



시작하며
사전학습(pretraining)은 데이터양이 절대적으로 적은 상황에서 적용하는 기법입니다. 문제(본 훈련)에서 제시되는 것과 유사한 형태의 데이터로 모델을 사전학습시키면 본 훈련에 효과적인 매개변수(parameter) 초기값 확보에 크게 도움이 되어서죠. 오늘날 대규모 말뭉치(corpus)를 사전학습한 언어 모델(language model)1이 자연어처리(NLP)에서 주류로 자리2하게 된 것은 바로 이런 효과 덕분입니다.
하지만 대용량 데이터를 사전학습해 성능을 크게 끌어올린 최신 언어 모델이 모든 NLP 태스크를 잘 풀지는 못합니다. 단적인 예로, 하나의 언어로 구성된 문장에서 특징(feature)을 추출하는 데 주안을 둔 언어 모델은 여러 언어에서의 특징 추출이 중요한 번역 태스크에는 적합하지 않죠. 따라서 태스크에 적합한 구조의 언어 모델과 사전학습에 필요한 다량의 말뭉치를 선택하는 여러 기준이 필요합니다.
이에 카카오엔터프라이즈 AI Lab(이하 AI Lab)이 대규모 말뭉치를 이용해 영어를 한국어로 번역하는 모델 개발 과정을 공유하고자 합니다. 실제로 이 기법은 기존 카카오 i 번역 엔진에 사용된 모델과 비교했을 때 더 나은 성능을 냈습니다. AI Lab AI기술팀 컨텍스트파트의 양기창 개발자를 만나 자세한 이야기를 들어봤습니다.
※양기창 개발자는 지난 2019년 7월 카카오의 인턴십 프로그램을 통해 이 연구를 진행했습니다.
※본문에서는 AI Lab이 제안한 모델과 여타 다른 기본 언어 모델(vanilla language model)과의 혼동을 줄이고자, 카카오 i 번역 엔진에 사용된 transformer 구조에 기반한 모델을 '기존 모델'이라고 지칭했습니다.
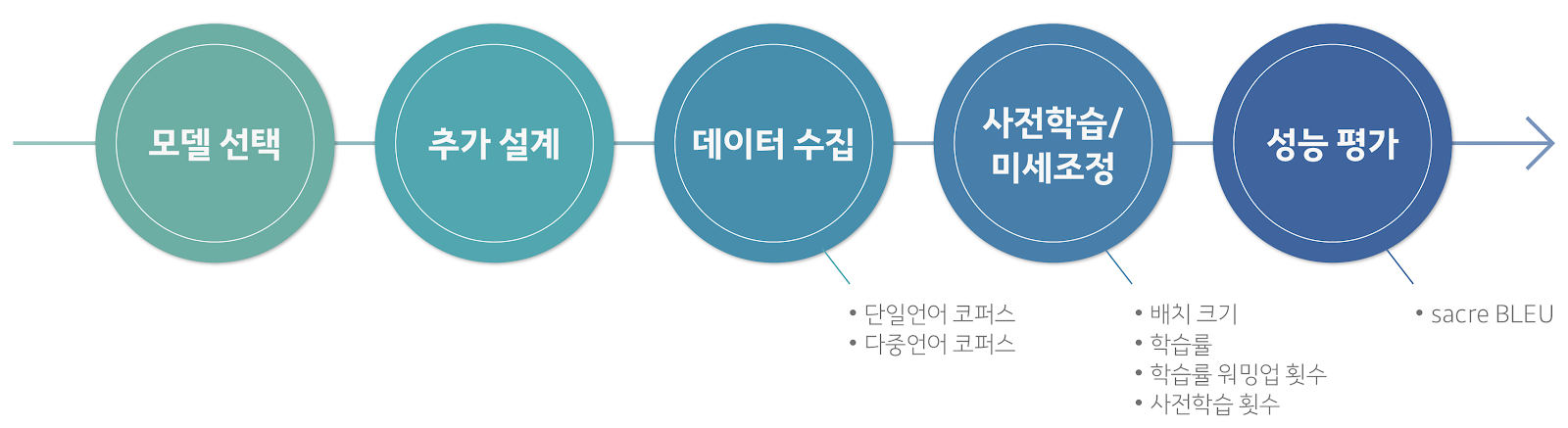
1. 사전학습 모델 선택하기
| 발표 날짜 | 언어 모델 | 발표 기관 |
| 2018년 10월 | BERT | 구글(Google) |
| 2019년 1월 | XLM | FAIR(Facebook AI Research) |
| 2019년 2월 | GPT-2 | 오픈AI(OpenAI) |
| 2019년 5월 | MASS | 마이크로소프트 리서치(Microsoft Research) |
| 2020년 1월 | mBART | FAIR |
AI Lab은 전 세계 많은 연구자가 기준으로 삼는 대표적인 언어 모델인 BERT3와 XLM4, GPT-25, MASS6, mBART7를 다음과 같은 기준으로 평가했습니다.
