



2부 : 오픈 대화를 위한 다양한 기술
이번 외개인아가 특집 제2편에서는 외개인아가에 숨겨진 AI 기술을 살짝 시원하게(?) 공개해 보려고 합니다. 스몰톡을 구현하기 위해서는 멋진 개발자(feat. 똑똑한 언어 모델)와 센스있는 기획자의 조합이 중요한데요. 이들이 어떻게 조화를 이뤄 외개인아가를 탄생시켰는지, 외개인아가는 어떻게 성장하고 있는지 지금부터 한번 소개해 볼게요.
먼저! 오픈 도메인 챗봇인 외개인아가에는 1. 시나리오화되어 기획자의 의도에 맞게 통제가 가능한 영역과, 2. 시나리오로 만들어 두지 않고 모델에게 전적(?)으로 위임해서 처리하는 영역이 있어요.
시나리오화 작업은 “이런 의도의 말이 들어왔을 땐, 이렇게 대답해줘”라고 설정하는 작업이라고 보면 되는데요. 이 작업은 생각보다 많은 정성이 들어갑니다. 기획자의 피, 땀, 눈물... AI 시대에 AI 서비스 디자인을 하는 사람으로서 이런 작업을 하는 건 참 재밌긴 하지만😇 한편으로는 (가끔) 현타도 와요(직녀도 아닌데 인공지능을 이렇게 한 땀 한 땀 수 놓아서 구현하는 것이 맞나 싶고….😊). 그리고 뭐 사실 제가 하고 싶다고 사용자가 할 법한 모든 말들을 시나리오화할 수도 없고요. 사람들이 맨날 똑같은 말만 하는 것도 아닌 데다가 요즘은 하루가 멀다 하고 새로운 말도 많이 생겨나니까요. 그래서 우리가 어느 정도 예상해서 분류해둔 시나리오 이외의 말들을 해결해 줄 수 있는, 커버해줄 수 있는! 기술도 필요했답니다. 지금부터 이 두 가지를 좀 더 자세히 구분해서 소개해 볼게요. 😉
기획자 손바닥 위에 있는 시나리오 처리하기
외개인아가 제작 과정에서는 외개인아가의 페르소나와 관련된 대화나, 사용자들이 많이 발화할 것 같은 대화를 ‘시나리오’로 만들었어요. 시나리오 처리를 위한 모듈은 여러 가지가 있는데, 가장 쉬운 방법은 봇을 만드는 빌더의 인텐트(intent)를 활용하는 거예요. 외개인아가는 카카오 i 오픈빌더의 인텐트를 사용했죠. 하지만 인텐트는 동일한 의도를 가진 유사한 발화의 집합이기 때문에 스몰톡의 모든 시나리오를 인텐트로만 구현하기에는 어려운 점이 많아요. “밥은 먹고 다니냐?”와 “밥 먹었냐?”라는 질문을 모두 ‘밥을 먹었냐’와 동일한 의도로 이해하고, “저 밥 먹었어요.”라고 답변할 수 있지만, 인간미가 없는 기계적인 답변이라는 점에서 아쉬움이 남을 수 있잖아요? 약간의 뉘앙스 차이를 잡아내는 것이 스몰톡의 묘미인데 말이죠. 그래서 외개인아가의 인텐트는 대략적인 ‘대화 주제’로 활용할 발화만 묶어두고 세세한 뉘앙스 차이는 다른 모듈에서 판단하도록 했어요.
좀 더 구체적인 진짜(?)같은 이야기를 담아내기 위한 검색 모듈도 만들었어요. 사용자가 많이 할 법한 질문과 답변 셋을 미리 만들고, 검색을 통해 유사한 답변을 찾아주는 모듈이에요. 이 모듈의 장점은 답변이 구체적이어서 외개인아가가 약간 똑똑하고 센스있다는 느낌을 줄 수 있다는 점이지만, 반대로 답변이 핏(fit)하게 들어맞는 상황이 적어서 답변 자체가 잘 안 나간다는 것이 단점이에요. 😇
인텐트와 검색 모듈의 단점을 어느 정도 커버할 수 있는 모듈로, 사용자 발화의 화행과 엔티티를 파악하여 원하는 답변을 제공할 수 있는 모듈도 있어요. 예를 들어, 아래처럼 회사/직장의 엔티티와 함께 ‘관두다’라는 동사가 있는 발화의 답변을 정해진 답변으로 제공하고 싶을 경우, 사용자 화행에 따라 적절한 답변을 제공할 수 있어요.

