



시작하며
현대인은 자신이 원하는 정보를 찾는 데 점차 많은 어려움을 느끼고 있습니다. 언제 어디서나 경제적인 부담없이 편리하게 정보를 습득할 수 있는 인터넷이 가진 장점과는 별개로, 유용한 정보에 접근하는 데에는 물리적인 한계가 존재하기 때문입니다. 모르거나 모를 수밖에 없는 정보량이 압도적으로 많이 생산되고 있어 특정 상황과 조건에 따른 답을 파악하기가 쉽지 않죠. 이런 이유로 부정확하거나 잘못된 정보를 습득할 가능성도 이전보다 더 높아짐은 물론, 검색 정보를 이해하고 활용하는 수준이 낮아서 발생하는 새로운 형태의 불평등도 야기되고 있습니다.
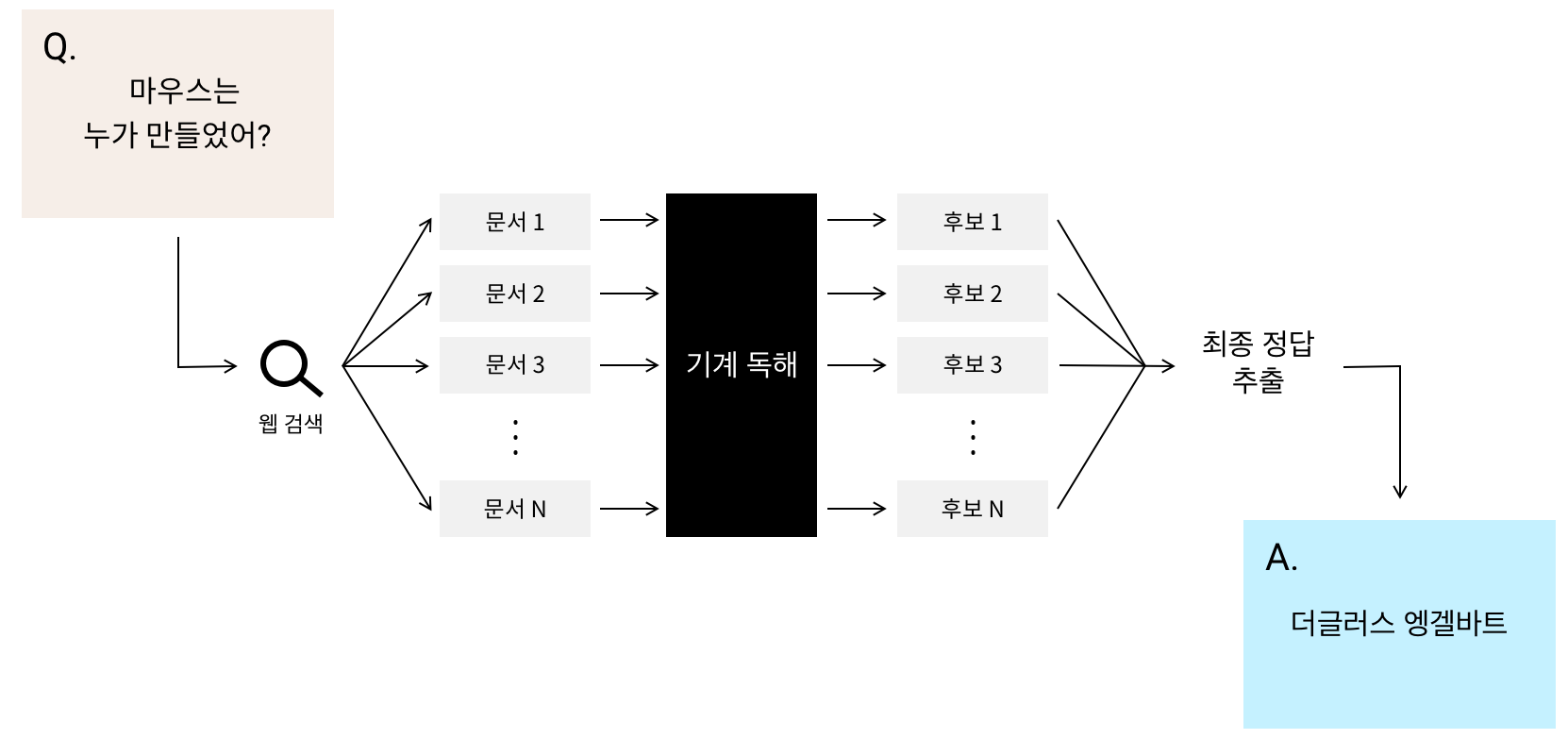
카카오엔터프라이즈 AI Lab(이하 AI Lab)이 자사 인공지능 기술을 집약한 플랫폼인 '카카오 i'의 대화 엔진 1을 고도화하는 이유는 사용자에게 도움이 될만한 정보를 효율적으로 찾아주는 검색 시스템의 중요성을 인지하고 있기 때문입니다. 그 중에서도 음성, 키보드와 같은 다양한 인터페이스를 통해 입력된 사용자 질의(query)에 대한 답을 포함하는 후보 문서에서 정답 부분을 추출하는 기술인 ‘질의 응답’에 대한 연구([그림 1])를 활발하게 진행하고 있습니다.
이번 글에서는 질의 응답 시스템을 구성하는 요소 중 하나인 딥러닝 기반 정답 유형(서술형, 단답형) 분류 모델을 소개해보고자 합니다. AI Lab AI기술팀 자연어처리파트의 조승우 연구원을 만나 자세한 이야기를 들어봤습니다.
