



시작하며
꾸준한 성능 개선과 기능 추가 등으로 현재는 19개 언어간 번역 서비스를 제공하고 있는 카카오 i 번역 서비스는 2017년 10월, 처음 출시되었습니다. 여기에는 신경망 번역 기술이 적용되었고, 당시 내부 블라인드 테스트에 따르면 '경쟁력이 높다'라는 결과가 나왔습니다. 이처럼 우수한 성능을 위해서는 좋은 모델이 전제되어야 하지만, 학습 데이터 역시 매우 중요하다고 할 수 있습니다. 이 글에서는 카카오 i 번역 서비스가 양질의 대규모 학습 데이터(병렬 말뭉치)를 확보하기 위하여 사용한 기술 중 Ableualign 툴을 소개해 보려고 합니다.
데이터 확보와 BLEU
본론에 앞서 우선 Ableualign 툴의 이름에 포함되어 있는 BLEU가 어떤 의미인지 이해할 필요가 있습니다. 이는 원문에 대한 사람의 번역 결과와 번역기의 결과가 얼마나 유사한지를 수치화하기 위한 알고리즘입니다. 수치화하는 방식은 문장을 구성하는 단어들을 N-gram으로 만들고, 그 N-gram들이 서로 얼마나 매칭되는지를 보는 식으로 구성되며, 보통 3~4-gram까지 진행됩니다.
먼저 N-gram은 문장을 어떤 단위로 분할했을 때 인접한 N 개를 모은 것을 의미합니다. 단위는 여러 가지가 가능한데, 아래 예시를 통해 띄어쓰기를 단위로 한 3-gram을 구해보도록 하겠습니다.
예) 입력: '나는 소년입니다'
3-gram: 'I am a', 'am a boy'
이런 식으로 문장을 쪼개는 이유는 문장 간의 유사도를 측정할 때 문장의 일부로서 매칭을 해보기 위함입니다. 본 글에서는 유사도를 Sliding Window 방식으로 비교하기 위한 것이라 생각해도 무방합니다. 이 방식은 문법 구조, 유의어 등을 보지 않기 때문에 한계를 가지긴 하지만, 더 나은 방법론이 아직 없기 때문에 번역의 품질 평가에도 여전히 많이 사용되고 있습니다.
이쯤에서 '데이터 확보에 왜 BLEU를 쓰는가'라는 의문이 들 수 있을 것입니다. 원문과 대역문을 모아놓은 언어 자료인 병렬 말뭉치(Parallel Corpus)의 Raw Data는 대부분 글(Article) 단위이고, 문장(Sentence) 학습을 하는 신경망 기반 기계번역(Neural Machine Translation, NMT) 모델을 위해서는 문장 단위로 정렬을 해주는 툴이 필수적입니다. 카카오에서는 초기에 정렬(Alignment)을 위하여 규칙 기반 툴을 만들어서 사용했는데 이것에 한계가 있음을 경험했습니다. 왜냐하면 규칙을 프로그래밍 하기가 너무 힘들었고, 도메인 변경 시 기존 규칙이 적합하지 않다는 문제가 발생했기 때문입니다. 이처럼 규칙은 복잡하지만 사람이 하면 쉬운 문제의 경우 해결할 수 있는 적절한 방법이 있는데 바로 딥러닝을 적용하는 것입니다. 결국 저희는 이미 딥러닝을 통해 학습된 번역기를 활용하면 쉽게 정렬을 할 수 있을 것이라는 결론에 도달하였고, Bleualign을 사용하게 되었습니다. 하지만 Bleualign은 N-gram Precision을 계산하는데 있어 한계를 지닙니다. 이에 Bleualign의 개선 버전인 Ableualign을 통해 비교적 간단한 아이디어로 많은 효과를 보았습니다.
Bleualign
Bleualign은 BLEU Score를 이용해서 두 개의 말뭉치들을 정렬하는 툴입니다. 번역기의 학습을 위해서는 병렬 말뭉치가 필요한데, Bleualign에 두 가지 언어로 된 글을 던지면 그 안에서 문장 단위 번역쌍을 뽑아줍니다. 카카오는 번역 모델을 학습시킬 때 이용할 데이터를 만들기 위해 Bleualign을 사용하였습니다. 그럼 이 툴의 동작 방법을 간단히 살펴보도록 하겠습니다.
