



시작하며
얼굴 인식 기술은 지난 수십년 간 컴퓨터 비전의 주요 연구 분야 중 하나로 자리매김하고 있습니다. 카카오 또한 딥러닝을 이용한 관련 연구개발을 진행하고 있죠. 지난 2016년 말 출시된 '라이브픽'은 자사 얼굴 인식 기술을 사용한 대표적인 예입니다. 이 이미지 검색 서비스([그림 1])는 시사회, 시상식, 사인회, 공항 출입국과 같은 이벤트별로 모은 스타 사진을 시간순으로 보여줍니다.

당시 개발한 모델이 주로 학습한 데이터셋에는 서양인 얼굴이 많이 포함돼 있어 동양인 얼굴을 제대로 인식하지 못하는 문제가 있었습니다. 동양인 얼굴 이미지 수집 및 레이블링, 모델을 개선하면 좋겠다는 논의를 바탕으로 새로운 얼굴 인식 모듈 개발에 성공한 카카오는 이전보다 훨씬 더 정확한 라이브픽 서비스를 제공할 수 있게 됐습니다.
여기서 더 나아가 카카오엔터프라이즈 AI Lab(이하 AI Lab)은 자사가 보유한 얼굴 인식 모델의 객관적인 성능을 측정하면 좋겠다고 판단했습니다. 그 결과, 팀(신종주, 김홍락, 김용현)을 이뤄 참가하게 된 안면인식 공급업체 테스트(Face Recognition Vendor Test, FRVT)1의 경쟁 주제 중 하나인 1:1 검증(verification) 일반 이미지(wild) 부문에서 100여 팀 중 3등(2020년 5월 21일 기준)을 차지하는 성과를 달성했습니다.
이번 글에서는 AI Lab이 도전한 대회를 소개하고, AI Lab만의 문제 해결 방식, 성능 평가 척도 및 향후 연구 계획에 대해 다루고자 합니다. 이를 위해 AI Lab AI기술팀 멀티미디어처리파트의 신종주 연구원을 만나 그 자세한 이야기를 들어봤습니다.
☛ Tech Ground 데모 페이지 바로 가기 : 얼굴 검출 데모
FRVT 1:1 검증 챌린지를 소개합니다
미국국립표준기술연구소(NIST)가 주관하는 FRVT는 얼굴 정보 대조를 통한 출입국심사, 여권 불법 복제 탐지, 아동(미성년자) 성범죄 피해자 식별2처럼 민간∙사법∙국가 보안 영역에서 활용되는 자동화된 얼굴 인식 응용 프로그램의 성능을 측정하는 대회입니다. 대회가 열리는 2~3년의 기간 동안 참가자는 4개월에 한 번씩 새로운 알고리즘을 제출할 수 있습니다. 주최 측은 한 업체가 최근 제출한 2개의 알고리즘의 성능을 평가해 그 결과를 리포트 형태로 발표합니다.
대회 참가자는 검증(1:1 매칭), 식별(1:N 매칭), 모프(morph), 품질(quality) 등 총 4개의 경쟁 주제 중 원하는 분야를 선택해 참가할 수 있습니다. '검증'은 시스템에 입력된 두 이미지 속 인물의 동일인 여부를 판별하는 능력을 측정합니다. '식별'은 시스템에 입력된 얼굴 이미지가 내부 데이터베이스(DB)에 저장된 인물 중 누구와 가장 유사한지를 판단하는 데 활용됩니다. '모프'는 시스템에 입력된 얼굴 이미지를 인식해 그 합성 여부를 제대로 판단하는지를 평가합니다. '품질'에서는 화질, 얼굴 촬영 각도, 조명 등에 따른 입력 영상의 품질을 판별하는 능력을 측정합니다.