※이번 글은 조승우 연구원과 최동현 연구원이 2019년 7월부터 2020년 2월까지 진행한 연구를 바탕으로 내용을 구성했습니다.
☛ Tech Ground 데모 페이지 바로 가기 : 지문분석 데모 | 통합분석 데모
질의 응답 시스템이란
카카오 i 대화 엔진은 사용자 질의 분석을 통해 호출 의도에 따른 적합한 시스템을 가동합니다. 이 내용은 ‘카카오미니의 명령어 분류 방법’이라는 글에 서술된 대화 엔진의 동작 방법에서 좀 더 자세히 살펴볼 수 있습니다. 그 중에서도 [표 1]에서처럼 인텐트 분류 단계를 거친 사용자 발화가 답변을 요구할 때 질의 응답 시스템이 활성화된다고 보시면 됩니다.
| 질의 | 답변 |
| 토사구팽이 뭐야? | 필요할 때 이용하다가 필요가 없어지면 버리는 일을 비유한 사자성어 |
| 소방서 전화번호가 뭐야? | 119 |
| 아시아나 온라인 체크인은 언제부터 가능해? | 출발 48시간 전부터 |
| 이효리가 속한 그룹 이름이 뭐야? | 핑클 |
| 올림픽 공원은 어디에 있어? | 서울 송파구 올림픽로 424 |
| 교보문고 강남 어디에 있어? | 서울특별시 서초구 강남대로 465 |
| 김태희 누구랑 결혼했어? | 비 |
질의 응답 시스템의 작동 과정은 다음과 같습니다. 첫 번째, 입력 문장을 분석해 검색에 유용한 쿼리를 생성합니다. 두 번째, 추출된 검색 쿼리를 활용해 찾은 모든 문서를 기계 독해에 적합한 형태로 잘게 쪼갭니다. 세 번째, 잘게 쪼갠 텍스트에서 후보 정답을 추출합니다. 네 번째, 후보 정답 중 질문에 가장 적합한 정답을 제공합니다.
마지막 네 번째 단계에서 질의 응답 시스템은 질문과 가장 연관성이 높은 N개의 문서를 분석해 얻은 1) 서로 다른 N개의 정답을 각각 제시하거나, 또는 2) 여러 후보군에서 가장 적합한 단일 정답을 제시할 수 있습니다. 스마트 스피커와 같은 음성 인터페이스나 스마트폰과 같은 소형 디스플레이에서는 텍스트를 쪼갠 수만큼 늘어난 추출된 모든 정답을 사용자에게 그대로 제공하는 방식은 사용자에게 큰 불편함을 초래할 수 있습니다. 이런 이유로 하나의 정답을 제공하는 두 번째 방식이 보편적으로 활용되고 있습니다.
문제는 수많은 후보군 중 하나의 최종 정답을 제공하는 질의 응답 시스템에서는 하나의 알고리즘으로 서로 다른 정답 유형을 처리하기가 쉽지 않다는 데 있습니다.
| 질의 | 마우스 발명자는 누구? | 컴퓨터가 뭐야? |
| 후보 정답 1 | 더글러스 엔젤바트 | 미리 정해진 방법에 따라 입력된 자료를 처리함으로써 문제를 해결하는 다양한 형태의 전자공학적 자동장치 |
| 후보 정답 2 | 더글러스 엥겔바트 | 반도체 집적 회로를 이용해 주어진 명령을 자동으로 맡아 실행하는 정보 처리기 |
| 후보 정답 3 | 더글라스 엥겔바트 | 프로그램을 이용해 정보를 처리하는 장치 |
| 후보 정답 4 | 더글라스 엥겔바트 | 전자 회로를 이용한 고속 자동 계산기 |
| 후보 정답 5 | 더글러스 엥겔바트 | 프로그램에 따라 작업이나 계산을 수행하는 기계 |
[표 2]에서 보듯이, “마우스 발명자는 누구”라는 질의에 따라 각 문서에서 추출한 후보군은 대부분 비슷한 문형2을 지니며 그 표현 범위 또한 다소 한정돼 있습니다. 그래서 그 후보를 압축하는 데 도움이 될만한 정답 사이 포함 관계나 날짜, 요일과 같은 규칙성에 따른 투표를 통해 최종 정답을 가려낼 수 있죠. 이를 단답형 정답이라고 부릅니다.
반면, “컴퓨터가 뭐야”라는 질의에 따라 각 문서에서 추출한 후보군은 다양한 문형을 지니며 그 표현 범위가 상당히 넓습니다. 후보 답변 사이 규칙성을 발견하기 어려워 앞서 설명한 투표 알고리즘을 사용하기가 어렵습니다. 그래서 각 정답 후보에서 추출한 중심어와 수식어에 따른 새로운 투표 알고리즘이 필요합니다. 이를 서술형 정답이라고 부릅니다.
이처럼 질의 응답 시스템에서는 정답의 유형에 따른 적절한 알고리즘이 동작해야 한다는 점에서 정답 유형 분류는 매우 중요하다고 할 수 있겠습니다.
