



시작하며
안녕하세요. 카카오엔터프라이즈 자연어서비스 팀의 Rung(이주성)입니다. 저희는 마치 사람과 대화하는 것처럼 자연스러운 소통이 가능한 인공지능(AI) 챗봇을 연구하고 있는데요. 이런 연구의 일환으로 저희 팀은 2021년 6월 AI 대화 시스템 분야에서 대표적인 국제 경진대회인 ‘DSTC10’에 참가했습니다.
사실 DSTC 챌린지는 저희가 중점적으로 연구 중인 오픈 도메인 칫챗(Open Domain Chit-chat)이 아닌 목적형 대화 시스템(Task-oriented Dialogue System)을 다루고 있는데요. 오픈 도메인 칫챗은 아니지만, 저희 내부적으로 멀티모달(Multi-modal, 이미지나 텍스트 등의 한 가지 형태가 아닌 여러 형태로 컴퓨터와 대화하는 환경) 처리에 대한 관심이 높았기 때문에 DSTC에 참가하게 되었습니다.
카카오엔터프라이즈는 DSTC10의 세 번째 트랙인 SIMMC(Situated Interactive MultiModal Conversations) 2.0에 참가했는데요. 결과적으로 #1과 #2 과제에서 3위를, #4 과제에서는 2위에 오르는 성과를 거두었습니다. 이번 포스팅에서는 DSTC에 참여한 과정과 저희 팀이 달성한 성과에 대해 소개해 드리겠습니다.

SIMMC 2.0 과제
매년 열리는 DSTC는 벌써 지난 해로 10회를 맞이했습니다. DSTC는 여러 주제의 과제가 챌린지 형식으로 동시에 진행되는데요. 작년 10월 개최된 DSTC10에서는 총 5개의 주제가 선정되었고, 저희 카카오엔터프라이즈는 페이스북(현재 Meta)이 주관한 Situated Interactive MultiModal Conversations 2.0(이하 SIMMC 2.0)에 참가했습니다.
SIMMC 2.0는 아래 그림 2와 같이 사용자(User)가 쇼핑을 하면서 AI 시스템과 대화하는 실생활의 상황을 나타내는 어시스턴트(Assistant)에 대한 주제로서, 의류와 가구 도메인 안에서 이미지와 텍스트로 구성된 멀티 모달 데이터셋으로 실생활에 가까운 Photo-realistic VR scenes를 제작하는 것이었습니다.

SIMMC 2.0 챌린지에서는 세부적으로 4 가지 과제(Task)를 제시합니다. 1~3번째 과제는 사용자 발화에 대한 과제이고, 4번째 과제는 대화 흐름에 맞게 적절한 시스템 발화로 응답하는 과제입니다.
각 과제 마다 주어진 데이터와 사용할 수 있는 정보들은 달랐는데요. 학습과 테스트 상황에서 모두 사용할 수 있는 데이터로는 현재 응답 순서(Turn) 이전의 ‘AI 어시스턴트 발화 정보’와 상품의 위치를 가리키는 ‘바운딩 박스(Bounding Box) 정보’가 있었습니다. 이때, 상품들에 대한 시각적 묘사(Visual Description)와 비시각 묘사(Non-visual Description)가 따로 구분되는데, 과제에서는 시각적 묘사(Visual Description)만 학습에 사용할 수 있었습니다. 과제에서 주어진 데이터 정보가 궁금하시면, 메타 리서치의 깃허브에서 확인하실 수 있습니다.
Multimodal Disambiguation
첫 번째 과제는 Multimodal Disambiguation로, 멀티모달의 애매모호함을 판단하는 과제입니다.
우리는 일상 생활에서 이미 언급된 물건을 말할 때, “저거” 또는 “아까 봤던 것" 등의 공동 참조를 주로 사용합니다. 이해를 돕기 위해 다음과 같은 대화를 살펴보겠습니다.