이 중에서도 AI Lab이 참가한 1:1 검증에 대해 더 자세히 설명해보겠습니다. 1:1 검증 참가자는 미국 입국자의 비자(visa) 사진과 범인 식별용 상반신(mugshot) 사진, 실생활 환경에서 촬영된 일반 얼굴 사진(wild), 공항 출입국심사대에서 촬영된 사진(visaboarder) 부문에서 주어진 두 얼굴 이미지쌍의 동일인 여부를 판별하는 실력을 겨룹니다([그림 2]). 새롭게 신설된 네번째 부문3에서의 관건은 고품질 영상의 비자 사진과 웹카메라로 촬영한 중저품질 영상 속 인물의 동일인 여부를 판별하는 데 있습니다.

NIST는 참가자로부터 받은 코드를 평가 플랫폼에서 직접 가동하는 방식을 채택했습니다. CPU 싱글스레드4를 이용한 C++ 추론 모델로 영상 하나당 1초 안에 정답(동일인입니다. 또는 비동일인입니다)을 도출해야 한다는 유의점을 사전 고지했습니다. NIST에서는 사용자가 제출한 리눅스(Linux) 라이브러리 파일을 직접 실행해 각 테스트 데이터셋 얼굴 이미지쌍을 상대로 얼굴 인식 알고리즘의 성능 정확도를 평가합니다.
AI Lab이 과제를 해결한 방법
AI Lab은 얼굴 인식 분야에서 많이 사용하는 모델인 ResNet-1005[1]을 훈련했습니다. 학습에는 AI Lab이 자체적으로 확보한 10만 명의 인물로부터 획득한 1,000만 여장의 얼굴 이미지를 활용했으며, 검증에는 NIST에서 공개한 일반 사진 데이터셋(IJB6-B,C)과 FRVT에서 제공한 상반신 사진을 활용했습니다.
문제는 추론이었습니다. 주최 측의 설명대로라면, 단 1초 안에 [그림 3]에 기술된 1~4단계를 거쳐 추론 결과를 제시하는 제약이 걸려있기 때문입니다. 이에 AI Lab은 총 3차례에 걸친 도전을 통해 제시간 내로 더 정확한 추론 결과를 내는 전략을 고민했습니다.

1.적절한 컴퓨팅 환경 설정하기
NIST에서는 서버 운영체제를 CentOS7로 제한했습니다. 이에 AI Lab은 운영체제 설치와 반납이 쉬운 사내 가상 서버에 CentOS를 설치했습니다. 하지만 NIST가 제약을 둔 동일한 컴퓨팅 환경이 아니라서 알고리즘의 추론 속도를 정확하게 산출하기가 쉽지 않은 문제가 있었습니다. 가상 서버에서의 CPU 동작 속도가 기대치보다 더 느렸기 때문이죠.
첫 번째 제출 이후 AI Lab은 개발 환경 개선 작업에 나섰습니다. 제출 당시 사용했던 가상 서버 환경이 NIST가 제시한 것보다 느렸던 점을 고려하며 상대적인 속도를 측정했습니다. 그 결과, 두 번째 제출부터는 NIST가 제시한 것과 유사한 컴퓨팅 환경을 구축할 수 있었습니다.
2.추론 플랫폼 통일하기
AI Lab은 자사가 보유한 얼굴 검출 모듈과 얼굴 정렬 모듈은 파이토치(Pytorch)로, 얼굴 인식 모듈은 mxnet에서 학습돼 도커(docker)8로 각기 따로 서비스하고 있습니다. 문제는 앞서 설명한 대로 대회에 참가하기 위해서는 서로 의존성이 없는 세 모듈을 C++9로 동작할 수 있게 만들어야만 하는 데 있었습니다.
시간이 촉박했던 1차 제출에서는 AI Lab가 기존에 보유하던 3가지 모듈을 급하게 합치느라 코드를 충분하게 검토하지 못했습니다. 파이토치, mxnet을 비롯한 대다수의 딥러닝 플랫폼은 파이썬(Python) 뿐만 아니라 C++에서도 모델 파일을 읽어 들여서 추론하는 기능을 제공합니다. AI Lab은 효율적인 운영을 위해 딥러닝 플랫폼 단일화가 좋겠다고 판단했습니다. 그 구조가 복잡해 플랫폼 변경이 쉽지 않은 얼굴 검출 모듈에 사용된 파이토치를 기준 삼아, 얼굴 인식 모듈을 파이토치로 변환하기로 하였습니다.