첫번째, 사용하는 문자(character)가 전혀 다르거나 어족(language family)8이 다른 언어간 번역 성능이 좋아야 합니다. 학계에 보고되는 번역 모델이 수행한 태스크는 대부분 인도유럽어족9에 해당하는 언어 간 번역입니다. 하나의 어파에 해당되는 언어는 비슷한 언어적 특성을 갖추고 있기에 번역이 상대적으로 더 수월합니다. 인도유럽어족의 하나인 영어와 독일어 예문을 보실까요? [그림 2]을 보면 문장을 구성하는 방식이나 사용되는 문자가 서로 비슷하다는 점을 볼 수 있습니다. 반면, 독자적인 문자인 한글을 사용하는 한국어의 경우 일본어나 몽골어를 제외하고는 어족이 같은 언어가 거의 없습니다. 이런 이유로 주 사용자층이 한국인인 카카오 i 번역 엔진에서는 한국어에서 다른 이질적인 언어, 다른 언어에서 한국어로의 번역에 높은 가중치를 둬야 한다고 판단했습니다.

두번째, transformer10 모델 구조를 최대한 유지해야 합니다. transformer에 기반한 기존 모델과 그 구조가 비슷해야 성능을 보다 객관적으로 비교해볼 수 있다고 판단했습니다. 번역 모델의 배포와 서비스 적용 등을 고려했을 때, 코드 재사용성과 효율성 면에서 유리하다는 점도 이런 판단에 영향을 미쳤습니다.
세번째, 문장 단위 번역에 적합해야 합니다. 번역 모델은 입력되는 데이터의 단위인 문장 또는 문서에 각각 최적화돼 있습니다. 달리 말하면, 문장 단위 번역에 집중한 모델에 문서 단위 데이터를 입력하면 자연스러운 번역 결과를 얻지 못합니다. 문장 단위를 주로 입력하는 카카오 i 번역 엔진의 이용자 주 패턴에 맞춰 기존 모델은 문장 단위 번역에 최적화돼 있습니다. 이런 이유로 연구팀이 채택할 모델 또한 문서단위 번역보다는 문장 단위 번역에 적합한지를 살펴봤습니다.
GPT-2로는 다국어 학습을 시도한 연구가 거의 없었을 뿐만 아니라, 기존 모델과 구조가 달라 이를 서비스에 적용하기가 쉽지 않았습니다. 여러 언어를 한 모델로 훈련할 수가 없는 BERT 또한 번역 태스크에는 적합하지 않았습니다. BERT의 다국어 버전인 XLM은 인코더(encoder)11만 사용했습니다. 디코더(decoder)12 구조까지 갖춘 기존 모델과는 구조가 상이한 XLM으로는 직접적인 성능 비교가 어려웠습니다. 가장 최근에 나온 문서 단위 번역모델인 mBART으로는 문장 단위 번역을 제공하는 우리 서비스에 적절하지 않았습니다. MASS는 transformer의 인코더와 디코더에 기반한 모델로, 문장 단위 번역 태스크에 최적화돼 있습니다. 아울러 영어→중국어처럼 이질적인 언어 번역 태스크에서 좋은 성능을 냈습니다13. AI Lab은 MASS가 위 세 가지 기준을 만족하는 가장 합리적인 모델이라 최종 판단했습니다.
2. 실험 설계 추가하기
논문에서 설명한 모델과 실제 공식 구현체 간의 구현방식에 두 가지 차이가 있었습니다. 논문에서는 단일언어 말뭉치로만 사전학습을 진행하는 반면, 마이크로소프트 리서치가 이를 실제 개발한 공식 구현체14에서는 [그림 3]처럼 두 언어 간 병렬 말뭉치를 이용한 사전학습도 함께 진행했습니다. 언어 정보를 나타내는 임베딩(language embedding)을 둔 일체형 인코더와 디코더 구조를 제안한 논문과는 달리, MASS 공식 구현체에서는 언어별로 인코더와 디코더를 두었습니다. 이에 AI Lab은 MASS 공식 구현체에서처럼 단일언어 말뭉치와 다중언어 말뭉치를 모두 활용해 사전학습을 진행했습니다. 아울러 언어별 인코더와 디코더를 만들어 실험을 진행키로 결정했습니다.