예시 대화를 살펴보면 애매모호한 느낌이 들 수 있습니다. 즉, 사용자가 발화한 “저건(those)"은 상황에 따라 파란색 바지(blue trouser)를 의미할 수도 있지만, 이 대화 이전에 언급되었던 다른 바지를 의미할 수도 있습니다. 이와같이 “저건(those)"과 같은 공동 참조는 애매모호할 수 있으며, 이런 발화를 애매모호한 발화로 분류하는 작업이 첫 번째 과제였습니다.
Multimodal Coreference Resolution
두 번째 과제는 Multimodal Coreference Resolution으로, 사용자 발화와 연관된 상품(Object)이 무엇인지를 알아내는 것입니다. 물론 발화에 따라 연관된 상품이 없을 수도 있습니다.
그럼 다음과 같은 대화를 가정해보겠습니다.

상황 1에서는 지시대명사 ‘그거(it)’는 앞서말한 XL 사이즈의 셔츠를 가리킨다는 것을 쉽게 알 수 있는데요. 시스템 발화 정보가 있기 때문에 대화 텍스트만으로도 사용자 발화와 연관된 상품을 쉽게 알 수 있습니다.
하지만, 상황 2와 같이 “저기 빨간색 셔츠 얼마야?”의 사용자 발화만 있는 상황이라면 빨간색이 어떤 상품을 의미하고 가리키는지 알 수 없습니다. 대화에서 보면 서로 언급하고 있는 상품이 빨간색인지 파란색인지, 그 상품이 셔츠인지 바지인지 관련된 정보가 명확하게 주어지지 않았기 때문인데요. 두 번째 과제에서는 앞서 언급했던 바와 같이 시각적 묘사(Visual Description)를 사용할 수 없는 경우에는 대화 텍스트 외에 상점의 배경(Background) 이미지를 활용해서 어떤 상품이 빨간색 셔츠인지 알아내야 합니다.
추가적으로 상황 3과 같이 사용자가 “네가 말한거 옆에있는 건 얼마야?” 라고 물어보는 상황을 고려해보면, 해당 발화와 연관된 상품을 알아내기 위해 먼저 대화 흐름을 고려하여 이전에 언급된 상품이 무엇인지를 알아내야 하고, 그 옆에 있는 물체를 배경(Background)을 통해 확인하는 과정이 필요합니다.
Multimodal Dialog State Tracking
세 번째 과제는 Multimodal Dialog State Tracking이며, 멀티모달 콘텍스트를 기반으로 사용자의 Belief States를 Tracking하는 목적으로 제공되었는데요, 저희 카카오엔터프라이즈에서는 이번 대회의 리소스를 고려하여 본 과제에는 참여하지 않았습니다.
Assistant Response Generation
네 번째 과제는 Assistant Response Generation으로, 대화 이전에 나눈 대화를 바탕으로 시스템이 적절한 답변 발화를 생성하거나 선택하는 부분이었습니다. 저희 카카오엔터프라이즈에서는 발화 시스템에 따라 적절한 발화를 생성하는 방법에 초점을 맞춰 참여하였습니다.
과제 해결 과정
SIMMC 2.0에 주어진 4 가지 과제는 독립된 챌린지의 개념으로 제공되고 있는데요, 이러한 과제는 개별로 참여 여부도 정할 수 있고 이에 따라 과제별로 순위도 각각 정해지게 됩니다. 하지만, 각각의 과제가 서로 연관이 있기 때문에 모델을 생성하여 멀티 과제로 학습시키거나, 다른 과제의 추론 결과를 활용하는 것이 전체적인 성능 향상에 도움이 될 수 있습니다. 이런 이유로 저희 카카오엔터프라이즈에서도 모든 과제에 참여하고 싶었지만, 한정된 리소스를 고려하여 #1, #2, #4-1 과제에만 집중하기로 결정하고 문제 해결을 시도하였습니다.
저희는 각 과제에 대해 문제 해결을 시도하기 전에 각 도메인의 사전학습 모델(Pre-trained Model)을 활용했는데요. 텍스트 학습에는 ‘RoBERTa’를, 이미지 학습에서는 ‘DeIT’을 사용했습니다.