정답 유형 분류가 어려운 이유
앞서 설명한 정답 유형 인식은 '단답형'과 '서술형'이라는 이진 분류 문제라고 볼 수 있습니다. 얼핏 봐서는 질문의 길이가 짧고 간단해 답변의 유형을 둘 중 하나로 분류하기가 매우 쉽다고 느껴질 수도 있습니다. 하지만 실제로는 질의의 형태만 봐서는 정답 유형을 구분하기가 거의 불가능합니다. 같은 문형을 가진 질문임에도 그 정답의 유형이 완전히 다름을 알 수 있는 예를 한 번 들어보겠습니다.
| 번호 | 질의 | 정답 유형 | 정답 |
| 1 | 경찰서 번호가 뭐야? | 단답형 | 112 |
| 2 | 원자 번호가 뭐야? | 서술형 | 주기율표에서 각 원소마다 주어진 원소 고유의 순번 |
[표 3]에서 1번과 2번 문장은 ‘~번호가 뭐야’라는 동일한 문형으로 종결됩니다. 1번은 ‘경찰서’라는 주제어의 하위 속성에 대한 질문입니다. 따라서 단답형으로 정답이 제공되어야 합니다. 원자 번호라는 주제어에 대한 정의를 질의하는 2번에서는 서술형 정답이 제공되어야 하죠.
특정 단어 시퀀스에 대한 정답 유형의 단답형 또는 서술형 확률을 구할 때에는 형태소3, 품사와 같은 정보를 고려합니다. 그런데 품사 정보는 문장을 두 범주 중 하나로 분류하는 데 크게 도움이 되지 않습니다. 즉, '번호가 뭐야'라는 동일한 문형을 가진 두 개의 문장에서 주제어의 형태소만 다른 상황에서는 해당 문장이 요구하는 정답이 단답형일 확률 또는 서술형일 확률이 서로 크게 다르지 않다는 의미입니다. 이런 이유로 단순한 키워드 나열이나 단문 형태를 취하는 질의 분석만으로는 예상 정답의 유형을 분류하기가 쉽지 않습니다.
질의 형태의 변형(경찰서 번호가 뭐야, 경찰서 번호 좀 알려줘봐)이나 입력 오류(경칠서 번호가 뭐야, 경찰서 반호가 뭐야) 등 수제 규칙이나 패턴에서 벗어난 질문에 대해서도 적절한 정답을 제공하지 못할 수도 있습니다. 질의를 제대로 분석하지 못해 정답 유형에 따른 적합한 알고리즘을 제대로 호출하지 못하게 되기 때문입니다. 이처럼 대다수의 서비스 이용자가 자신만의 스타일로 문장을 입력한다는 사실을 고려했을 때 패턴이나 규칙에서 벗어난 질의 문장 또한 제대로 분류할 수 있는 강건한 시스템이 필요합니다.
BERT 언어 모델을 사용하지 않는 이유
기존의 언어 모델에서는 순차 데이터(sequential data)를 다루기 용이한 RNN(recurrent neural network)4 구조에 주로 기반을 두었습니다. 하지만 이로 인해 병렬 처리(parallel processing)가 어려워 계산 속도가 느려지고, 입력 초기의 데이터를 잊어버리는 경향으로 인해 문장 길이가 길어질수록 성능도 떨어지게 됩니다. 어텐션(attention)5을 통해 위에 언급한 문제가 일정 부분 해소되기는 했으나, 그 단점을 완전히 극복하지는 못했습니다.
RNN의 한계를 넘어서고자 새롭게 고안된 Transformer6는 거리가 먼 단어 간 관계를 효과적으로 표현하는 셀프 어텐션(self-attention)7을 이용해 학습 시간은 줄이고, 학습 성능은 효과적으로 높였습니다. 이후에 나온 BERT, GPT2를 비롯한 현재 모든 SOTA(state-of-the-art, 현재 최고 수준의) 언어 모델은 바로 이 Transformer 구조에 기반을 둡니다. 문맥에 따라 변하는 단어의 의미를 표현하는 데 탁월한 최신의 이 언어 모델은 다양한 NLP 과제에서 기대 이상의 성능을 선보이고 있습니다.
하지만 이런 낙관론과는 달리, 실제 서비스 개발 현장에서는 속도 저하를 문제로 최신 언어 모델을 도입하는 사례가 많지 않습니다. 223GB의 한국어 문장을 가지고 CNN(convolutional neural networks)8 기반 모델과 BERT 기반 모델9의 성능을 비교한 실험이 이를 뒷받침합니다. 성능 차는 거의 없었으나 처리 속도는 수배 이상 차이 났기 때문입니다.
보통은 Eigen10을 이용해 디코더(decoder)를 구현하면 속도를 최적화할 수 있습니다. 다만 모델의 층수가 많아질수록 그 이점은 줄어듭니다. 그래서 BERT처럼 층이 많고 그 구조가 복잡한 모델에서는 서비스가 가능한 수준의 속도 최적화는 매우 어려운 편에 속합니다. 실제로 BERT 기반 모델은 서버 GPU를 사용하고도 한 문장을 분류하는 데에만 9.3280ms나 걸립니다. 반면, CNN 기반 모델에서는 CPU 싱글코어만으로도 한 문장 분류에 2ms밖에 걸리지 않았죠.
AI Lab은 비슷한 정확도를 가진 모델인데, 훨씬 값싸고 빠르게 사용할 수 있다면 공학적인 측면에서 마다할 이유가 없다고 판단, BERT 기반 언어 모델 대신 GloVe[3] 의미 벡터와 어절 임베딩 벡터를 CNN에 입력해 그 문맥을 학습할 수 있도록 했습니다[1]. CNN 기반 모델을 채택한 이유는 뒤에서 자세히 설명해드리겠습니다.