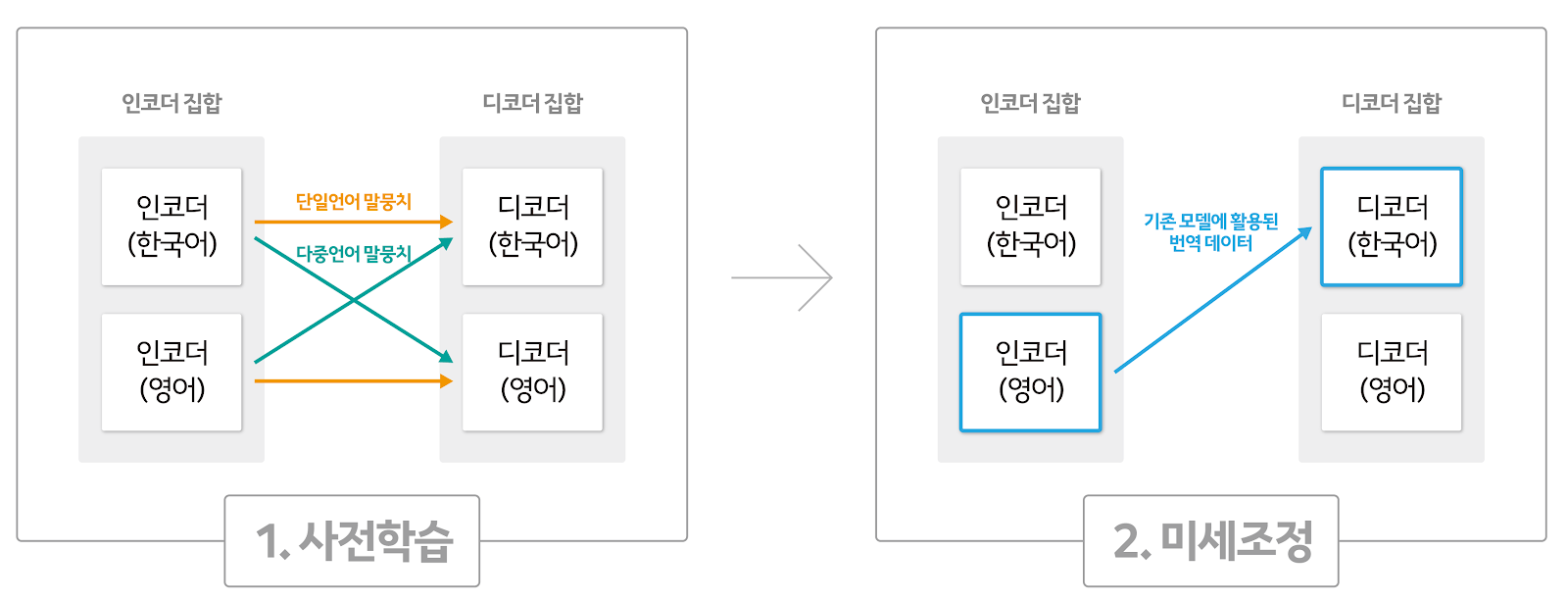
3. 데이터 수집하기
AI Lab은 기존 보유한 <영어 문장, 한국어 문장>으로 구성된 다중언어 말뭉치 외에도, 한국어 또는 영어 문장으로만 구성된 단일언어 말뭉치를 추가로 수집했습니다. 오픈소스 형태로 공개된 데이터셋과 카카오엔터프라이즈가 보유한 ‘백과사전’과 ‘뉴스’, ‘자막’ 데이터셋을 합쳐 기존 모델에 사용된 훈련 데이터셋보다 4배가량 더 큰 규모의 단일언어 말뭉치를 구축했습니다.