(1) 다음과 같이 문장 단위로 분리된 한국어와 영어로 된 글이 있다고 가정합니다. 이때 같은 글에 대한 문장들이므로 비슷한 문장들이 많이 존재하며, 무조건 1:1 매칭이 되지는 않습니다.

(2) 이 중 하나를 한영 번역기(또는 영한 번역기)를 통해 번역합니다.

(3) 이제 한국어, 영어, 기계 번역 결과를 동시에 입력값으로 Bleualign에 넣어주면 문장 단위의 병렬 말뭉치가 출력됩니다. 같은 색깔의 박스들은 같은 문장의 다른 언어로 된 표현(Representation)들입니다.

3번 단계에서 기계번역 결과와 영어 말뭉치를 통해 같은 문장을 찾게 되는데, 이때 비슷한 문장을 찾기 위해 BLEU Score를 사용합니다. 사실 저희는 학습 데이터를 얻기 위해 Bleualign 툴을 잘 사용했었지만 BLEU를 개선하면 더 많은 병렬 말뭉치를 얻을 수 있지 않을까 하는 생각이 들었고, 점수 함수(Score Function)를 ABLEU로 대체한 Ableualign 툴을 사용하게 되었습니다.
BLEU란
BLEU는 기계 번역의 품질을 평가하는 측정 기준(Evaluation Metric) 중의 하나입니다. 간단하고 빠른 계산으로 인간이 생각하는 품질과 높은 상관관계(Correlation)를 가지고 있어 현재까지도 가장 널리 쓰이는 측정 기준입니다. BLEU의 입력값(Input)은 '기계 번역 결과'와 '여러 개의 실제 번역 결과'이며, 출력값(Output)은 '0~1 사이의 값'입니다. 여기서 출력값이 1에 가까울수록 번역 결과가 좋은 것을 의미합니다. 본 글에서는 조금 더 쉽게 설명하기 위해 실제 번역 결과가 하나만 존재한다고 가정하도록 하겠습니다.
BLEU의 개요
BLEU를 간략하게 나타내보면 다음과 같습니다.
- 기계 번역 결과(이하 Candidate)와 실제 번역 결과(이하 Reference)에서 1-gram~4-gram에 대한 정확도를 계산합니다.
- 4 개 결과의 기하평균을 내서 Precision을 구합니다.
- 여기에 길이(Length)에 대한 페널티(Brevity Penalty)를 곱해서 BLEU 값을 계산합니다.
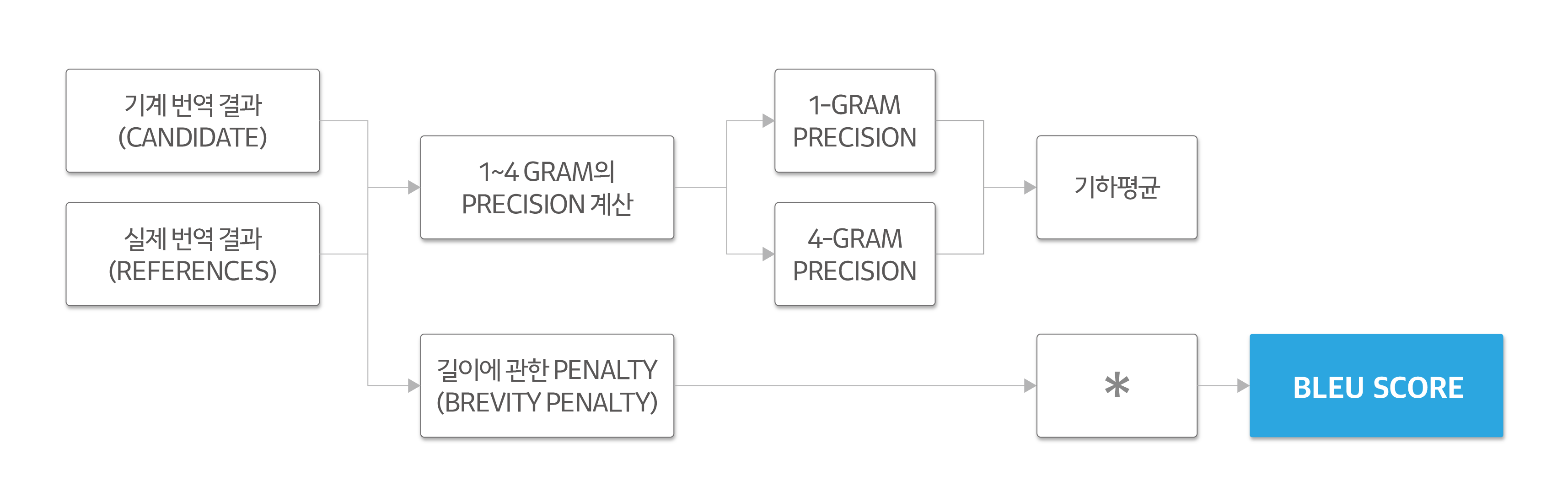
N-gram의 정확도 측정
각 방법에 대해 자세히 알아보도록 하겠습니다. 쉽게 설명하기 위해 예시를 들어서 띄어쓰기를 단위로 한 1-gram의 정확도를 계산하겠습니다. 먼저 Candidate로 '나는 밥을 먹었다'를, Reference로 '나는 밥을 버렸다'가 입력되었다고 가정해 보겠습니다. 여기서 Candidate의 1-gram은 '나는', '밥을', '먹었다'이며, 2-gram은 '나는 밥을'과 '밥을 먹었다'입니다. 1-gram의 정확도(Precision)는 [수식 1](mmax: 단어가 Reference에서 나온 최대 개수 / wt: Candidate의 총 단어 개수)로 구할 수 있습니다.