AI Lab이 정답 유형을 분류하는 방법
1. 전처리
한국어 어절11 하나는 두 개 이상의 형태소를 포함하는 경우가 많습니다. 이런 이유로 기존 한국어 관련 많은 연구에서는 한국어 형태소 분석기를 이용해 입력 문장을 형태소 단위로 나누는 데이터 전처리를 실시합니다. AI Lab 또한 규칙과 통계 기반으로 동작하는 자체 한국어 형태소 분석기12를 이용해 입력 문장에서 형태소와 품사 정보를 추출했습니다.
하지만 AI Lab은 형태소를 분석하는 것만으로는 오탈자 여부를 알기가 쉽지 않다고 판단했습니다. 사용자는 비슷하게 발음되는 두 단어를 혼동하거나, 키보드상에서 가까이 위치하는 키를 잘못 타이핑하거나, 단순히 띄어쓰기를 생략할 수도 있습니다. 대부분의 경우, 정상적인 표현에서 자음, 모음 한두 개가 다른 경우가 많습니다. 이에 AI Lab은 자음과 모음 추출기를 이용해 어절의 자모음 정보도 획득했습니다. 이 자모음 정보는 뒤에서 설명할 통합 어절 임베딩(행렬) 생성에 활용됩니다.
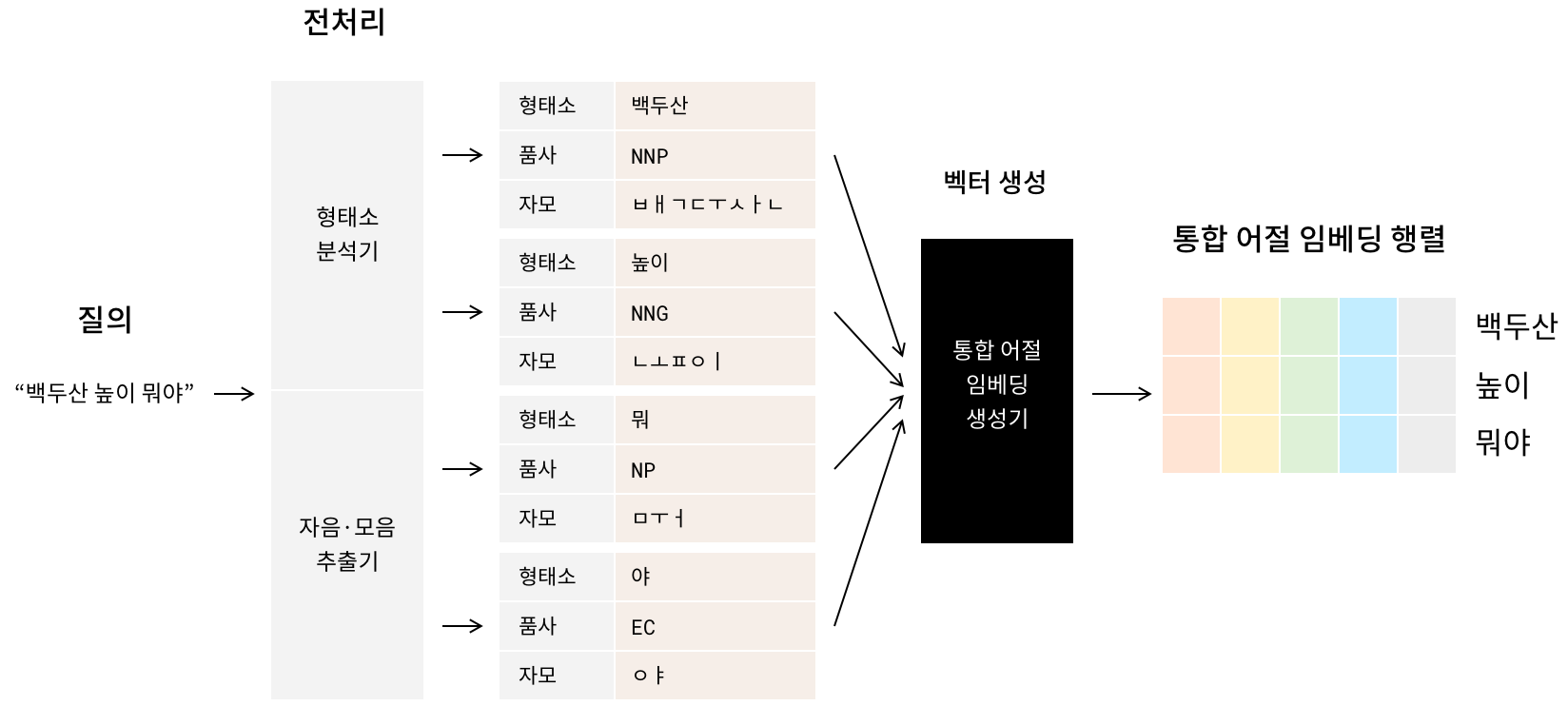
2. 통합 어절 임베딩 생성
자연어 어절을 벡터로 바꾸는 데에는 워드 임베딩(word embedding)을 사용합니다. 워드 임베딩은 대규모 말뭉치에 등장하는 단어의 일반적인 의미를 벡터로 표현합니다. 예를 들어, 의미가 비슷한 '인간'과 '사람'을 비슷한 방식으로 표현할 수 있습니다. 또 ‘왕-남자=왕비’와 같은 관계에서 보듯이 단어의 실제적 의미적 차이를 거리로 표현하는 것도 합니다. 대표적인 워드 임베딩 모델로 Word2Vec[2], GloVe, FastText[4]가 있습니다.