또한, 저희는 멀티모달 사전학습(Pre-training)을 위해 위 그림과 같이 두 가지 매칭을 구성했습니다. 과제에서는 텍스트 상황에 상품 색상, 패턴, 타입 등의 시각적 정보를 사용할 수 없으므로, 첫 번째 매칭에서는 상품과 시각적 정보를 매칭하는 모델인 ITM(Image-to-Text Matching)을 제안했습니다. 두 번째 매칭에서는 배경(Background)과 대화 컨텍스트를 매칭시키는 BTM(Background-to-Text Matching)을 제안했는데요. BTM을 통해 배경 정보를 바로 텍스트 모델과 결합하기 전에 배경(Background), 표현(Representation), 텍스트 표시(Text Representation) 분포를 같은 공간에 모이게 하면 멀티모달이 배경 정보를 보다 잘 이해할 수 있을 것이라고 생각했습니다. 이를 위해, 저희는 매칭 함수로 CLIP 방법과 유사하게 코사인 유사도(Cosine Similarity)를 스케일업하여 시그모이드(Sigmoid) 함수를 사용했습니다.
Multimodal Disambiguation

저희 카카오엔터프라이즈에서 텍스트 모델의 사전학습 모델로 제안한 RoBERTa에는 대화 콘텍스트가 들어가며, 이미지 모델로 제안한 DeIT에는 이전 시스템 발화에서 언급된 상품 정보가 들어갑니다. DeIT의 입력으로 활용될 상품은 발화와 관련된 상품들만 들어가는 게 이상적입니다. 하지만, 발화와 관련된 상품 정보는 주어지지 않기 때문에, 저희는 전체 상품 중 비교적 연관성이 높은 이전에 언급된 상품들을 입력 정보로 넣었습니다. 또한 DeIT는 멀티모달 사전학습에서 학습된 DeIT-I가 초기값으로 사용되기 때문에, DeIT-I의 출력이 상품의 비주얼 정보를 담고 있다고 간주했습니다. 이렇게 선택된 대화 콘텍스트의 피쳐(Feature)에 상품 피쳐를 더해서 발화의 애매모호함을 판단할 수 있었습니다.
Multimodal Coreference Resolution
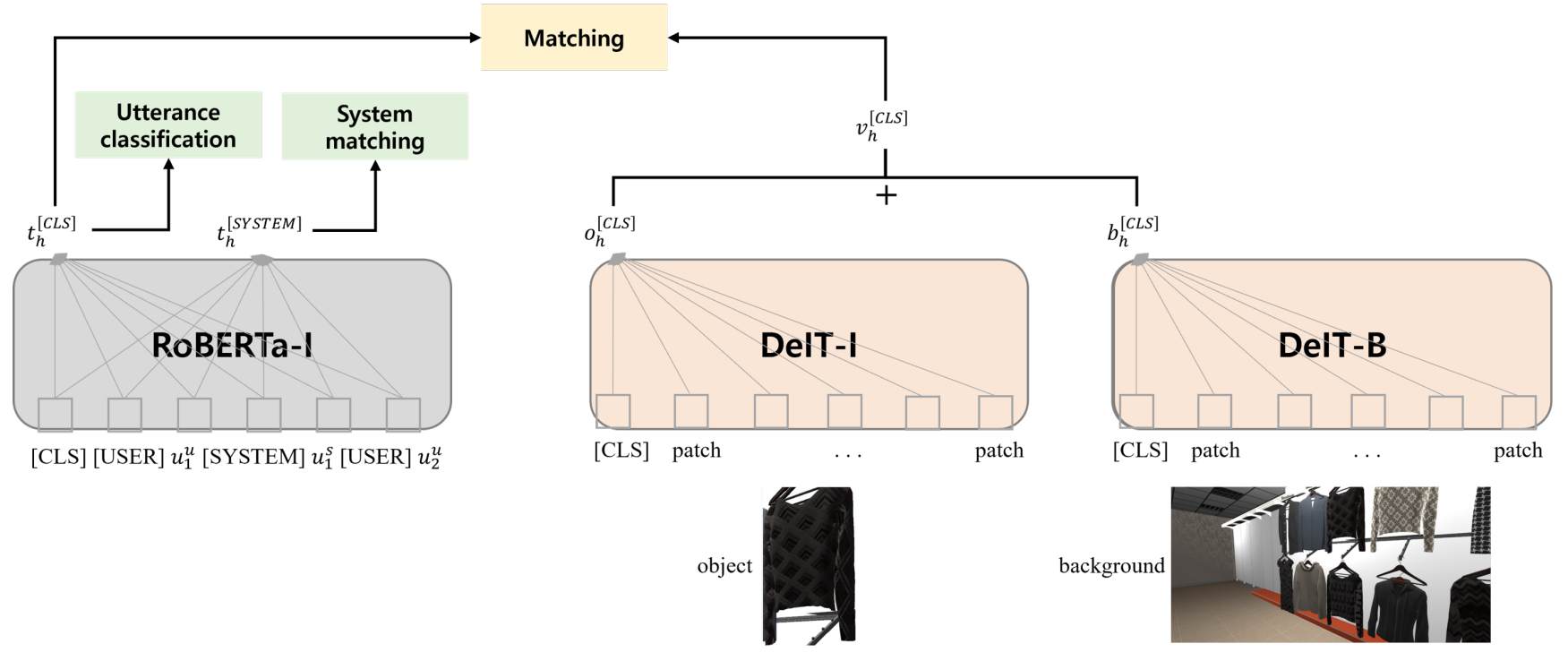
