 릴리즈에서 Redis는 Instance Group 기능과 사용자가 인스턴스 장애 상황에서 Switchover, Scale In/Out을 통해 수동으로 장애 상황을 복구할 수 있는 기능을 함께 제공하게 되었습니다.
첫 번째 릴리즈에서는 단일 인스턴스를 생성하고 Key-Value read/write에 이상이 없는지 확인했다면, 이번에는 인스턴스 그룹으로 구성되었을 때 지속적으로 유입되는 데이터를 유실 없이 저장하고 있는지, 장애 복구 과정에서 문제가 없는지, 장애 복구 예상 시간 등에 대한 중점적인 확인이 필요했습니다. 따라서 Redis 인스턴스 그룹의 CRUD 기능 검증은 기본으로 진행하되, 데이터가 지속적으로 인입되는 상태에서 Switchover 하는 경우에 대한 데이터 검증을 병행해야 했습니다.
여기서 두 가지의 검증을 위한 난관을 겪게 됩니다. 대량의 데이터를 지속적으로 인입해 주는 툴과 Switchover 후에 데이터의 정합성 확인입니다.
대량의 데이터 생성 이슈
먼저, 대량의 데이터를 지속적으로 인입시키기 위해 Python을 통해 Redis Primary 인스턴스에 접근하여 임의의 Key-Value 데이터를 반복적으로 넣어주는 툴을 구현해 보았습니다. 하지만 이 툴은 초당 100건도 안 되는 데이터를 넣는다는 한계점이 있었습니다. 물론 데이터를 지속적으로 넣어준다는 목적은 달성하고 있지만, 일반적으로 Switchover가 발생하는 실제 상황에서는 많게는 Redis 인스턴스 메모리의 40~50%를 쓰고 있을 것이라 이 상태로는 두 번째 릴리즈 검증이 끝날 때까지도 데이터가 메모리에 충분히 쌓이지 않는 상황이 발생하게 되는 문제가 생긴 것입니다. 테스트 목표는 인스턴스 메모리의 70~80% 정도를 사용하고 있을 때 Switchover를 확인하는 것이었기 때문에, 짧은 시간 안에 대량의 데이터를 넣을 수 있는 방법이 필요했습니다. 무자비한 리서치 과정을 통해 Redis 인스턴스에 대용량 데이터를 밀어 넣는 방법을 찾았습니다. 결국 아래와 같은 검증 프로세스를 구현했습니다.
Bash 명령어로 Redis Key-Value를 반복적으로 넣어주는 여러 명령어 구성 (txt파일) → Redis와 connection을 하기 위한 VM에 업로드 → Redis pipe mode를 이용해 대량의 data를 삽입
이렇게 구성한 툴은 1억 개의 Redis Key-Value를 단 몇 분 만에 넣을 수 있기 때문에 어느 정도 데이터가 쌓여있는 Redis 인스턴스 그룹을 구성할 수 있게 됩니다. 이후에 Key-Value 데이터를 지속적으로 넣는 툴을 사용하여 테스트 상황을 만들어 대량의 데이터를 인입해 주는 툴에 대한 고민은 해결할 수 있었습니다.
데이터 정합성 이슈
이제 'Switchover 후에 데이터 정합성은 어떻게 확인할 것인가?'에 대한 문제만 남게 되었습니다. 여기서 데이터 정합성은 Switchover 후에도 Primary 인스턴스와 Replica 인스턴스의 내부 Key-Value 데이터가 유실 없이 동일한 데이터를 갖고 있는지를 확인하는 것을 의미합니다.
데이터 정합성 이슈를 다루기 위해 저희는 Source Redis와 Target Redis를 대상으로 Data Verification을 수행하는 RedisFullCheck이라는 툴을 사용했습니다. 여기에 Switchover, Scale In/Out 등의 기능을 검증하는 테스트 케이스도 설계하였습니다. API Test Code도 이번 릴리즈 스펙에 맞춰 유지보수하는 작업을 병행하였습니다.