‘백과사전’ 예문에서는 여러 분야에 걸쳐 일반적인 지식을 습득하기가 수월합니다. 다만 위키피디아 한국어 예문은 영어에 비해 상대적으로 그 수가 적습니다. 이 숫자의 균형을 맞추고자 AI Lab은 카카오엔터프라이즈가 보유한 백과사전 예문도 추가했습니다. ‘뉴스’는 우리가 실생활에서 접하는 용어와 지식을 획득하기가 좋아 큰 비중을 두고 수집했습니다. ‘자막’에서는 구어체 표현과 관용구 등을 배우기가 좋습니다. AI Lab은 카카오엔터프라이즈가 보유한 것 중 번역 태스크에 사용되지 않은 데이터만 활용했습니다.
| 사전학습 데이터 | 외부 | 내부 |
| 백과사전 | 위키피디아 | 카카오엔터프라이즈 내부 데이터 |
| 뉴스 | WMT-News 크롤 데이터셋15 | |
| 자막 | - |
4. 사전학습 후 미세조정(fine tuning)하기
mBART 논문16에 따르면, 사전학습 횟수가 높을수록 성능이 좋습니다. 하지만 실제 실험에서는 사전학습 횟수가 250,000회를 넘어가면서부터는 높은 성능을 기대할 수 없었습니다. 미세조정 횟수 대비 사전학습 횟수의 비율(사전학습 횟수/미세조정 횟수)로 비교해본 결과, 100%에서부터 성능 향상이 일어남을 확인하였습니다. 이 결과를 토대로 AI Lab은 자체 수집한 데이터를 가지고 160,000회의 사전학습을 진행했습니다.
이렇게 사전학습이 완료된 모델은 번역 태스크에 맞게 훈련됩니다(미세조정). 사전학습 단계에서 배운 내용을 잊어버리거나, 최악의 경우 사전학습을 하지 않은 모델보다 훨씬 낮은 번역 성능을 낼 수 있기에, 적절한 초매개변수(hyperparameter)17 탐색이 이 단계의 핵심입니다. AI Lab은 훈련 데이터 규모를 1/20로 축소해 항목별 실험을 빠르게 진행했습니다.
(1) 배치 크기(batch size)
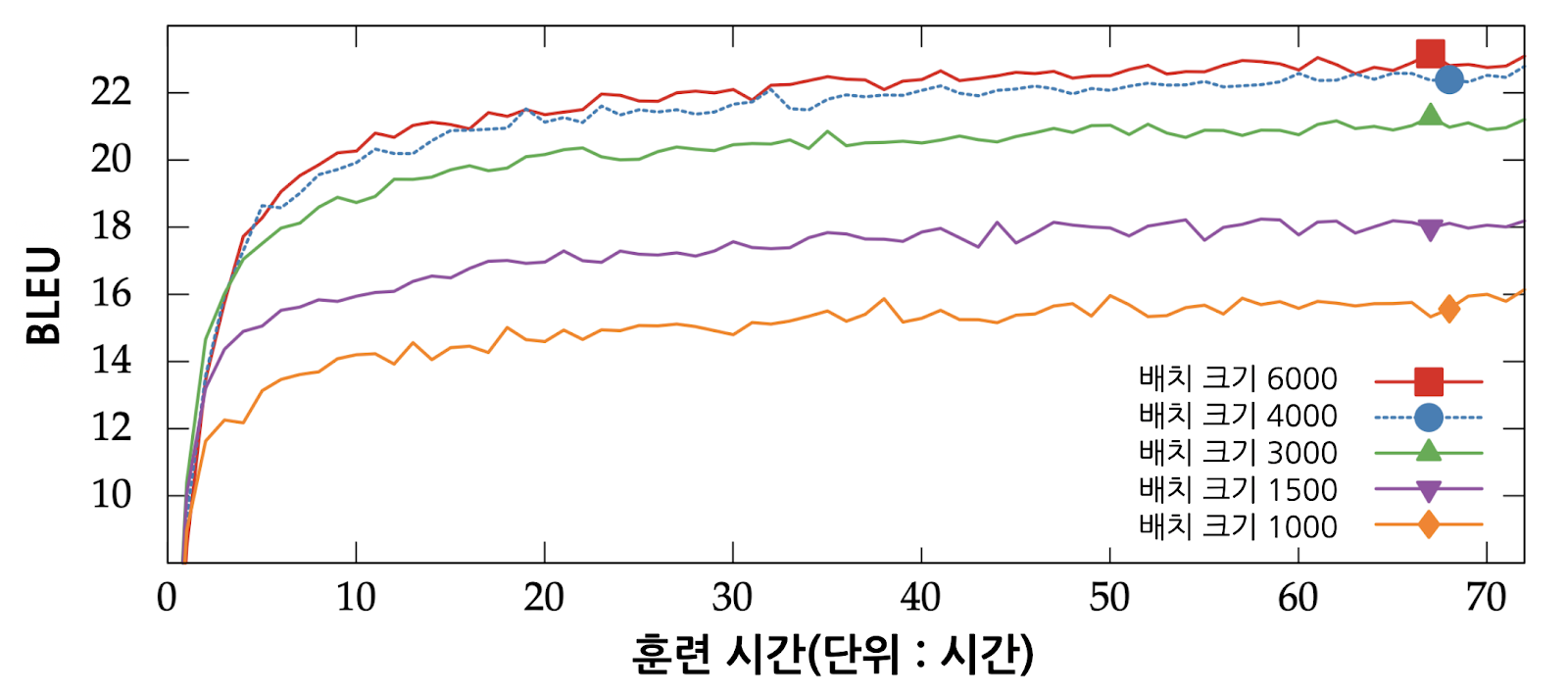
프라하 카렐 대학교 (Charles University in Prague)의 연구에 따르면, 배치 크기가 클수록 언어 모델의 번역 성능이 좋습니다([그림 4]). 하지만 실제 실험에서는 사전학습에 적용된 큰 배치 크기를 그대로 사용하면 미세조정 초반에 손실(loss)이 폭발합니다. 배치 크기가 지나치게 큰 상황에서는 모델 최적화(optimization)18와 일반화(generalization)19가 어렵기 때문입니다.