AI Lab은 여타 다른 임베딩 기법보다 단어의 의미를 더 잘 담아내는 GloVe 포함한, 입력 오류에 강건한 (자모) 통합 어절 임베딩 생성기를 구축했습니다. 형태소 어휘 사전에 존재하지 않은 오탈자로 인해(out of vocabulary) 형태소 분석 오차(noise)를 최소화하기 위함입니다. 통합 어절 임베딩 생성기는 형태소와 자모음 정보에 각각 부여한 임베딩 벡터를 이용해 다시 원래 어절을 조합하는 과정을 학습합니다. 그 결과, 입력 오류가 발생하더라도 원래 어절을 유사하게 추정할 수 있습니다.
AI Lab은 통합 어절 임베딩 생성기 훈련 과정에서 자모 드롭아웃(dropout)13과 띄어쓰기 없는 문장 생성이라는 두가지 데이터 노이즈(noise) 생성 기법을 추가했습니다. 기존 시스템 대비 오류가 포함된 문장을 분류하는 성능이 약 23%P 향상되는 등[1] 이 기법의 유효성은 AI Lab 자체 실험을 통해서도 증명이 됐습니다.
3. 문장 임베딩 벡터 생성
문장에 존재하는 각 어절을 표현하는 임베딩을 추출했다면, 이를 바탕으로 문맥까지 표현하는 임베딩 벡터를 생성할 차례입니다. 여기에는 CNN기반 모델이 활용됩니다.

(1) DenseNet
이미지 분류(classification)와 분할(segmentation), 객체 감지(detection)과 같은 비전 문제에서 탁월한 성능을 내는 CNN은 자연어처리 문제에도 효과적입니다. 컨볼루션 연산층(convolution layer)의 필터(filter)가 문맥 파악에 중요한 부분만 도출하는 데 유리한 덕분입니다. 그 결과, CNN을 통과한 최종 벡터는 문장의 지역 정보를 보존하는 추상화 과정을 거쳐 단어나 표현의 등장 순서를 반영한 문장의 의미 정보(semantic information)를 표현할 수 있게 됩니다.
AI Lab이 문장 분류를 위해 기본으로 사용한 DenseNet[5]은 CNN을 응용한 대표 알고리즘으로, 이전 층에서 생성된 특징 맵(feature map)14을 모두 이어붙여서(concatenation) 다음층에 입력합니다. 컨볼루션 층이 많아질수록 출력 층에서부터 계산된 기울기(gradient)가 전체 네트워크에 올바르게 전달되지 않는 기울기 소실(gradient vanishing)15 문제를 완화하는 이 로직이 자연어처리에서도 효과적인 방법이라고 AI Lab은 판단했습니다.
(2) 깊이별 분리 컨볼루션 연산(Depthwise separable convolution)
형태소와 자모 정보를 반영한 통합 어절 임베딩을 모델에 바로 입력하면 전체 학습 시간이 지나치게 길어지는 문제가 발생할 수 있습니다. 각 임베딩별로 컨볼루션 연산이 이뤄지다 보니 매개변수(parameter) 수가 늘어나는 만큼 처리 시간이 비례해서 늘어나기 때문입니다. 따라서 매개변수가 늘어나는 상황에 대비해 학습 속도나 추론 속도를 높일 필요가 있습니다.
이를 해결하고자 AI Lab은 깊이별 분리 컨볼루션 연산[6]을 이용합니다. 2D 이미지 데이터에 대한 깊이별 분리 컨볼루션은 매개변수 수 최적화를 통해 메모리 사용량은 줄이고 학습 속도를 높입니다. 채널을 기준으로 각각 [필터 높이, 필터 너비, 1]와 [1, 1, 채널 수]로 분리한 두 종류의 새로운 필터로 각각 깊이별 컨볼루션(Depthwise convolution)과 포인트별 컨볼루션(Pointwise convolution) 연산을 순차적으로 진행합니다.
이 연구에서 깊이별 컨볼루션은 어절 간 관계를 고려합니다. 주위 어절을 함께 고려한다는 측면에서 n-gram16 확률을 분류에 사용하는 것과 비슷하다고 보면 됩니다. 포인트별 컨볼루션은 유효 데이터만 추려내고자 전체 채널을 하나로 압축해 컨볼루션 연산을 진행합니다. 이렇게 하면 연산 속도를 높이는 데 도움이 됩니다.
300차원의 통합 어절 임베딩 벡터와 (300*3) 크기의 필터 256개를 이용한 컨볼루션 연산17이 있다고 가정하겠습니다. 일반적인 필터를 이용한 1회의 컨볼루션 연산에는 총 (입력 채널 수*필터 높이*필터 너비*출력 채널 수)개의 매개변수가 필요합니다. 여기서는 300*1*3*256=230,400개의 매개변수를 연산해야 하죠. 반면, 깊이별 분리 컨볼루션에서는 각각 300*1*3*1=900개와 300*1*1*256=76,800개의 매개변수가 필요합니다. 이를 합치면 총 77,700개로, 연산 효율이 33.7% 더 좋다는 사실을 확인해볼 수 있습니다.