두 번째 과제는 현재 발화와 연관된 상품을 찾는 것입니다. 발화와 연관된 상품을 매칭하는 과정은 멀티모달 사전학습과 유사한 과정이기 때문에, 저희는 멀티모달 사전학습에서 설정했던 RoBERTa와 DeIT의 초기값을 그대로 사용했습니다. RoBERTa-I에는 대화 콘텍스트를 입력했고, DeIT-I에는 매칭할 상품 정보를 입력했습니다. 추가적으로, 상품을 담고 있는 배경(Background)을 DeIT-B에 통과 시켜 배경 정보도 반영했으며, 대화 콘텍스트의 피쳐(Feature)와 상품/배경의 피쳐를 더해 매칭을 진행했습니다.
이외에, 저희는 여러 데이터도 살펴보고, 다양하게 실험을 하던 중 저희는 다음과 같은 두 가지 사실을 발견했습니다. 첫 째, ‘이전에 시스템 발화에서 언급된 상품은 현재 발화와 연관성이 높다’라는 점과, 둘 째, ‘발화와 연관된 상품이 없는 경우가 상당히 많다’ 였습니다. 이는 조금만 생각해보면 당연한 사실일 수 있지만, 연구를 해보니 이런 명제를 보다 실질적으로 확인할 수 있었습니다. 이 명제를 풀기 위해, 저희는 텍스트상으로 확인할 수 있는 두 가지 멀티과제를 제안했습니다.
< 카카오엔터프라이즈 연구팀에서 수행한 멀티과제 >
| 멀티과제 | 목적 |
| 발화 분류 (Utterance Classification) |
상품과 관련 없는 발화를 필터링하고, 현재 발화와 연관 지을 상품이 있는지 판단 |
| 시스템 매칭 (System Matching) |
모든 상품에 대해 발화와 연관성이 있는지 판단하기 전에 먼저 상품을 그룹화하여 현재 발화와 연관 있는 시스템 발화를 찾음 ﹒ 현재 발화와 연관된 시스템 발화에서 참조한 상품이라면 현재 발화와도 연관된 상품일 가능성이 큼 ﹒ 그 외의 시스템 발화에서 참조한 상품 또는 이전 대화에서 언급되지 않은 상품도 현재 발화와 연관되지 않은 상품일 확률이 높음 |
저희는 위에서 언급한 두 가지 멀티과제(발화 분류와 시스템 매칭)를 풀기위해, 다음과 같은 로직을 제안하여 발화와 상품의 매칭 유무를 결정했습니다.