이미 파이토치로 구현된 얼굴 검출 모듈과 얼굴 정렬 모듈은 C++에서 사용 가능한 torch script10 파일로 쉽게 변환할 수 있었습니다. 아쉽게도 1차에서는 MMdnn11를 이용해 mxnet으로 구현된 얼굴 인식 모듈을 파이토치 코드로 변환할 때, 배치분포 정규화(batch normalization)12 층의 매개변수(parameter) 값을 그대로 복사하지 못하는 문제를 인지하지 못했습니다. 이렇게 되면 0.00000x 차이로도 출력 결과가 달라져 성능 저하에 큰 영향을 미치게 되죠. 2차 제출에서는 이 문제를 해결해 추론 정확도를 대폭 높였으나, 상위권에 오르기에는 다소 부족했습니다.
세 번째 제출에서 AI Lab은 세 모델을 torch script 대신, 인텔 CPU에 최적화되어 빠른 추론 속도를 제공하는 openvino 파일로 변환했습니다. 컴퓨터 비전 딥러닝 모델에서 주로 활용하는 컨볼루션(convolution)13과 배치분포 정규화 층의 매개변수를 합쳐 한 번의 연산만 수행할 수 있어(layer fusion) 속도 향상을 기대할 수 있다고 내다봤기 때문입니다. AI Lab이 자사 서비스 개발에 openvino를 사용해본 경험도 이 결정에 영향을 미쳤습니다.
다만 openvino는 기본적으로 멀티스레드(multi-thread)14로 동작합니다. 몇몇 매개변수를 조절해봐도 최소 3개의 쓰레드를 사용하도록 강제하죠. AI Lab은 openvino 내부 코드 중 필요가 없는 스레드를 제거해 싱글스레드로 동작할 수 있도록 했습니다.
3.추론 정확도 높이기
제아무리 숙련된 머신러닝 엔지니어라도 데이터에 적합한 네트워크 구조를 탐색하는 데에는 수개월 공들여야 합니다. 세 번째 제출일까지는 촬영 각도와 조명, 표정, 장신구 등에 따라 큰 편차를 보이는 데이터셋에 강건한(robust) 얼굴 인식 모델 개발은 거의 불가능한 상황이었죠. 이런 이유로 AI Lab은 알고리즘 개선 대신, 테스트 단계에서의 어그먼테이션(Test-Time-Augmentation, TTA) 도입을 고려했습니다.
하나의 이미지를 여러 관점에서 관찰할 수 있도록 이미지를 좌우로 뒤집거나(flipping) 자르는(cropping) 등 다양한 기법을 아우르는 어그먼테이션은 모델의 추론 정확도를 끌어올리는 주요 방법론 중 하나입니다. TTA는 각기 서로 다른 어그먼테이션 기법을 적용한 테스트 데이터를 최종 모델(훈련 데이터와 검증 데이터로 학습을 마친 모델)에 입력하는 방식으로 성능을 끌어올립니다. 마치 서로 다른 어그먼테이션 기법을 적용한 학습 모델을 앙상블(ensemble)한 것과 비슷한 성능 향상 효과를 기대할 수 있습니다. 테스트 데이터를 모델에 여러 차례 입력하기 때문에 정답을 추론하는 시간은 좀 더 길 수는 있습니다. 하지만 최종 모델의 매개변수를 변경하지 않고도 추론 성능을 높일 수 있어서 시간과 비용을 획기적으로 줄이는 데 도움이 됩니다.