이번 서비스 검증 작업은 이렇게 툴과 케이스를 잘 설계한 뒤 시작할 수 있었습니다. 먼저 partial sync, full sync 상황에서 승격 처리 시작을 측정하였습니다. Scale out → switchover → scale in 적용할 때 사용자가 얼마의 시간 동안 데이터를 사용하지 못하는 지를 확인하였습니다. 여기서 특정 인스턴스 flavor의 경우 switchover 상황에서 약 18분가량 데이터를 읽지 못하는 이슈를 발견하기도 하였습니다. replica가 2개인 상황에서 primary가 replica health check를 위해 ping 시도를 계속했고, ping 개수만큼 데이터 sync가 맞지 않아 full sync 발생으로 지연되는 것이었죠. 바로 개발팀의 조치가 이루어졌습니다. 미리 설정한 검증 툴과 설정한 시나리오 상황에서 이슈를 확인할 수 있어서 다행이었습니다. Redis 서비스에 대한 이해도 또한 더 깊어졌습니다.
반면에, 계속 새로 생성된 Redis 인스턴스 그룹에 데이터를 어느 정도 넣고 Switchover, Scale In/Out 하는 부분을 직접 수동으로 하려니 번거로운 부분이 있었습니다. 다음 릴리즈에는 꼭 테스트 자동화 코드에 녹여내서 일정한 서비스 품질을 제공할 수 있게 해야겠다고 다짐했습니다.
3rd Release | Redis 고가용성(High Availability)
세 번째 릴리즈에서는 Auto Recovery(자동 복구) 기능이 추가되었습니다. 두 번째 릴리즈에서 Redis 인스턴스에 장애 발생 시 사용자가 해당 인스턴스를 직접 처리하였던 부분이 자동으로 복구되도록 개선된 것인데요. 이에 따라 Redis 인스턴스에 장애 발생 시 사용자의 개입 없이 시스템적으로 장애가 발생한 인스턴스를 제대로 복구하는지가 중요한 검증 목표가 됩니다.
복잡한 장애 상황을 고려한 서비스 검증
가장 먼저, 장애 상황을 유발할 수 있는 방법에 대한 확인이 먼저 필요했습니다. 장애가 발생할 수 있는 다양한 경우의 수를 고려해야 했습니다. 서비스 출시를 위한 시간적인 제약이 있는 상태에서 실제 운영 시 발생 가능성이 있는 장애 상황에 우선순위를 두어서 검증을 시작했는데요.
고가용성 기능을 사용하는 상태에서 Primary, Replica의 다양한 조건 조합을 통해 꽤 많은 케이스를 도출했습니다. Primary 1대, Replica가 최소 1대 ~ 4대 일때의 조건, Primary만 장애가 발생했을 때, Replica 1대만 장애가 발생했을 때, Replica가 전부 장애일 때, Primary/Replica가 전부 장애일 때 등등. 또 Redis 인스턴스 그룹의 Memory를 60% 정도 사용했을 때, 80% 이상 사용 중일 때, 데이터를 연속으로 넣고 있을 때의 상태 등도 고려가 되어야 했습니다. 대체 경우의 수가 몇이나 되는 거죠? *.*
각 상황에서 장애 처리 과정도 상이하기 때문에, 주어진 시간 안에 최대한 많은 테스트를 해볼 수 있는 테스트 케이스를 구성하는 것이 필요했습니다. 중요한 이슈인 만큼 팀 내 Test Case 리뷰 과정을 거쳐 케이스를 도출하고 우선순위를 정했습니다. 테스트 케이스를 수행하기 위해 Redis 인스턴스 그룹을 생성하고, 데이터를 넣어 각 장애 상황을 발생시키며 테스트하기로 결정했습니다. 시간이 많이 소요될 수밖에 없었지만, 장애 상황을 하나하나 구현하고 상세히 살펴보기 위한 결정이었죠. 이후에는 테스트 자동화 코드 유지보수 작업을 진행할 예정이지만, 이 단계에서는 변경된 API Spec에 맞게 대응해 주는 작업까지만 병행했습니다.