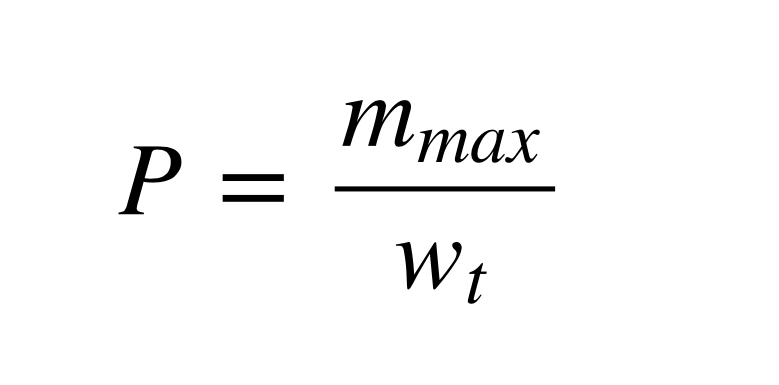
즉 위의 예제에서 각각은 다음과 같은 값을 갖게 되어 1-gram Precision은 2/3가 됩니다. ('나는'의 mmax=⅓, '밥을'의 mmax=⅓, '먹었다'의 mmax=0)
왜 굳이 Reference에서 나온 최대 개수로 Clipping을 하는지에 대해 궁금할 수 있습니다. 이는 번역기 모델이 반복적으로 단어를 뱉어내는 경향이 있는데, 정확도를 계산할 때 반복된 단어들을 전부 넣어버리면 점수가 올라가므로 이를 방지하기 위함입니다. [표 1]은 BLEU: a method for automatic evaluation of machine translation[1]에서 발췌한 예제입니다. [표 1]의 경우 Max 값으로 Clipping 하지 않으면 7/7로 정확도가 1이 됩니다.
| Candidate | the | the | the | the | the | the | the |
| Reference 1 | the | cat | is | on | the | mat | |
| Reference 2 | there | is | a | cat | on | the | mat |
[표 1] Unigram Precision이 잘 나오는 경우
한편 위처럼 정확도를 계산하면 짧은 번역문을 선호한다는 문제가 또 발생합니다. 예를 들어, Candidate로 '나는'이 나왔다고 하면, [수식 2]와 같이 됩니다. 따라서 Candidate와 Reference의 길이를 비교하여 페널티를 주어 보정합니다.
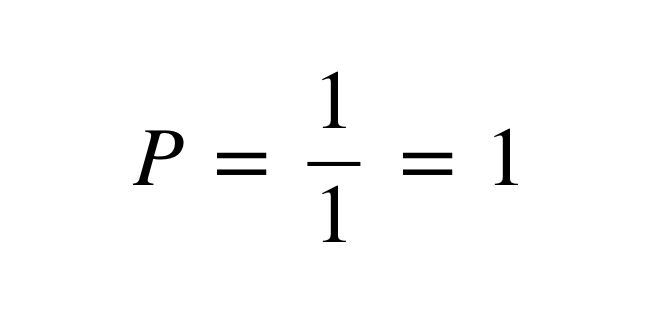
Brevity Penalty
문장의 길이를 이용해 페널티를 줍니다. 다음 [수식 3]을 Precision에 곱해줘서 페널티를 줄 수 있습니다.