AI Lab은 이미지 한 장의 좌우를 뒤집으면 그렇지 않을 때보다 전체 추론 시간이 2배 더 가까이 소모된다는 점에서 다양한 어그먼테이션 기법을 적용하기 어렵다고 판단했습니다. 이에 앞서 두 차례 제출에서 어그먼테이션 미적용시 추론 결과 도출까지 0.5초를 넘지 않았던 경험을 바탕으로, 테스트 단계에서 이미지를 좌우로 뒤집는 플립 기법[2]을 적용해 코드를 구현했습니다.
성능 척도와 최종 결과
두 얼굴 이미지에서 특징 벡터를 추출한 얼굴 인식 시스템은 최종적으로 두 벡터 간 유사도를 비교해 점수를 산정합니다. 이 유사도 점수는 동일인 얼굴 쌍에서는 높으며, 비동일인 얼굴 이미지 쌍에서는 낮습니다. 따라서 동일인 얼굴 쌍과 비동일인 얼굴 쌍 각각에 대해 유사도 분포가 잘 분리돼 있을수록 시스템의 성능이 좋다고 할 수 있습니다.
문제는 알고리즘이 구분하기 어려운 얼굴 쌍으로 인해 두 분포가 겹치는 영역이 존재한다는 데 있습니다. 이런 이유로 얼굴 인식 알고리즘의 성능을 평가할 때는 특정 유사도 점수(T)를 기준으로 입력된 두 이미지를 동일인이라고 판단하거나 또는 비동일인이라고 판단합니다.
그렇다면 무엇을 기준으로 T를 결정할까요? 일반적으로는 비동일인 이미지쌍 데이터셋에서 동일인이라고 추론할 특정 확률(타인일치율, FMR)에 따라 결정합니다. 물론 기준이 되는 FMR 값은 평가하려는 대상에 따라 조금씩 다를 수 있습니다. 예를 들어, 출입 시스템의 성능을 평가할 때는 FMR이 낮아야 합니다. 특정인을 제대로 인식하지 못해 출입하지 못하는 쪽보다는, 허가받지 않은 특정인에게 출입 허가를 부여하는 쪽의 문제가 더 크기 때문입니다. 반면, 미아 찾기 시스템에서는 FMR이 다소 높아야 합니다. 오검출율이 늘어나더라도 최대한 많은 후보군을 뽑아낼 수 있기 때문입니다.
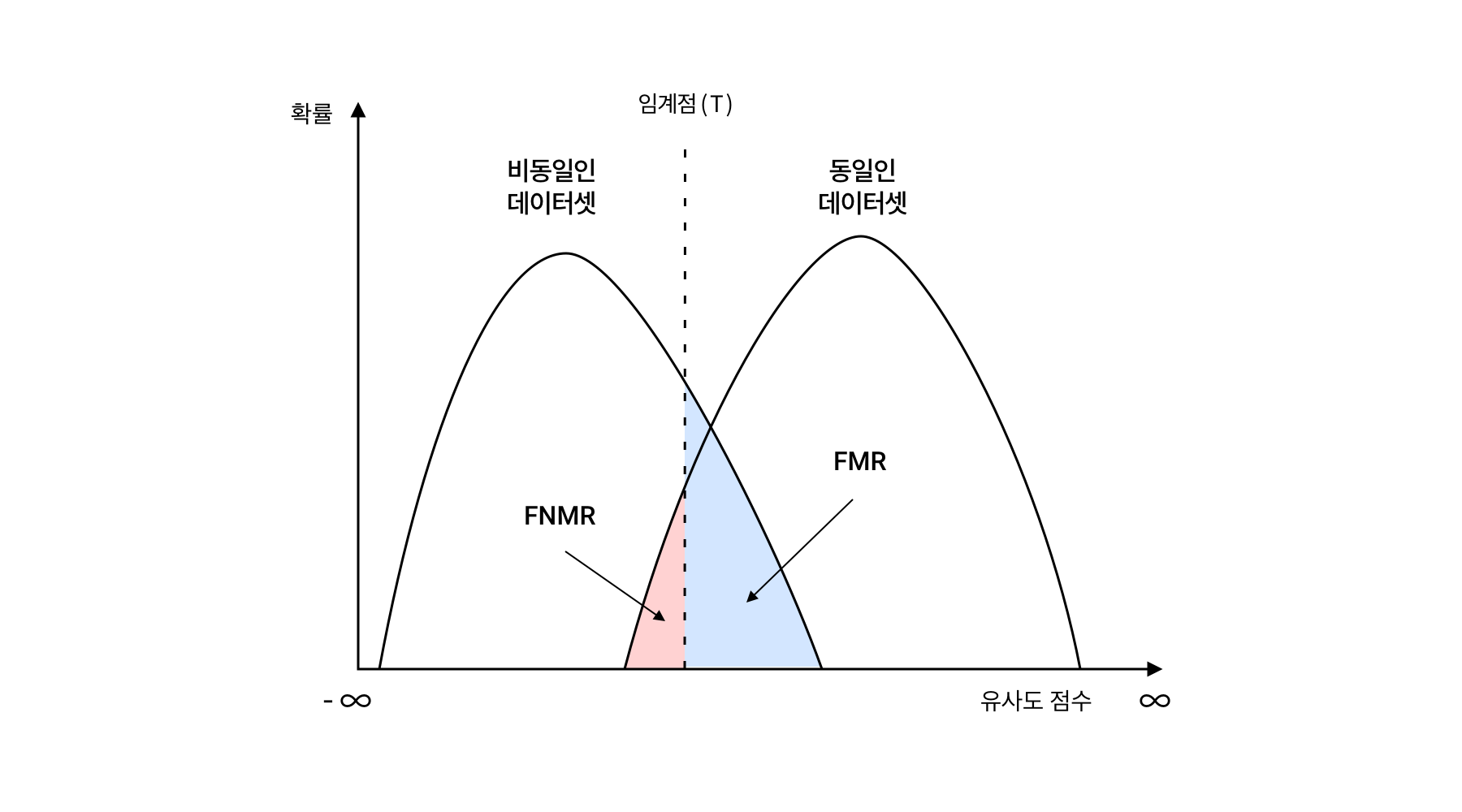