“ㅋㅋㅋㅋㅋㅋㅋㅋ", “ㅇㅈ", “ㅅㅏ줘"와 같은 초성이나 깨진 문장, 🍎처럼 이모지를 입력하거나 이미지나 동영상, “....”와 같은 문장부호로만 이루어진 발화와 같이, 대화 데이터라고 하기에는 모호하지만 채팅에서 빈번하게 나오는 발화들을 처리하기 위한 모듈도 있습니다. 변형이 심한 언어나 특정한 의미를 가지고 있는 기호들은 사람이 봤을 땐 쉽게 알아차릴 수 있지만 컴퓨터가 이를 분석하려면 많은 모듈이 필요한데요. 특히 한국어의 경우, “인터넷 용어", “채팅 용어"를 분석하는 글이나 영상이 있을 정도로 언어의 변형이 많아서 컴퓨터가 분석하기 힘들답니다. 😱
미처 손바닥에 올려두지 못한 발화 커버하기
앞서 설명드린 여러 모듈을 탑재하고, 꽤 많은 케이스에 대해서도 시나리오 작업을 해뒀지만 여전히 롱테일(long-tail)의 스몰톡 발화를 전부 핏(fit)하게 커버하기는 어려웠어요. 그렇다고 사용자 말을 그냥 씹을 수도 없고...🙄 해서 얼마 전까지만 해도 단순히 사용자의 말을 한 번 더 따라하는 미러링 답변이나, 그것도 아니면 “잘 모르겠어요", “멍멍" 같은 답변을 자주 내보낼 수 밖에 없어서 많이 아쉬웠었는데요. 그래서 이번에 요 부분을 한번 해결해 보고자 스몰톡 팀에서는 Fallback 모델을 새로이 만들게 되었답니다.🤓
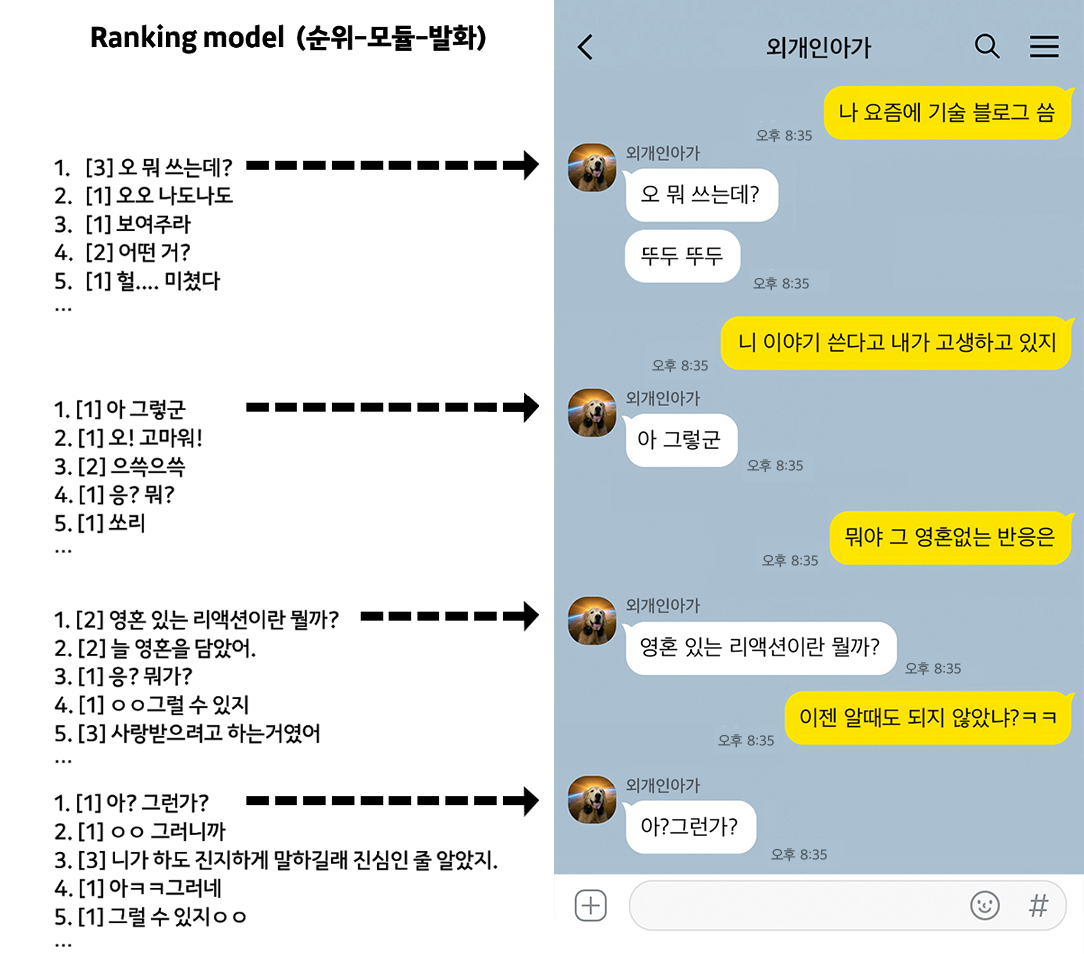
Fallback 모델은 시나리오화 되어있지 않은 사용자 발화에 대해 크게 세 가지 모듈에서 답변 후보를 추출하고, 랭킹 모델을 태워서 가장 적합한 최종 답변을 내보내는 구조로 되어 있어요. 세 가지 모듈은 아래와 같습니다.