마지막으로 학습 데이터에 mention_inform 정보를 사용하는지에 따라 모델의 장단점이 달라지게 되는데요. 여기에서 mention_inform은 주어진 대화에 연관된 모든 상품 리스트로, 학습에서만 사용할 수 있습니다. 학습에 mention_inform을 사용하게 되면 현재 발화에서 매칭할 상품의 후보군에 비교적 연관된 상품이 많게 됩니다. 반면, mention_inform을 사용하지 않으면, 관련없는 상품들까지 모두 비교해봐야 하니 매칭이 안되는 상품을이 모델에 많이 나타나게 됩니다. 즉, mention_inform을 사용하면 Positive 샘플을 많이 보게 되며, 사용하지 않으면 Negative 샘플을 많이 봅니다. 따라서 저희는 모델의 장점에 따라 상품의 매칭 여부를 모델로 결정할지, 1 또는 0으로 간주할지를 지정했습니다.
Assistant Response Generation
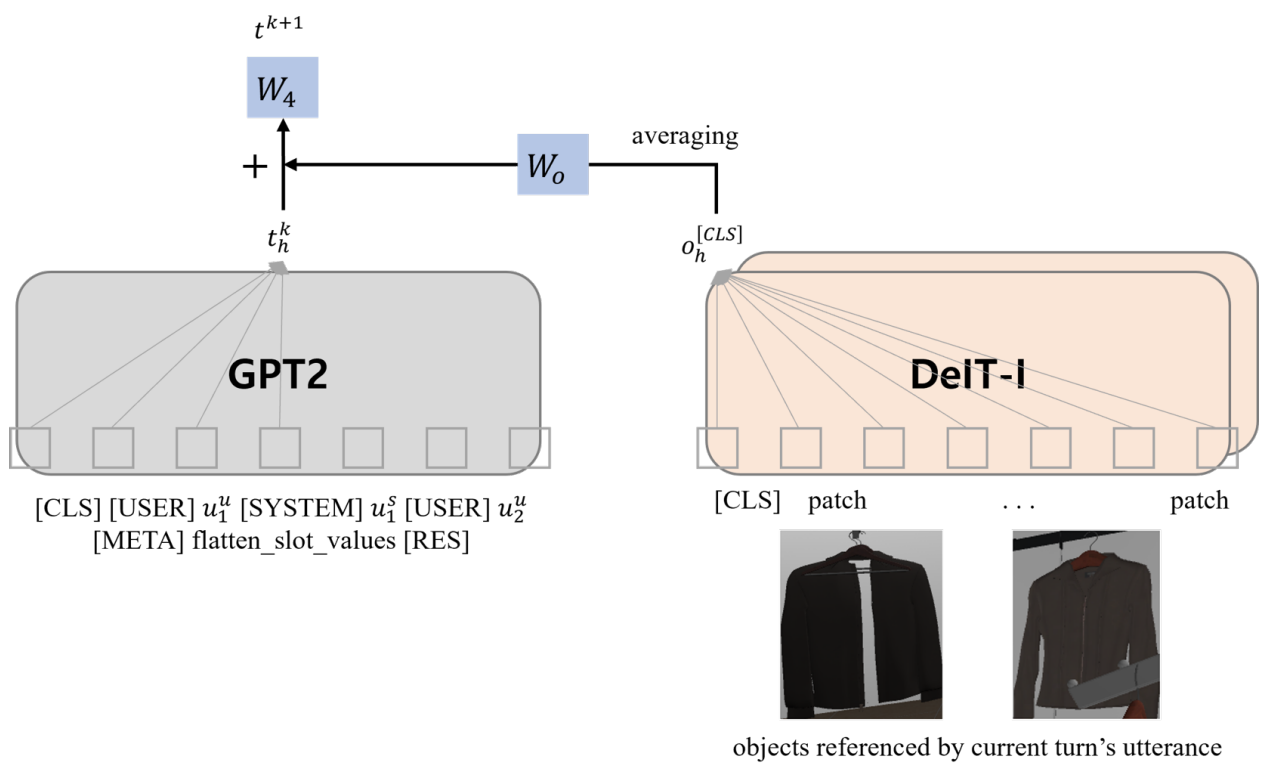
네 번째 과제는 Assistant Response Generation으로, 앞의 대화에 대해 적절한 시스템 발화를 생성 또는 선택하는 것이었는데요. 저희는 연구 리소스의 문제로, 시스템 발화 선택 과제는 참여하지 않고, 시스템 발화 생성 과제에만 부분적으로 참여했습니다. 시스템 발화 생성 과제는 이전 과제들과 달리 적절한 응답을 생성해야 하는 과제이기 때문에 텍스트 모델로 GPT2을 사용했습니다. 또한 네 번째 과제에서는 slot_value 정보를 사용할 수 있었는데요. slot_values는 현재 생성할 시스템 발화에 포함될 정보의 일부라고 생각하시면 됩니다. 따라서 저희 팀은 대화 히스토리 뒤에 slot_values를 붙여서 텍스트 입력을 생성했습니다. 상품 정보는 DeIT-I로 추출된 피쳐로 GPT2 마지막 토큰의 출력 벡터에 더해서 활용했습니다.