Iteration Test 단계에서는 설계된 테스트 케이스를 통해 인스턴스가 Fail, Warning 상황에 빠졌을 때 직접 Switchover나 Scale In/Out을 할 필요가 없는 게 정말 맞는지 확인했고, 가장 중요한 장애 복구 후 유실된 데이터가 없는지를 확인했습니다.
직접 장애 상황을 만들며 진행했기 때문에 테스트 케이스 1개를 수행하기 위한 시간이 꽤 소요되었습니다. 한번 세팅한 장애 상황에서 실수로 장애 시나리오를 정확히 맞추지 못하거나, 갑자기 다른 업무가 생겨서 장애 발생 시간을 놓치게 되면 또다시 테스트할 수 있는 상황을 만들어내야 하는 일도 생겼죠. 만약 테스트 자동화를 빠르게 구현하여 주기적으로 반복 실행되었다면, 일정한 장애 상황이 각 케이스 별로 수행이 될 수 있었을 것이고, 또 테스트 환경의 리소스가 갑자기 부족해진 경우나 혹은 다른 서비스에서 장애가 발생하여 Redis까지 영향을 주는 경우 바로 테스트 결과를 모니터링할 수 있었을 것입니다. 테스트 코드를 좀 더 빠르게 구현했으면 더 도움 되지 않았을까 하는 생각도 들었습니다.
결과적으로는 열정을 불사르며 일정을 맞춰 진행한 이번 검증은 설계된 테스트 케이스의 조건들을 모두 통과하였고, 무사히 릴리즈까지 마무리하였습니다.
Next Step
이렇게 세 번의 릴리즈를 거치면서 Redis는 저에게 자식 같은 서비스가 되었습니다. 어느 정도 도메인 지식도 쌓게 되었고요. 하지만, 지금까지 QA 활동을 진행하면서 가장 아쉬웠던 점은 적시에 테스트 코드를 구현하지 못했던 것입니다. 다시 한번 테스트 자동화 코드에 대한 중요성을 스스로 느낄 수 있었습니다.
곧 예정된 Redis 네 번째 릴리즈에서는 Cluster Mode가 지원됩니다. 이전 단계에서는 하나의 Instance Group 내에서 고가용성 기능을 통해 안정적으로 데이터를 관리했다면, Cluster Mode에서는 Sharding과 고가용성 기능을 통해 더 안정적으로 데이터를 관리할 수 있게 됩니다. Redis 서비스에서는 큰 변화이기에 기획에서 개발까지 관련된 모든 크루들이 머리를 맞대고 안정된 기능과 성능을 제공하고자 열심히 달려가고 있습니다.
QA 담당자인 저도 다음 릴리즈에서는 서비스 검증 측면에서는 지난 단계에서 아쉬웠던 장애 케이스별 서비스 검증 자동화를 좀 더 면밀히 준비하고 있습니다.
마치며
네 번째 릴리즈까지 마무리되면 Redis 서비스 검증의 하이라이트라고 할 수 있는 테스트 자동화 설계와 이 서비스의 안정적이고 뛰어난 성능에 대해 보여드리는 글을 한편 더 써보겠습니다. 실제 엔터프라이즈 고객이 궁금해하는 클러스터에 대한 성능까지 보여드릴 수 있도록 제대로 준비해서 소개해드릴께요.
마지막으로 이 글에서 소개해드린 치밀한 서비스 검증 과정과 클라우드에 진심인 저희들의 이야기는 다른 어떤 클라우드보다 안정적이고 성숙한 서비스를 제공하겠다는 다짐에서 시작된다는 사실을 기억해 주시면 좋겠습니다.
클라우드에 진심인, 서비스 검증에 제대로인, 저와 Chaos 팀의 이야기를 읽어주셔서 감사합니다.
앞으로도 카카오 i 클라우드에 더 많은 사랑과 관심 부탁드리겠습니다.

Ella (최윤주)
손발은 차지만 일할 때만큼은 뜨거운, 열정 가득한 QA Engineer 입니다.




댓글