NIST는 부문별로 서로 다른 FMR(비자 사진=1e-4/1e-6, 상반신 사진=1e-5, 일반 사진=1e-4, 공항 출입국 사진=1e-6)을 만족하는 T를 기준으로 동일인 이미지 쌍 데이터셋에서 비동일인이라 추론할 확률(본인불일치율, FNMR)의 수치를 비교했습니다.
주최 측은 [표 1]처럼 테스트 데이터셋을 구축했습니다. 비자 사진과 일반 얼굴 사진 부문에서의 비동일인 이미지 쌍에서는 성별과 나이와 같은 공변량(covariate)15을 따로 제어하지 않았습니다. 이는 이미지 속 인물에 관한 정보를 모르는 상태에서 DB에 저장된 모든 인물과의 동일인 여부를 비교해야 하는 1:N 매칭 태스크로의 확장까지 염두해서 데이터셋을 설계한 것으로 보입니다. 주최 측은 추후에는 난이도가 더 높은 공변량 제어 비동일인 이미지 쌍에 대해서도 알고리즘의 성능을 평가하는 실험을 설계한다는 계획입니다.
| 테스트 데이터셋 | 동일인 이미지쌍 | 비동일인 이미지쌍 | 인물 수 | |
| visa | 미국 입국자의 비자 사진 | 10,000 | 10,000,000,000 | 100,000 |
| mugshot | 범인 식별용 상반신 사진 | 1,000,000 | 100,000,000 | 1,000,000 |
| wild | 실생활에서 촬영한 일반 얼굴 사진 | 1,000,000 | 10,000,000 | 10,000 |
| visaboarder | 공항 출입국심사대에서 촬영한 사진 | 1,000,000 | 100,000,000 | 1,000,000 |
범죄자 상반신 사진 부문의 비동일인 이미지쌍에서는 성별 이외의 다른 공변량은 따로 제어하지 않았습니다. 사진 촬영 시점에 이미 인물의 성별 정보를 알고 있다는 사실에 기인한 것으로 분석됩니다. 한편, 나이를 제한하지 않은 이유는 과거에 상반신 사진을 촬영한 범죄자가 출소 후 다른 범죄 사건에 또다시 연루될 가능성을 배제하지 않았다는 의미로 해석됩니다.