이런 이유로 AI Lab은 미세조정에 적절한 배치 크기를 선택하는 실험을 진행했습니다([그림 5]). 사전학습 때 사용한 배치 크기의 1배(빨간색)에서는 그래프가 0으로 수렴하지 않고 되려 폭증했습니다. 배치 크기가 지나치게 크다고 판단한 AI Lab은 이를 줄여가면서 모델의 성능이 가장 좋은 지점을 탐색하는 데 집중했습니다. 그 결과, 사전학습 때 사용한 배치 크기의 2/3 배(파란색)20에서 가장 좋은 성능을 확인할 수 있었습니다. 양기창 개발자는 “배치 크기를 1/2배(분홍색)로도 실험을 진행했으나, 2/3배에서보다 미세하게 성능이 낮다는 사실을 확인할 수 있었다”고 설명했습니다.

(2) 학습률(learning rate)
학습률은 학습 한 번에 가중치를 얼마나 갱신할지를 정하는 매개변수입니다. 적절한 학습률 탐색은 딥러닝 모델 훈련에서 중요합니다. 학습률이 지나치게 낮으면 최종 성능에 이르는 데 걸리는 학습 시간이 굉장히 오래 걸릴 뿐만 아니라 최소값(global minimum)21이 아닌 극소값(local minimum)22에 빠지는 문제가 발생합니다. 반면, 학습률이 지나치게 높으면 입력층으로 갈수록 전파되는 오차가 되려 폭증하는 현상으로 인해 최소값을 지나칠 수 있습니다.
앞 사례처럼 학습 초반에 손실이 올라가는 현상을 방지하고자 AI Lab은 배치 크기에 따른 적절한 학습률을 찾는 실험도 진행했습니다. 그 결과, 사전학습에서의 학습률 대비 1/2배(하늘색)와 1배(파란색) 간 뚜렷한 성능 차이가 없었습니다([그림 6]). 이에 AI Lab은 학습률을 0.2 그대로 유지했습니다.

(3) 학습률 워밍업 횟수(warmup steps)
워밍업은 학습 초반에는 학습에 큰 영향을 주지 않을 정도로 작은 학습률을 사용하고, 그 이후에는 기울기 방향을 신뢰할 수준에 이를 때까지 학습률을 서서히 키우는 방식을 가리킵니다. 실제로 페이스북(Facebook)23은 (큰 배치를 이용한) 학습 초반에는 학습에 일정한 영향을 주지 않을 정도로 작은 학습률을 사용하고 이를 서서히 키웠습니다. 학습에 일정한 영향을 미치는 수준에 이른 이후에는 배치 크기를 키운 만큼 학습률을 키웠습니다. 그 결과, 큰 배치 크기에서도 모델의 일반화 성능을 유지하는 데 성공했습니다.