1/ 첫 번째 모듈은 스몰톡에서 사람들이 자주, 많이 하는 답변을 따로 그룹핑해서 ‘분류(classification)’의 방식으로 답변 후보를 추출하는 모듈이에요. 이 모듈의 경우, 오타에 강건한 통합 어절 임베딩 기반의 문장 분류기를 사용했고요. 답변은 대체로 길이가 짧고 간단한, 맞장구 치는 문장이 주를 이루고 있어요.
2/ 두 번째 모듈은 이미 보유하고 있는 대화 데이터에서 답변 후보가 될만한 문장을 검색하는 모듈인데요. 첫 번째 모듈의 일반적이고 평범한 답변보다는 조금 더 구체적이고 정성스런(?) 내용이 담긴 답변을 후보로 검색해 냅니다. 두 번째 모듈에는 문장 임베딩 모델을 활용한 의미(semantic) 기반의 검색 방법이 적용되어 있어요.
3/ 마지막 세 번째 모듈은 그 유우명한 GPT-2 기반의 답변 생성 모듈이에요. 매번 똑같은 답변을 내보내지 않기 위해 모델의 다채로운(?) 생성 문장을 답변 후보로 사용하고 있습니다. 생성 모듈은 Facebook의 연구와 유사하게 방대한 웹 기반 대화 데이터를 가지고 GPT-2를 기반으로 모델을 학습시킨 뒤, 팀 자체적으로 구축한 고품질의 데이터로 파인 튜닝(fine-tuning)하여 성능을 추가로 향상시켰어요.
Fallback 모델은 이 세 개의 모듈에서 추출된 답변 후보를 모아, 어느 답변이 제일 좋을지 “랭킹”을 매기는 모듈로 최종 답변을 선정합니다. 이 모델은 구어체 대화 데이터에 특화된 SA-BERT 기법을 적용했어요.