결과
이번 SIMMC 2.0에는 카카오엔터프라이즈를 포함한 총 10개 팀이 참가했습니다. 각 팀마다 참가한 과제는 다르지만, 과제마다 최대 4개 모델을 제출할 수 있고, 가장 좋은 모델을 기준으로 그룹별 순위가 매겨졌습니다. 그룹별 순위의 경우, 주최측에서 각 과제에서 점수 차이가 작다면 같은 급의 순위라고 판단하고 평가하기 때문에 ‘공동 등수’의 개념이라고 보시면 됩니다. 또한, 연구 방법을 공개하지 않은 팀과 제출 기간이 종료된 후에 과제를 제출된 팀은 순위에서 제외됩니다.
카카오엔터프라이즈는 #1과 #2 과제에서 각각 3등 그룹, #4-1 과제에서 2등 그룹에 선정되었는데요.
#1 과제는 참가팀이 제출한 모델에 성능 차이가 상당히 작았습니다. 관련된 오류 케이스를 살펴보니, 멀티모달의 상황을 제대로 이해해야지만 맞출 수 있는 경우가 많았는데요. 저희는 적정 수준의 성능을 달성하기는 쉽지만, 그 이상의 성능을 달성하는 것은 상당히 어렵다고 느껴졌습니다. #2 과제는 텍스트 관점과 시각적 관점으로 각각 문제 해결을 시도할 수 있었던 만큼, 10개 팀이 모두 참가했으며 경쟁도 가장 치열했지만, 나름 의미있는 성과를 거둘 수 있습니다.
#4-1 과제는 평가 메트릭으로 자동 평가 방법인 BLEU를 사용하는데요. BLEU는 정답으로 주어진 문장과 얼마나 키워드적으로 유사하게 문장을 생성하냐를 평가합니다. 일반적으로 생성 평가 메트릭은 자동 평가만으로 힘들기 때문에 이처럼 BLEU만으로는 판단하기 어려울 수 있습니다. 하지만 SIMMC는 목적 지향형 대화로 시스템 발화의 형태에 일정 부분의 형식이 있기 때문에 BLEU로 판단을 한 게 아닐까 유추해봅니다.
저희는 각 과제에서 절제 연구(Ablation Study)를 통해, 저희팀이 제안한 방법들이 효과적임을 증명했습니다.
대회가 끝나고 공개된 다른 팀들의 방법론을 살펴보니, 저희가 제시한 방법과 많이 달랐습니다. 오히려 저희 카카오엔터프라이즈의 방법이 유독 다른 느낌을 받았는데요. 보통 다른 참가 팀들의 방법론은 크게 두 가지 흐름이 있었습니다.