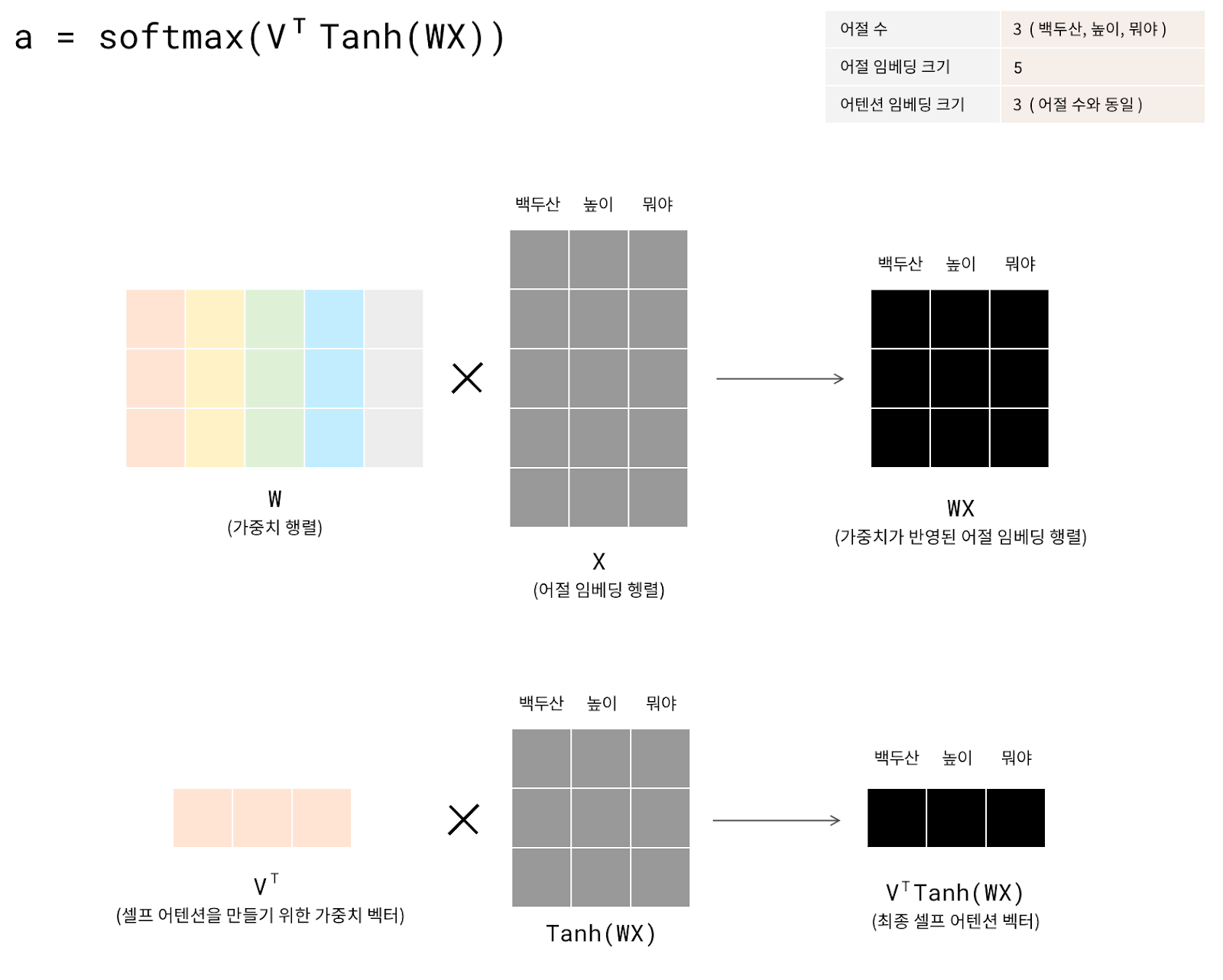
(3) 동적 셀프 어텐션(dynamic self-attention)
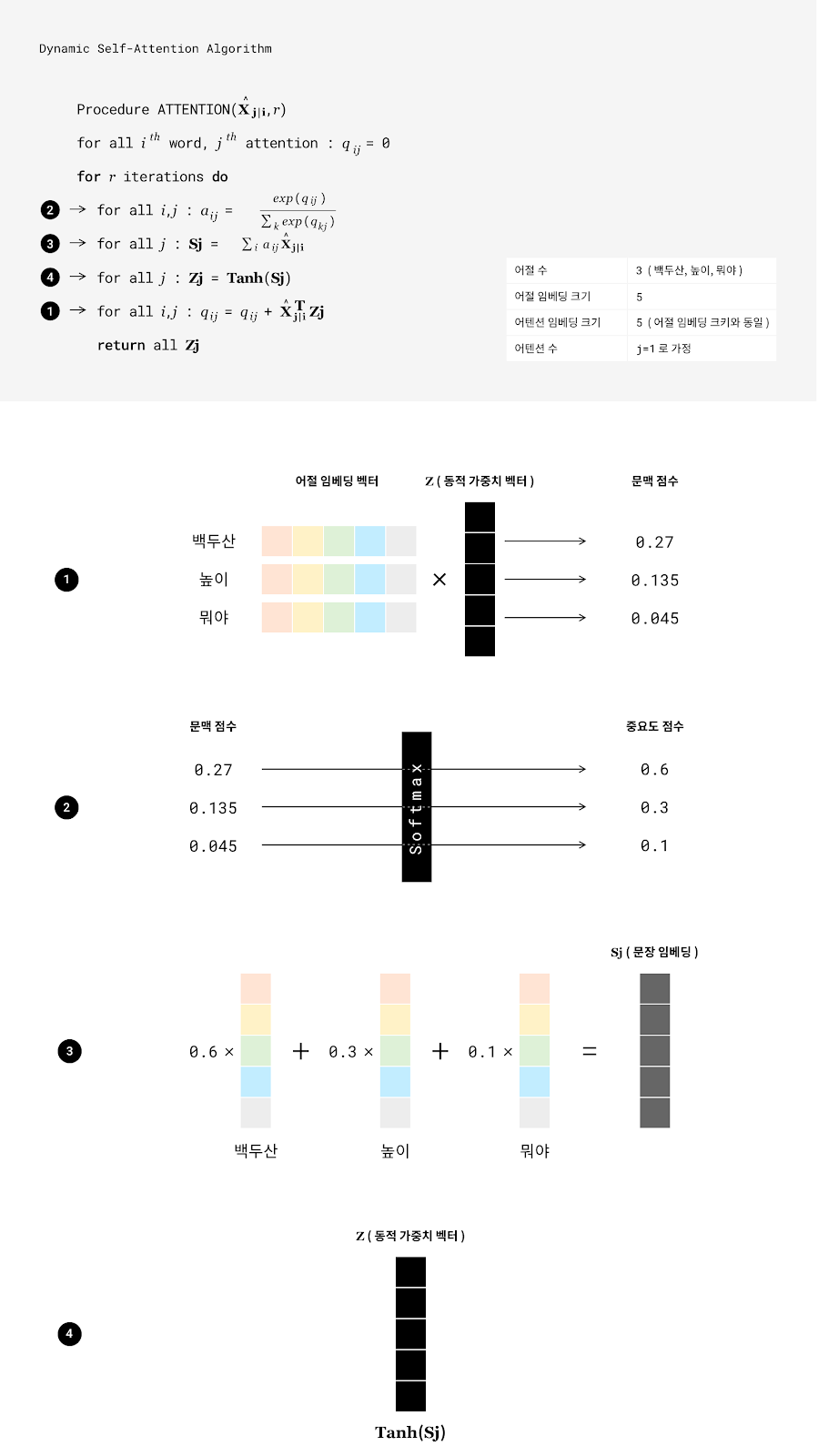
서로 연관성이 높으나 거리상 멀리 떨어진 어절이 서로 참조할 수 있게 하는 기법으로 어텐션이 있습니다. 다만 기존의 어텐션 기법은 입력 발화 길이에 제약이 없는 실제 서비스에 적합하지 않을 수가 있습니다. 어텐션 행렬의 형태가 어절 수에 제약을 받기 때문입니다. 이에 AI Lab은 입력 어절의 수에 관계없이 어텐션 벡터의 계산 및 관리 기법인 동적 셀프 어텐션[7]을 적용했습니다.
과정은 다음과 같습니다. 첫 번째, 각 어절 임베딩 벡터와 셀프 어텐션을 나타내는 동적 가중치 벡터(dynamic weight vector)를 곱해 각 어절의 문맥 점수를 구합니다. 두 번째, 각 문맥 점수에 대한 소프트맥스(softmax)18 연산을 거치면 중요도 점수(소프트맥스 확률값)를 얻게 됩니다. 세 번째, 어절 임베딩 벡터에 중요도 점수를 가중치로 두고 선형 결합(linear combination)합니다. 