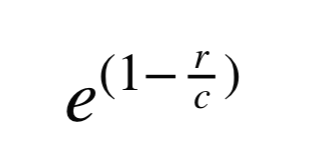
Candidate가 Reference 길이의 절반만 되더라도 정확도가 반 이상으로 떨어지게 됨을 알 수 있습니다.
ABLEU
Idea
우리는 BLEU에서 N-gram Precision을 계산하는데 있어 정확히 매칭되는 것만 카운팅을 하고 있다는 것에 주목했습니다. '이쁘다'와 '예쁘다'는 분명히 비슷한 뜻인데 0, 1로만 구분해서 집계(Discrete Counting) 하기에 매칭이 되지 않는 결과가 발생한 것입니다. 때문에 비슷한 단어에 대해 0과 1사이의 어떤 유사도(Similarity)를 연속적(Continuous)으로 부여할 수 있다면, 이것이 훨씬 더 좋은 결과를 낼 수 있을 것이라 생각했습니다. 유사도를 구할 수 있다고 가정해 볼 때, ABLEU는 BLEU 수식에서 단 한 개만 바꾸면 됩니다.
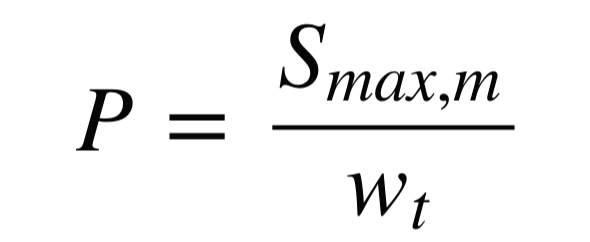
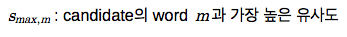
이제 우리가 할 일은 유사도를 계산하는 방법을 만드는 것입니다.
유사도
Word2vec
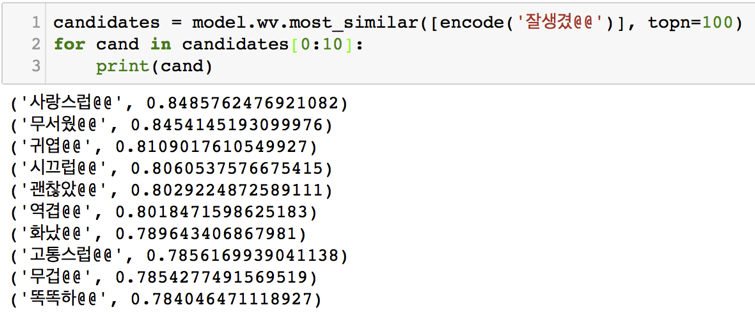
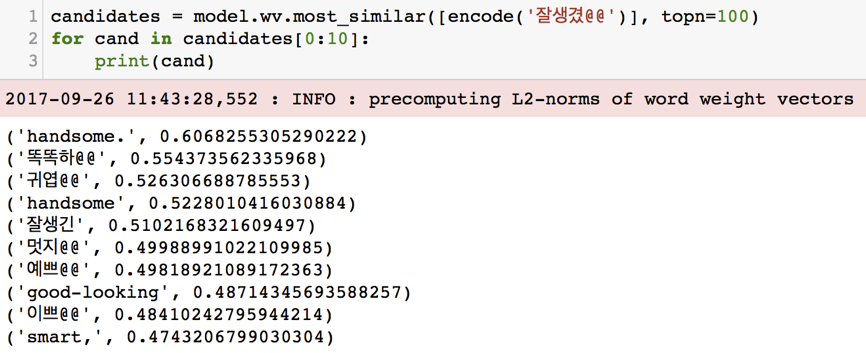
Word2vec은 단어를 고정된 길이의 벡터로 Embedding 하는데 쓰입니다. 따라서 처음에는 Word2vec으로 단어들을 Embedding 하고 그것의 유사도를 쓰면 될 것이라 생각했습니다. 하지만 Word2vec은 단어의 위치에 따른 유사도가 크기 때문에 정반대의 단어도 유사도가 높게 나온다는 단점이 존재합니다. 예를 들어 Word2vec의 경우 '잘생겼'과 가장 비슷한 단어들 10개를 뽑으면 [그림 5]와 같은 결과가 나옵니다. '역겹'과 '잘생겼'이 비슷하게 나온 것을 보면, 문장 내의 위치(Position)가 유사도에 미치는 영향이 큰 것을 알 수 있습니다.