첫 번째는 많은 참가팀들이 모든 과제를 함께 학습하는 멀티과제 러닝으로 과제를 해결했다는 점입니다. 즉, #1~ #4 과제 간 상호 상관 관계가 있기 때문에, 모델이 이 과제를 함께 학습하면서 좋은 시너지를 만들 수 있었을 것입니다. 이는 NLU(Natural Language Understanding)와 NLG(Natural Language Generation)를 동시에 수행해야함을 의미하며, 이를 위해 인코더-디코더 기반의 BART를 백본(Backbone)으로 많이 사용함을 알 수 있었습니다. 두 번째는 저희처럼 이미지의 정보를 사용하지 않는 팀들도 많았다는 것이었는데요. 대신 이미지에 관련된 메타 정보들을 텍스트로 붙여서 많이 활용했음을 알 수 있었습니다. 직관적으로는 이미지의 정보를 활용해야 상품의 특성을 파악할 수 있다고 생각되지만, 그 외의 메타 정보들이 더 중요한 경우가 많지 않았나 생각됩니다.
마치며
서두에서 언급했지만, 저희 카카오엔터프라이즈가 SIMMC 2.0에 참가한 계기는 멀티모달 처리에 대한 흥미 때문이었는데요.
요즘 사람들은 대화를 할 때 텍스트 대신 이미지 또는 밈을 많이 주고받는데, 오픈 도메인 칫챗들은 오직 텍스트로만 대화를 하는 점에 대해 아쉬움이 있었습니다. 먼 미래가 되겠지만, 멀티모달을 어우르는 챗봇이 언젠가는 필요할 테고, 이 때를 대비하여 멀티모달 처리에 대해 연구해 보고자 SIMMC 2.0에 참가하게 된 것입니다.
되돌아보면, 리소스의 문제로 인해 모든 과제에 참여할 수 없어 선택적으로 과제에 참가하게 된 부분은 아쉬움으로 남습니다. 아마 네 가지 과제에 모두 참여해 과제를 풀어나갔다면 다른 참가팀들 처럼 여러 과제를 같이 동시에 학습하는 프레임워크도 시도해보고, 좀 더 다양한 방법론을 시도해 볼 수 있었을 것입니다. 하지만 저희 카카오엔터프라이즈는 주어진 환경과 리소스에서 충분히 여러가지 방법을 시도하였고, 처음으로 참여한 챌린지임에도 불구하고 나름대로 유의미한 성과를 달성했다고 생각합니다.
멀티모달 처리를 다뤄보니, 멀티모달 처리는 아직 매우 어려운 문제이고, 이를 텍스트와 결합하는 작업이 그리 쉽지는 않을 것 같다는 생각이 듭니다. 하지만, 저희 팀 모두는 AI가 점점 발전하고 여러 기술이 오픈될수록 멀티모달 처리가 점점 더 관심받지 않을까하는 공통적인 생각을 해보았습니다. 저희가 SIMMC 2.0에 참여하면서 연구한 논문은 Kakao Enterprise AI Research에서도 확인할 수 있으니, 관심있는 분들은 살펴보시면 좋을 것 같습니다.
그럼, 언젠가 멀티모달을 카카오엔터프라이즈 서비스의 대화형 챗봇에 녹여볼 수 있기를 기대해보며, 글을 마치도록 하겠습니다. 감사합니다.
Multimodal Interactions Using Pretrained Unimodal Models for SIMMC 2.0
Abstract
kakaoenterprise.github.io
참고 문헌
[1] SIMMC 2.0: A Task-oriented Dialog Dataset for Immersive Multimodal Conversations (2021) by Satwik Kottur∗ , Seungwhan Moon∗ , Alborz Geramifard, Babak Damavandi in Facebook Reality Labs & Facebook AI


Rung (이주성)
연구에 막연한 환상을 품고 대학원에 진학, 이미지의 신호를 처리하는 AI 세계에 첫 발을 내딛었습니다. 그러다, 새로운 분야를 개척하고 싶어하는 제 지적 호기심이 저를 언어처리 분야로 이끌었습니다. 이에 현재는 카카오엔터프라이즈 자연어서비스팀에서 사람처럼 대화를 나누는 인공지능 모델을 만들고 있습니다. 사람들에게 신선함을 주는 AI, 그리고 더 많은 분야에서의 AI를 만들며 성장해나가고자 합니다.




댓글