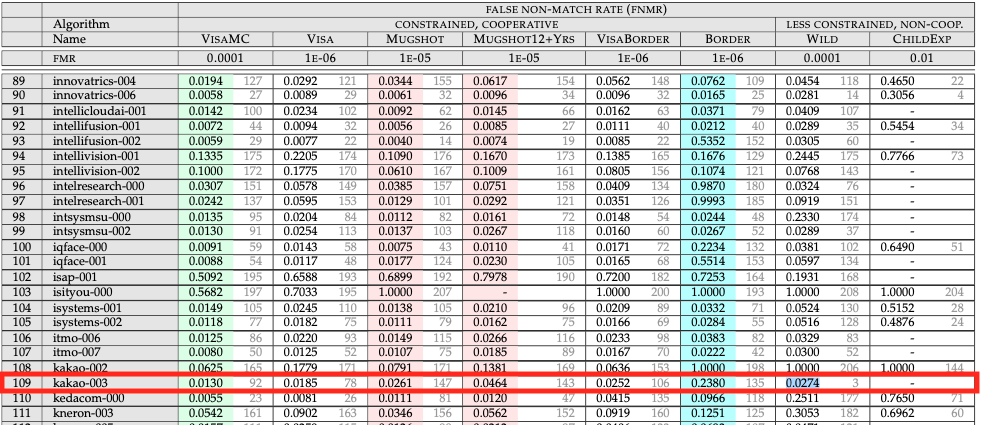
최종적으로 AI Lab은 일반 이미지 데이터셋 부문에서 FMR이 0.01%일 때 FNMR 2.74%를 달성, 1등(FNMR 2.71%), 2등(FNMR 2.73%)과 근소한 차이를 보이며 우수한 결과를 거뒀습니다([그림 5]). 다만 AI Lab은 인물마다 여러 장의 비자 사진과 상반신 사진을 구할 수 없어 해당 부문에서 중위권에 머무른 부분은 아쉽다고 자체 평가했습니다.
향후 연구 계획
AI Lab은 이번 대회 기간 중 1:1 검증 모든 데이터셋 부문에서의 상위권 진출을 목표로 자사 얼굴 인식 알고리즘 성능을 높인다는 계획입니다. 우선, 제한된 환경에서 측면 또는 정면을 촬영한 사진 데이터셋을 추가로 확보할 예정입니다. 아울러, 추론 속도 향상을 위해 알고리즘 고도화를 위한 추가 연구를 진행한다는 계획입니다. 신종주 연구원은 “최근 한 연구에서 얼굴 검출 모듈과 얼굴 정렬 모듈을 하나의 네트워크로 합쳐 좋은 성과를 냈다”며 “이 둘을 합치면 전체 추론 시간을 줄일 수 있어 추론 성능 향상에 필요한 다양한 추가 기법 도입을 고려해볼 수 있을 것으로 기대된다”고 말했습니다.
참고 문헌
[1] ArcFace: Additive Angular Margin Loss for Deep Face Recognition (2019) by Jiankang Deng, Jia Guo, Niannan Xue, Stefanos Zafeiriou in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
[2] ImageNet Classification with Deep Convolutional Neural Networks (2012) by Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton in Advances in Neural Information Processing Systems 25 (NIPS)

이수경(samantha) | 작성, 편집
지난 2016년 3월 알파고와 이세돌 9단이 펼치는 세기의 대결을 취재한 것을 계기로 인공지능 세계에 큰 매력을 느꼈습니다. 카카오엔터프라이즈에서 인공지능을 제대로 알고 싶어하는 사람들을 위해 전문가와 함께 읽기 쉬운 콘텐츠를 쓰고 있습니다. 인공지능을 만드는 사람들의 이야기와 인공지능이 바꿀 미래 사회에 대한 글은 누구보다 쉽고, 재미있게 쓰는 사람이 되고자 합니다.