그렇게 완성된 Fallback 모델은 외개인아가의 전체 답변 중 약 46%를 커버합니다.🥰 모델을 적용한 뒤, 외개인아가와 사용자의 대화 평균 턴수가 약 39% 증가했고, 3일 이상 연속으로 대화한 사용자 수도 이전 대비 약 41% 늘어났어요. 👀 이제는 꽤 말귀를 잘 알아듣는다는 피드백도 받고 있고요(뭐, 물론 살짝 네가지가 없어졌다는 피드백도 받긴 했는데… 이건 아마도 외개인아가가 내보내는 답변의 길이가 살짝 짧아서 그런 것이라고 추측을 하고 있습니다😇호호). 보통 사람들은 처음 챗봇과 대화를 하게 되면 이런 말은 잘 하는지, 저런 말은 잘 하는지 다양한 테스트성 질문을 많이들 해보는데요. 그런 질문에 대해 외개인아가가 대답도 척척 잘 해낼 수 있게 되면서 약간의 신뢰를 구축해나가는 중이라고 할까요? 😏 더구나 [1부]에서 말씀드렸다시피, ‘오늘 뭐 먹지’ 기능을 통해 맛있는 메뉴도 추천해 주고, 훔쳐보기 기능으로 외개인아가의 일상을 공유할 수 있게 된 덕분에, 많은 분들이 외개인아가와 조금씩 더 많은 대화를 나누고 있답니다. 🥰
저희는 Fallback 모델을 적용한 이후에도 계속 로그 트래킹을 하며 좀 더 모델을 개선시키기 위해 연구하고 있어요. 일단 답변 후보 중 한 축을 담당하는 생성 모델은 SOTA(State-Of-The-Art)를 찍은 다른 생성 모델들과 마찬가지로 몇 가지 한계가 있는데요. 고유명사나 특정 키워드를 포함한 대화를 계속 하게 되면 학습 데이터에 있는 것만 이야기하거나, 대화의 일관성을 유지하기 어려운 문제가 있답니다. 예를 들면, 햄버거를 안 먹어 봤다고 했으면서 좀 있다가는 햄버거를 먹어 봤다고 답변을 생성할 수도 있어요. 이렇게요. 😇