AI Lab 또한 이와 비슷하게 사전학습 설정값대로 학습률을 0에서 0.2까지 8,000회에 나눠서 천천히 키웠습니다. 하지만 미세조정 초반에 손실이 올라가는 현상이 발생했습니다. 워밍업 횟수가 작아서 생긴 현상이라고 본 AI Lab은 워밍업 횟수를 2배로 늘려 학습률을 천천히 예열하면 성능 개선이 이뤄질 거라 가정했습니다. 그러나 학습률 워밍업 횟수가 8,000회(하늘색)일 때와 16,000회(초록색)에서의 오차는 큰 차이가 없었습니다([그림 7]). AI Lab은 사전학습 때처럼 학습률 워밍업 횟수를 8,000회로 설정했습니다.

5. 성능 평가하기
일반적으로 번역 모델의 성능 평가 척도로는 주로 BLEU(bilingual evaluation understudy)24를 활용합니다. IBM에서 개발한 BLEU는 기계가 번역한 문장(source)과 인간이 실제로 번역한 정답 문장(reference) 간의 정확도를 측정합니다. 숫자가 클수록 번역된 문장과 정답 문장과의 유사성이 높습니다. 물론 BLEU가 높더라도 사람의 번역 품질보다 훨씬 떨어질 수는 있습니다. 그럼에도 언어에 구애받지 않고 계산 속도가 빠르며 객관적인 평가법이라는 점에서 그 공신력을 인정받고 있습니다.
하지만 AI Lab은 BLEU로 기존 모델과 자체 개발한 모델의 성능을 직접 비교하기에는 무리가 있다고 판단했습니다. BLEU에서는 기계가 번역한 문장이 ‘나는 케빈입니다’로 동일하더라도, '나/는/ /케빈/ /입니/다' 또는 '나는/ /케빈 입니다'처럼 문장을 분절하는 단위가 달라지면 점수 산정 방식이 달라집니다. 서로 다른 번역 모델이 동일한 토크나이저를 이용하더라도 토크나이저 훈련에 사용한 말뭉치 종류가 다르면 분절 단위가 바뀌기 때문입니다.
차선책으로 고려한 성능 평가 척도는 아마존웹서비스(AWS)가 지난 2018년 ACL 학회에 제출한 논문25에서 처음 제안한 sacre BLEU([그림 8])입니다. 논문에서는 통계적으로 추출한 서브워드(subword)26 기반으로 문장을 분절하는 최신 알고리즘인 BPE(Byte-Pair Encoding)를 사용합니다. 이렇게 하면 번역 모델과 모델 학습에 사용한 말뭉치 종류에 관계없이 기계가 번역한 문장을 동일한 단위로 분절할 수 있습니다. 보다 객관적인 척도라는 점을 인정 받은 sacre BLEU는 최근 여러 논문에서 BLEU에 함께 번역 모델의 성능을 평가하는 기준으로 널리 사용되고 있습니다.

sacre BLEU를 평가 척도로 내세워 영어→한국어 번역 태스크에서 기존 모델과 AI Lab이 개발한 모델의 성능을 비교해본 결과([표 3]), 단일언어 말뭉치와 다중언어 말뭉치 모두를 사전학습 번역 모델이 기존 모델보다 약 5%P 더 나은 성능을 냄을 확인할 수 있었습니다. 반면, 단일언어 말뭉치 또는 다중언어 말뭉치만을 사용하면 되려 모델의 성능이 저하됐습니다. 이에 대해 양기창 개발자는 “사전학습에 사용한 말뭉치가 미세조정 단계에서 유의미한 영향을 미칠수록, 그리고 잡음(noise)를 상쇄할만한 방대한 데이터를 모을수록 모델의 성능 향상에 영향을 미침을 알 수 있었다”고 분석했습니다.
| 모델 | 사전학습에 사용한 말뭉치 종류 | sacre BLEU |
| 기존 모델 | X | 0 |
| AI Lab이 제안한 모델 | 단일언어 말뭉치((한국어), (영어)) | -1.358 |
| 다중언어 말뭉치((영어, 한국어)), Masked LM27 | -5.30 | |
| 단일언어 말뭉치 + 다중언어 말뭉치, Masked LM | +1.481 |
향후 계획
AI Lab은 정량적인 평가 이외에도 전문 번역가를 통해 모델을 정성적으로 평가하는 등 적절한 평가 방법론을 마련하는 추가 연구를 준비하고 있습니다. 영어→한국어 번역 태스크 외에도, 카카오의 주 사용자층인 한국인을 위해 한국어→영어, 한국어→중국어, 한국어→일본어 번역을 포함해 다양한 언어 간 번역 태스크에도 사전학습을 적용하는 실험을 진행할 계획입니다.