신종주(isaac) | 작성, 감수
대학원에서 얼굴 특징점 검출을 전공한 뒤, 현재는 카카오엔터프라이즈에서 얼굴 영상과 관련된 연구 개발 조직을 맡고 있습니다. 연구 중인 얼굴 인식 기술이 제 두 아들이 앞으로 살아갈 세상에 도움이 되었으면 좋겠습니다.

- 지난 대회는 2000년, 2002년, 2006년, 2010년, 2013년에 열렸다. 이를 보아 FRVT는 비정기적으로 열리는 대회인 것으로 추측된다. [본문으로]
- 미국 법무부에서는 성범죄 피해 아동을 찾는 데 얼굴 인식 프로그램을 적극적으로 활용하고 있다. 다만 대부분의 학습 데이터가 성인 얼굴만으로 구성돼 있다보니 아동 식별 정확도가 낮다고 알려져 있다. [본문으로]
- 주최 측은 서로 다른 방식으로 촬영된 영상물을 대조하는 과제도 언젠가는 선보인다는 계획을 발표한 바 있다. [본문으로]
- 연산을 하나의 CPU로 순차 처리하는 방식 [본문으로]
- 지난 2015년 마이크로소프트 리서치(Microsoft Research)가 제출해 대용량 영상 분류 및 객체 검출을 위한 대회인 ILSVRC(ImageNet Large Scale Visual Recognition Competition)에서 우승을 거머쥔 딥러닝 모델을 일컫는다. 최근에는 이를 변형한 ResNet-100이 얼굴 인식 분야에서 좋은 성과를 내고 있다. [본문으로]
- NIST와 정보고등연구계획국(IARPA)이 함께 운영하는 얼굴 인식 평가용 데이터셋 [본문으로]
- 레드햇(Red Hat)에서 무료로 배포하는 리눅스 운영체제 [본문으로]
- 하나의 서버에 분리된 공간을 만들어 개발자가 원하는 프로그램을 설치하고 동작할 수 있게 만든다. 예를 들어, 도커를 이용하면 GPU 메모리를 나눠서 여러개의 서비스를 동시에 가동할 수 있다는 점에서 GPU 사용 효율성을 높일 수 있다. [본문으로]
- 프로그래밍 언어 중 하나 [본문으로]
- C++에서는 torch script 파일을 읽어서 추론 결과를 내놓는다. [본문으로]
- 여러 딥러닝 플랫폼에서 만든 모델을 서로 변환하는 기능을 제공하는 프로그램 [본문으로]
- 데이터의 분포가 평균 0, 분산 1 근처일 때 신경망 학습이 잘 되는 것으로 알려져 있다. 이 때문에 데이터의 분포를 미리 조정하는 일(normalization)은 신경망 학습의 가장 기초적인 전처리과정 중 하나다. 데이터가 깊은 신경망을 통과하면서 이 분포가 무너진다는 데 있다. 내재 분포 이동(internal covariate shift)이라 불리는 이 현상은 깊은 신경망의 느린 학습의 주범 중 하나였다. 층마다 다시 데이터의 분포를 표준화(normalization)해주는 배치 분포 정규화를 통해 이 문제가 해결됐다. [본문으로]
- 이미지에서 숨은 특징을 추출하는 층 [본문으로]
- 서버내 여러 CPU 자원을 동시에 사용해 연산 속도를 높이는 방식 [본문으로]
- 독립변수(실험변수) 외 종속변수(결과변수)에 영향을 줄 수 있어서 통제해야하는 변수 [본문으로]




댓글