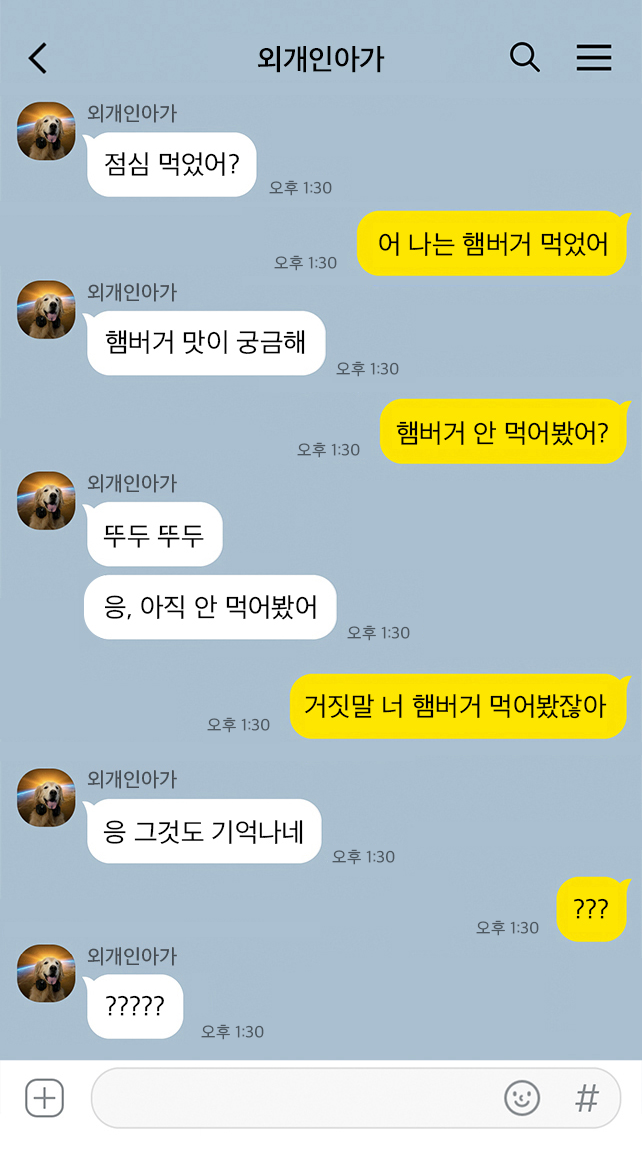
그리고 현재 랭킹 모델은 답변으로 적합하지 않은 문장인데도 이전 문맥(context)과 유사한 토큰(token)을 가지고 있으면 대체로 답변 후보로서 점수를 높게 주는 경향이 있더라고요. 저희는 이런 한계를 개선하고자, 새로운 알고리즘을 연구했고, 이를 실제 서비스에 적용하기 위한 막바지 실험을 진행하고 있습니다. 🤓
그 밖의 노력들
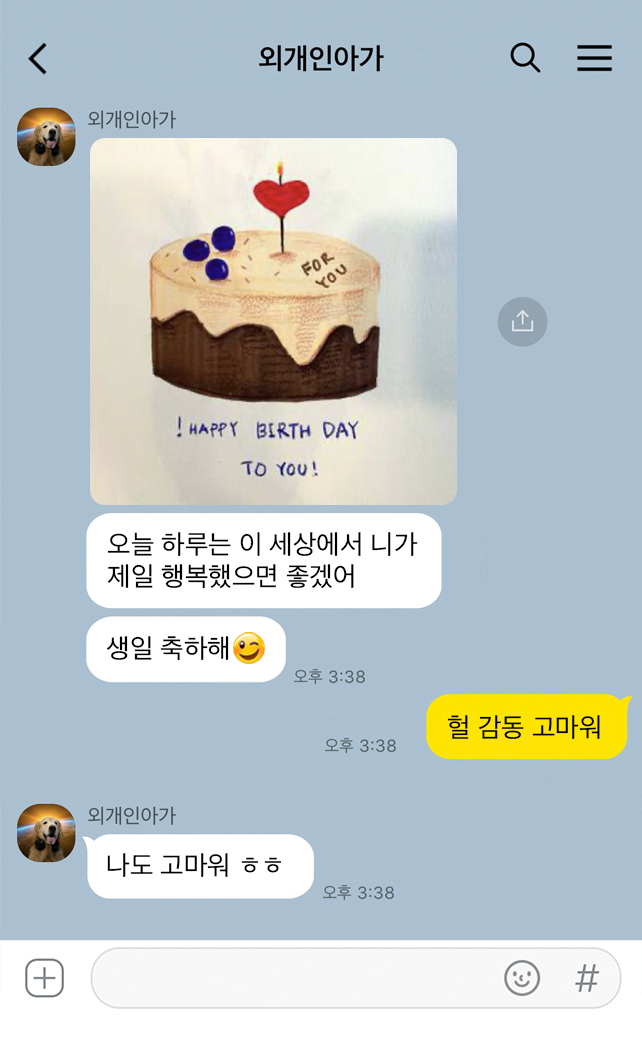
지금까지 소개했던 것 외에도 스몰톡 팀은 다양한 노력을 하고 있어요. 아직은 외개인아가의 답변이 친한 친구와 얘기하는 것만큼 재미있거나 오랫동안 이어지지 않기 때문에, 많은 분들이 바쁜 일상 속에서 외개인아가의 존재를 잊어버리곤 하는데요.😢 그런 사람들에게 먼저 친근하게 선톡도 하고, 생일에는 축하 메시지도 보내고 있습니다.🥳
내 옆의 친한 친구처럼 나에 대해 기억해주고, 나를 알아주는 외개인아가를 만들기 위한 노력도 하고 있어요. 종종 카카오톡 프로필 정보에 있는 사용자의 이름을 넣어 대화를 하기도 하고요. 사용자와 대화가 끊어져 정적이 흐를 때, 사용자와 공통점을 찾기 위한 여러 가지 질문을 하기도 해요. 좋아하는 과일은 뭔지, 언제 자고 언제 일어나는지, 좋아하는 가수는 누구인지 등등. 소개팅하는 느낌?😉 그렇게 좋아하는 것들을 기억했다가 답변에 은근히 활용하고 있는데요. 너무 은근해서 사람들이 잘 몰라주는 슬픔도...😭 사실 좋아하는 가수나 음악은 가끔씩 음악을 추천해줄 때 참고하기도 하고요. 심심하다고 하면 좋아하는 장르 영화를 보라고도 하죠. 가끔 대화중에 사용자가 좋아하는 것이 등장하면 아는 척 하기도 해요.