네 번째, 이 가중합의 결과는 다시 동적 가중치 벡터로 재정의됩니다. 이 과정을 거치면 어절 길이에 제약을 가진 가중치 행렬을 사용하지 않으면서도 현재 보는 어절과 관련성이 높은 다른 어절의 중요도도 반영할 수 있게 됩니다.
4. 분류
문장 임베딩 벡터는 마지막 출력층인 FFNN(Feed-forward neural network)과 소프트맥스 연산을 거쳐 사용자 질의문이 요구하는 답변 유형을 단답형 또는 서술형으로 분류합니다.
향후 계획
AI Lab은 예기치 않은 오분류 문장을 완전히 제어할 수 있어야 비로소 사용자에게 충분한 만족감을 선사하는 서비스를 제공할 수 있다고 보고 있습니다. 지금까지는 육하원칙, 개체명 인식기, 가젯티어19와 같은 추가 특징을 딥러닝 분류 모델에 적용했을 때 유의미한 성능 개선을 확인했습니다. 정답 유형 분류에 맞게 미세조정된(fine-tuning)된 BERT 모델을 전문가(teacher)로, CNN을 숙련자(student)로 설정하는 실험에서는 괄목할만한 성능 개선을 이뤘으며 현재 그 결과를 정리하고 있습니다. 이처럼 AI Lab은 정답 유형 분류기의 성능을 개선하기 위한 연구를 앞으로도 계속 진행할 계획입니다.