Word2vec-Pair
이를 방지하기 위해 만든 방법은 굉장히 단순할뿐더러 비슷한 단어의 유사도도 잘 뽑아냅니다. 그 방법이란 바로 우리가 가지고 있는 병렬 말뭉치를 섞어서 Word2vec을 학습(Training) 시키는 것입니다. 이는 두 문장을 섞어버리면 영어 단어와 한글 단어가 Word2vec의 입력값으로 같이 들어가며, 비슷한 단어의 유사도를 높이는데 서로를 이용할 것이라는 생각에서 비롯되었습니다. [그림 6]을 보면 Word2vec-Pair의 경우 뜻이 비슷한 단어가 더 잘 뽑히는 것을 알 수 있습니다. 두 언어에 대해서 모델을 학습시키기 때문에 영어 단어도 뽑히게 됩니다.
위의 Word2vec-Pair를 통해 나온 Embedding으로 서로의 유사도를 구했고, 이를 사용하여 ABLEU를 만들 수 있었습니다.
결과
| Bleualign | Ableualign | |
| 수율 (%) | 35.64 | 47.1 |
| 정확도 (%) | 86 | 93.73 |
[표 2] Bleualign과 Ableualign의 수율 및 정확도
실험 결과, 동일한 번역기를 사용할 때 Bleualign 대비 Ableualign의 수율이 35.64%에서 47.10%로 약 11% 증가하였고, 정확도도 86%에서 93.73%로 증가하였습니다(정확도는 샘플링하여 수동 평가로 측정하였습니다). 이 말은 ABLEU 적용으로 기존보다 더 나은 품질의 데이터를 30% 정도 더 추출했다는 의미입니다. 물론 Bleualign의 성능은 번역기의 성능에 의존적이기 때문에 더 나은 번역기를 사용할 경우 수율이 더 높아질 수 있습니다.
따라서 Ableualign을 사용해 번역기의 품질을 올리고, 이를 다시 Ableualign 번역 스텝에 사용하여 수율을 올리는 반복 작업이 가능했습니다. 실험이 진행되는 동안 카카오에서는 번역기 모델 개선이 한 번 더 이루어졌는데, 이 모델을 적용하여 최종적으로는 기존보다 58% 더 많은 병렬 말뭉치를 추출할 수 있었습니다.
마치며
카카오는 과거에 번역기의 학습에 이용할 양질의 병렬 말뭉치를 얻기 위해 Bleualign을 사용하였습니다. 하지만 Bleualign의 점수 측정 기준(Score Metric)을 더 좋게 바꾸면 질 좋은 데이터를 더 많이 얻을 수 있으리라 기대했으며 0, 1로만 구분하여 집계하는 BLEU Score의 Discrete Counting에 주목하였습니다. 또한 이를 연속적인(Continuous) 유사도로 바꾸기 위해 Word2vec을 언어쌍으로 학습하는 방법을 고안하였고 그 결과 Ableualign을 만들 수 있었습니다. 게다가 이를 통해 더 많이 확보된 데이터로 번역기의 품질을 높이고 이 번역기를 다시 Ableualign의 번역 Step에 넣어서 반복(Iteration)을 통해 선순환 구조를 만드는 것이 가능해졌습니다.
최근 카카오엔터프라이즈는 특허, 법률 등 전문 도메인 영역의 번역 성능을 개선하기 위해 데이터를 확보 중인데, 역시나 Ableualign이 큰 도움을 제공하고 있습니다. 사실 해당 도메인뿐만 아니라 앞으로 생성될 대부분의 번역 데이터는 문서 단위로만 생성될 것입니다. 따라서 번역 모델 학습에 필요한 데이터를 문장 단위의 쌍으로 정렬해주는 Ableualign은 꾸준히 중요한 역할을 할 것으로 예상됩니다.
참고 문헌
[1] Papineni, K., Roukos, S., Ward, T., Zhu, W, J., (2002).
,
'02 제40차 전산언어학회 연차총회 논문집
(pp. 311-318).

오형석(hulk)
새로운 도메인, 새로운 접근방법을 좋아합니다.
현재는 OCR TF를 맡아 OCR 도메인 내에서 새로운 먹거리를 찾고 연구중에 있습니다.





댓글