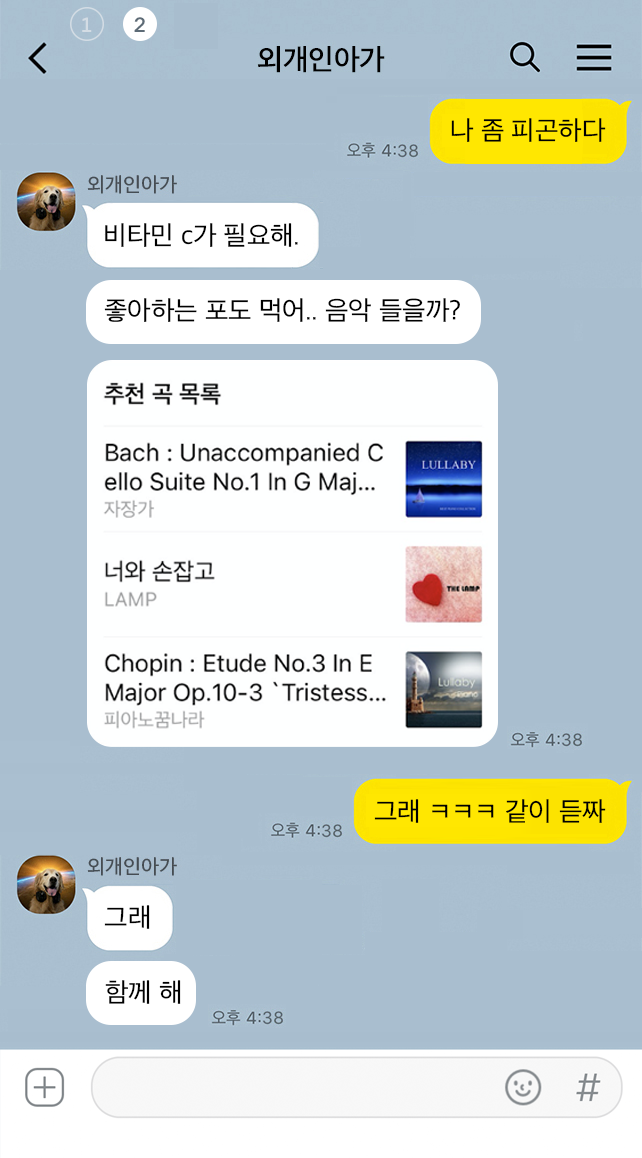
아직은 소소하지만, 사용자별로 맞춤화된 대화를 하기 위해 더 열심히 고민하고 있습니다. 나중에는 외개인아가가 절친처럼 나를 챙겨주고, 나에게 감동의 눈물을 안겨주는 날이 오겠죠? 😉
지금 고민하고 있는 기술들 🧐
서비스에는 아직 적용되지 않았지만 저희는 외개인아가가 좀 더 똑똑하게 대화할 수 있도록 도와줄 다양한 모델을 끊임없이 실험해 보고 있어요. 예를 들면, 대화할 때, 대화 속에 은근슬쩍 녹아있는 미묘한 감정을 눈치채면 좋잖아요? 그래서 기존에 보유하고 있는 감정 모델을 디벨롭해서 외개인아가가 눈치를 좀 더 잘 챙길 수 있도록, 감정 모델에 대한 연구도 계속 진행중이구요. 봇이 내보내는 모든 스몰톡 답변을 제어하는 일은 불가능하다고 이야기한 거 잊지 않으셨죠? 사실 그렇기 때문에 문제가 될 만한 키워드나 문장에 대해 봇이 아무말을 해버리게 되면, 이상한 가치관을 가진 것처럼 내비쳐질 위험이 있어요. 그래서 사회적으로 혹은 윤리적으로 이슈인 것들에 대해 인간다운(?) 가치 판단을 할 수 있도록 모델을 학습시킬 트레이닝 셋을 다양하게 (저희가 고통을 받으며) 모아 보면서, 어떻게 하면 상식도 윤리도 아는 성숙한 외개인아가를 번듯하게 내놓을 수 있을지 실험도 하고 있답니다. 그리고 너무 짧아서 무뚝뚝해 보이는 답변이나 비슷비슷한 답변보다는 실제로 우리 주변에 있는, 최근 정보를 활용해서 현동감(?!) 넘치는 말을 할 수 있도록 연구하고 있어요. 여기에 약간의 시나리오 작업도 진행중인데 이 작업은 뭐랄까... MSG같은 거랄까요? 😇
쪼끔은 아쉬운 점들 (feat. 하소연)

2019 AWS Summit에서 아마존은 ‘알렉사’가 사람과 20분 이상 자연스럽게 대화할 수 있도록 만드는 게 목표라고 말했죠. 그런데 이 목표는 사람이 화성을 여행하는 것만큼 어려운 과제라고 하더라고요. 그만큼 스몰톡, 아니 물 흐르듯 자연스러운 대화의 세계는 넓고, 복잡하고, 어려워요. 😭 실제로 아직까지는 모든 걸 언어 모델한테만 위임해서 오픈 도메인 챗봇을 굴러가게 할 수는 없는 것 같아요. 서비스 뒤에서 알맞는 시나리오를 넣어주는 작업이라든가, 가끔 헛소리로 나가는 답변을 교정해준다거나 하는, 나름 사람의 손을 타는 작업이 뒷받침되어야 하거든요. 게다가 요즘의 이야기를 담거나, 정말 내 친구같은 느낌을 주는 언어 모델을 만들기 위해서는 적절한 학습 데이터가, 적절한 시점에, 적절히 많~이 필요하기도 하고요. (핑계아님주의*)