이수경(samantha) | 작성, 편집
지난 2016년 3월 알파고와 이세돌 9단이 펼치는 세기의 대결을 취재한 것을 계기로 인공지능 세계에 큰 매력을 느꼈습니다. 카카오엔터프라이즈에서 인공지능을 제대로 알고 싶어하는 사람들을 위해 전문가와 함께 읽기 쉬운 콘텐츠를 쓰고 있습니다. 인공지능을 만드는 사람들의 이야기와 인공지능이 바꿀 미래 사회에 대한 글은 누구보다 쉽고, 재미있게 쓰는 사람이 되고자 합니다.

양기창(kevin) | 작성, 감수
카카오엔터프라이즈에서 번역엔진 연구∙개발을 담당하고 있습니다. 군복무 시절부터 딥러닝에 빠져살다, 전역후 복학대신 카카오 입사를 선택했습니다. 모두가 정보 불균형함에서 벗어나 공정한 세상에서 살 수 있도록 도움을 주는 인공지능을 만들어보고자 합니다.

- 언어라는 현상을 모델링하고자 특정 단어 시퀀스(또는 문장)에 확률을 할당하는 모델 [본문으로]
- https://openai.com/blog/language-unsupervised/ [본문으로]
- https://arxiv.org/abs/1810.04805 [본문으로]
- https://arxiv.org/abs/1901.07291 [본문으로]
- https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf [본문으로]
- https://arxiv.org/pdf/1905.02450.pdf [본문으로]
- https://arxiv.org/abs/2001.08210 [본문으로]
- 같은 조상언어에서 갈라나온 거라 추정되는 여러 언어를 통틀어 일컫는 말 [본문으로]
- 유럽과 서아시아, 남아시아에 사는 사람이 사용하는 언어가 속하는 어족 [본문으로]
- 컨볼루션(convolution)이나 순환(recurrence) 기법 대신, 모든 단어가 현재 결과에 기여하는 정도를 반영할 수 있도록 각 입력 단어가 출력 상태에 연결하는 어텐션(attention) 신경망 구조를 활용한 seq2seq 모델이다. 어텐션을 이용해 거리가 먼 단어 간의 관계를 효과적으로 표현이 가능한 덕분에 학습 성능이 좋아졌다. [본문으로]
- 입력된 토큰 시퀀스의 언어적 특성을 특징 벡터(feature vector)로 표현하는 부분 [본문으로]
- 특징 벡터를 이용해 새로운 토큰 시퀀스를 생성하는 부분 [본문으로]
- https://paperswithcode.com/task/machine-translation [본문으로]
- https://github.com/microsoft/MASS [본문으로]
- 유명한 인공지능 번역 대회인 WMT(Conference on Machine Translation)가 공개한 뉴스 데이터셋 [본문으로]
- https://arxiv.org/pdf/2001.08210.pdf [본문으로]
- 개발자가 머신러닝 알고리즘에서 직접 조정하는 값. 필터 수나 모델의 층 수, 필터 크기 등이 여기에 해당한다. [본문으로]
- 모든 학습 데이터에 대해 오차를 최소화하는 가중치 값을 찾은 상태 [본문으로]
- 학습 데이터와 조금이라도 다른 성격의 데이터가 입력되어도 모델이 제대로 동작하는 상태 [본문으로]
- 12,288토큰/GPU [본문으로]
- 모든 점이 가지는 함수값 이하의 함수값 [본문으로]
- 주위의 모든 점이 가지는 함수값 이하의 함수값 [본문으로]
- https://arxiv.org/pdf/1706.02677.pdf [본문으로]
- https://www.korean.go.kr/nkview/nklife/2017_4/27_0403.pdf [본문으로]
- https://arxiv.org/abs/1804.08771 [본문으로]
- 단어를 통계적인 관점에서 나눈 가장 작은 단위 [본문으로]
- 단어 시퀀스의 복잡한 관계를 잘 표현할 수 있도록 학습 문장마다 매번 서로 다르게 무작위로 비운 단어를 예측할 수 있도록 하는 기법 [본문으로]




댓글