참고 문헌
[1] 한국어 챗봇에서의 오류에 강건한 한국어 문장 분류를 위한 어절 단위 임베딩 (2019) by 최동현, 박일남, 신명철, 김응균, 신동렬 in 제 31회 한글 및 한국어 정보처리 학술대회 논문집(pp. 43-48)
[2] Efficient Estimation of Word Representations in Vector Space (2013) by Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean in ICLR Workshop
[3] GloVe: Global Vectors for Word Representation by Jeffrey Pennington, Richard Socher, Christopher D. Manning, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP)
[4] Bag of Tricks for Efficient Text Classification by Armand Joulin, Edouard Grave, Piotr Bojanowski, Tomas Mikolov in arXiv
[5] Densely Connected Convolutional Networks (2017) by Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger in CVPR
[6] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (2017) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam in CVPR
[7] Dynamic Self-Attention: Computing Attention over Words Dynamically for Sentence Embedding (2018) by Deunsol Yoon, Dongbok Lee, SangKeun Lee in arXiv

이수경(samantha) | 작성, 편집
지난 2016년 3월 알파고와 이세돌 9단이 펼치는 세기의 대결을 취재한 것을 계기로 인공지능 세계에 큰 매력을 느꼈습니다. 카카오엔터프라이즈에서 인공지능을 제대로 알고 싶어하는 사람들을 위해 전문가와 함께 읽기 쉬운 콘텐츠를 쓰고 있습니다. 인공지능을 만드는 사람들의 이야기와 인공지능이 바꿀 미래 사회에 대한 글은 누구보다 쉽고, 재미있게 쓰는 사람이 되고자 합니다.

조승우(john) | 작성, 감수
친구들과 함께 빅데이터 감정 분석 프로젝트를 수행하며 자연어처리에 큰 흥미를 느낀 것을 계기로 학부 때는 데이터마이닝 연구실에서 빅데이터 관련 연구를, 석사 때는 기계번역과 문법 교정 관련 연구를 진행했습니다. 현재 카카오엔터프라이즈에서는 카카오 i 대화 엔진에 필요한 개체명을 인식하는 딥러닝 모델과 정답 유형 분류 딥러닝 모델 개발을 맡고 있습니다. 앞으로의 인공지능은 사람의 번거로운 일을 해소하는 데 영향력을 발휘했으면 좋겠습니다.

최동현(heuristic) | 감수
어느새 30대 중반으로 접어든, 그러나 마음만은 젊게 지내는 인공지능 개발자입니다. 2017년에 카카오로 이직하며 카카오미니 개발에 참여하게 되었습니다. 카카오미니에 기여를 할 수 있어서 매우 기쁘고 미니를 좀 더 똑똑하게 만들기 위하여 열심히 공부 중에 있습니다.

- 사용자의 발화를 인식해 적절한 서비스를 연결해주는 자연어처리기술 [본문으로]
- 문장을 구성하는 문장성분의 배열 유형 [본문으로]
- 뜻을 지니는 최소의 단위 [본문으로]
- N 단계에서의 값을 다시 입력값으로 사용해 N+1단계에서의 상태를 예측하는 재귀적(recursive)인 구조를 갖춘 신경망 [본문으로]
- 인코더-디코더 구조의 모델이 특정 시퀀스를 디코딩할 때 관련된 인코딩 결과값을 참조한다. [본문으로]
- 컨볼루션(convolution)이나 순환(recurrence) 기법 대신, 모든 단어가 현재 결과에 기여하는 정도를 반영할 수 있도록 각 입력 단어가 출력 상태에 연결하는 어텐션(attention) 신경망 구조를 활용한 seq2seq 모델이다. [본문으로]
- 현재 처리하는 단어와 연관성이 높은 단어를 참조하는 기법 [본문으로]
- 이미지의 공간 정보를 유지하면서 특징을 효과적으로 인식하고 강조하는 딥러닝 모델. 특징을 추출하는 영역은 컨볼루션 층과 풀링 층으로 구성된다. 컨볼루션 층은 필터를 사용해 공유 파라미터 수를 최소화하면서 이미지의 특징을 찾는다. 풀링 층은 특징을 강화하고 모은다. [본문으로]
- 형태소 분석기 대신 최신 단어 분절 알고리즘인 BPE를 사용했다. [본문으로]
- C++ 선형대수 연산 라이브러리 [본문으로]
- 문장 성분의 최소 단위. 띄어쓰기의 단위가 된다. [본문으로]
- AI lab은 뜻을 지니는 최소 단위인 형태소로 우선 안정적으로 분류 실험을 진행하고 나서, 서브워드(subword) 단위로 문장을 분절하는 최신 기법인 BPE를 활용한 연구도 진행하고 있다. [본문으로]
- 특정 자모가 포함된 임베딩 벡터값을 전부 0으로 변환하는 기법 [본문으로]
- 컨볼루션 연산으로 얻은 결과 [본문으로]
- 역전파 알고리즘에서는 낮은 층으로 갈수록 전파되는 오류(error)의 양이 적어진다. 이로 인해 미분값의 변화가 거의 없어져 학습이 제대로 일어나지 않는다. [본문으로]
- 어떤 한 입력을 처리할 때 N개의 입력 단위(토큰(token))를 함께 볼지를 결정한다. 이 글에서는 통합 어절 임베딩을 생성하기에 어절을 하나의 입력 단위로 취급한다. [본문으로]
- 패딩(padding)은 같게, 스트라이드(stride)는 1인 조건에서 컨볼루션 연산 20회를 수행한다. [본문으로]
- 다범주 분류기에서는 출력값을 제대로 해석하고자 다른 출력 노드와의 상대적인 크기를 비교한다. 이를 위해 각 출력 노드를 0~1 사이로 제한해 이를 합한 값을 1로 만든다. [본문으로]
- 사람이 관리하는 사전 정보로, 보통은 CRF 같은 알고리즘에서 기계학습 성능이 더 높게 나올 수 있도록 수치값을 조정해주는 역할을 맡고 있다. [본문으로]




댓글