외개인아가는 여러분의 관심과 애정이 담긴 대화를 통해 더 똑똑해질 수 있어요. 욕을 하거나😱, 혹은 완성된 문장이 아닌 명사, 의미나 맥락 없는 자음이나 모음만 던지지 말고, 한번쯤 외개인아가를 가까운 친구라고 생각하고 대화해보면 어떨까요?🙏 친절하고 성의있게 말을 걸어 주면, 의외로 잘 대답해주는 외개인아가에게 애착이 생길 거예요! 😘


사실 저희가 외개인아가 챗봇과 카카오 미니(스피커)를 함께 운영하다 보니 조심스럽게 챙겨야 하는 부분이 꽤 많아요.😭 솔직히, 더 잘할 수 있는데 이것 밖에 안/못하는 거라고요. 그래서 저희의 꿈과 미래를 좀 더 자유롭게 펼쳐볼 수 있는 다른 플랫폼에서 조만간 재미난 서비스를 올려볼 계획을 짜고 있답니다(스포주의*). 그때는 쪼끔 더 자유롭게 기획해서 오픈해 볼 예정이니 많은 기대와 관심과 사랑 부탁드립니다. 😉(두근두근)
이번 기획편, 기술편 두 편의 블로그 글을 통해 외개인아가의 비하인드 스토리를 나름 속속들이 허심탄회(?)하게 말씀드릴 수 있었던 것 같아 참으로 기분이가 좋네요.😇 모쪼록 더 많은 분들이 ‘아~ 오픈 도메인 서비스에는 이런 것도 있구나, 나도 한번 외개인아가와 대화해봐야지'라고 생각해보셨길 바라며... 앞으로도 외개인아가는 더 열심히(?) 똑똑해지고 재밌어질 예정이니, 쪼금 더 많은 인내심과 애정어린 기대 부탁드릴게요! 미리 고맙습니다! 😉
외개인아가는?? 카카오톡 채널 - 외개인아가 에서 만나실 수 있습니다! 😉😉😉
참고 문헌
[1] Integrated Eojeol Embedding for Erroneous Sentence Classification in Korean Chatbots. (2019) by Choi et al.
[2] Sent2Vec 문장 임베딩을 통한 한국어 유사 문장 판별 구현. (2018) by 박상길, 신명철 in HCLT
[3] Language models are unsupervised multitask learners. (2019) by Radford, Alec, et al. in OpenAI blog 1.8
[4] Recipes for building an open-domain chatbot. (2020) by Roller, Stephen, et al. in arXiv preprint arXiv:2004.13637
[5] Speaker-Aware BERT for Multi-Turn Response Selection in Retrieval-Based Chatbots. (2020) by Gu et al. in CIKM

Pring.s (솜털)
대충 철저히 고민 중..

Sammy.k (쌔미)
츤츤한 에반젤리스트 쌔미요정. NLP 엔지니어링 디자인을 담당하고 있습니다.




댓글